URLs, URIs, and URNs
| Most any user of the Internet understands that you need to put a URL (Uniform Resource Locator) in the Address field of a browser to send a request to a Web server. However, the URL is only one of many URIs (Uniform Resource Identifiers ”although in the original HTTP RFC, URL was termed Universal Resource Identifier). You specify a URL by using the prefix http:// in the address space of your browser. However, other URIs ( identifiers ) can be used, such as ftp:// if you want to use a browser to download files from a remote server. The important thing to remember here is that URLs are just a subset of URIs, and there are many URIs. However, URLs are probably the most widely used URIs. RFC 1630, written by Berners-Lee, also discusses URNs (Uniform Resource Names ), which refer to a namespace that is more persistent than objects that refer to URLs. Although this definition is not considered to be a standard, Berners-Lee describes the URI syntax this way:
To provide for the extensible characteristic of the syntax, this RFC assumed that new URI prefixes ( http:// , ftp:// , and so on) can be an arbitrary string of characters, but also should be registered by some authority to ensure uniformity on the Web. The text that follows the prefixed URI designator is dependent on the prefix. For example, http:// would assume that a Web server address follows the prefix. For ftp:// , the text following this prefix should be in conformance with FTP conventions, in order to specify an address and file to be downloaded. This RFC also requires that a colon character ( : ) follow the prefix. The use of slashes ( // ) is used to indicate a hierarchy of some sort , such as a path through a naming convention that leads to the eventual location of information, or the object sought by the prefix.
Because some characters (such as the space character) can cause conflicts ( especially when URIs are used in email messages, and are so long that the text is wrapped), an escape character is used. The percent sign ( % ) is used as the escape character . This character should be used for only this purpose, and nothing else. Other characters, such as the hash character ( # ) and the question mark ( ? ), also serve a particular purpose. The # character is used to separate the object of a URI from an identifier related to the specific URI. The ? character is used to separate the URI from an object that can be queried. In other words, the ? means that the text that follows it is used to pass data to a query based on the original object that is referenced by the URI. You will see this character appear in many URLs when you reference a Web site. This character is used in many URLs after you enter text (in a search engine, for example) to create the final URL that is used to apply the syntax of your query to the object you referenced in the URL that you entered. You can try this by visiting just about any major Web site, such as Microsoft, or a search engine. Watch the Address field on your browser and you will see a longer string of what appears to be a meaningless string of characters. It is, however, the syntax that the search engine (or other Web site) uses to apply your query to find the information you are looking for.
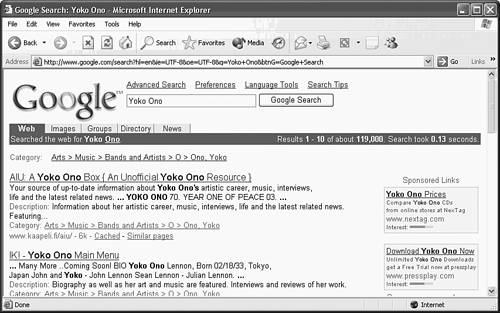
Other reserved characters, which can be used by any URI and which apply to the syntax of those URIs, are the asterisk ( * ) character and the exclamation mark ( ! ). In other words, these characters do not mean the same thing for all URIs. Each URI can use these characters for a meaning specific to the particular URI. If this sounds confusing, just go to a search engine and look at the string of characters that follows your query. In Figure 36.1 you can see that entering the URL www.google.com brings up the initial query page for this search engine. Figure 36.1. You can enter a URL to bring up a particular Web page, such as a search engine. Yet when you enter text into this search engine's Search field, and click on the Search button, the URL in the Address field of your browser is translated to a query that the search engine uses to locate resources related to your query, as shown in Figure 36.2. Figure 36.2. Your query can change after you enter text in a search engine. In Figure 36.2, notice the long string that was created by the search engine to satisfy your search request. Also notice that the Web site for Yoko Ono is the first result to show up. This Web site is the premier site for all information related to Yoko Ono, and is the first Web site to show up on the search engine.
The RFC goes on to explain URIs for specific applications, such as gopher, news, and mail. Some of these have been superceded by other RFCs. However, RFC 1630 should serve as a beginning document for those readers who want to study the details of URIs and URLs. URIs and URLs are also discussed in other RFCs than those discussed in this chapter. However, URLs are the most common when you consider the intense growth of the Web. There are even "hidden" URLs that don't appear until you click on an embedded link in a Web page. Each link (or hyperlink in some RFCs) in a Web page that refers to another Web page simply provides, using HTML syntax, another URL request that will be sent to the server defined in that link. |
EAN: 2147483647
Pages: 434