Section 09. Chi-Square
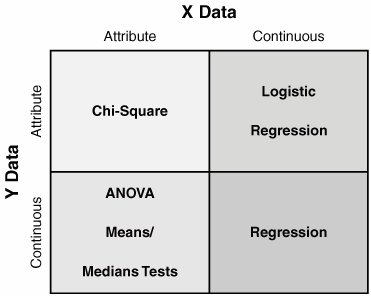
09. Chi-SquareOverviewChi-square is one of the statistical tools in the Multi-Vari approach and is both the simplest and least powerful. Chi-square helps determine the statistical significance of a relationship between an Attribute X and an Attribute Y in Y = f(X1,X2,..., Xn). The approach used is to assume the variables are independent and set up the hypotheses as follows:
The output of the test is a "p-value" that indicates the likelihood of seeing a relationship this strong in a sample purely by random chance; that is, there is no relationship at the population level, it just happened by fluke in selecting the sample from the population. As in most statistical tests, if the p-value is less than 0.05, then the null hypothesis Ho should be rejected. In English, if the p is less than 0.05, then the likelihood of seeing a relationship this strong is less than 5%, and, therefore, there is a good chance that it is real; if p is greater than 0.05 then the conclusion should be that there is no relationship. As with any statistical test, Chi-square comes with its set of "could be" and "might be" statements. For example if the Personnel Department wants to see if there is a link between age and whether an applicant is hired, then both Age (old and young) and Got Hired (did or didn't) are attribute type data. A Chi-Square test would be applicable to answer the questions:
The hypotheses would be
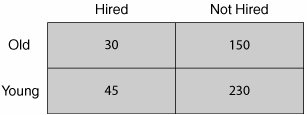
As with all statistical tests, a sample of reality is required, similar to that shown in Table 7.09.1 where about 455 data points were taken and the data distributed amongst the four possible outcomes. The data can then be analyzed in a statistical package, such as JMP or Minitab. The software calculates the expected values in each box, and compares the observed with the expected frequencies to produce a signal-to-noise type ratio (how far the observed is from the expected) using Where O is the observed frequency and E is the expected frequency in a box. Table 7.09.1. Sample of Reality for the Relationship between Age and Hiring The software then looks up the χ2 (the sum of all the discrepancies) value in a statistical table to discover the likelihood of seeing a difference that big.[14] As a Belt using the tool practically, all that is important, after the data has been captured using robust data collection methods, is the output of the tool, which should be similar to that shown in Figure 7.09.1.
The first place to look is the p-value, which in this case p = 0.932. In this instance, the p-value is not low (not below 0.05); thus, the conclusion should be that the relationship between Age and Hiring Practice is not significant for the sample of data taken. Chi-Square can be applied in virtually any transactional processes where attribute data usually abounds. For example:
RoadmapThe roadmap to setting up and applying a Chi-Square test is as follows:
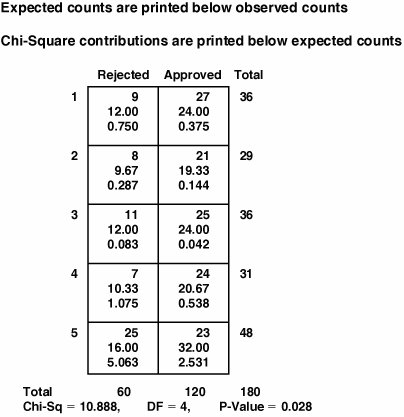
Interpreting the OutputThe first place to look during analysis is to the p-value. If the p-value is higher than 0.05 then the conclusion is that the X and Y are not dependent based on the sample of reality taken (similar to the Age versus Hiring Practice example in "Overview" in this section). However, if the p-value is low (less than 0.05) then there is reason to believe that the X and Y are dependent in some way and the distribution of data points within the table isn't as expected if everything was based on random chance. To demonstrate this, consider the data in Table 7.09.2, which represents loan approval or rejection decisions on different days of the week. The bank in question clearly would like loan decisions to be independent of the day the loan was processed.
The results of the Chi-Square Test analysis are shown in Figure 7.09.2. Figure 7.09.2. Chi-Square Test analysis results for loan data (output from Minitab v14). Looking immediately to the p-value of 0.028 (less than 0.05), it is clear that the likelihood of seeing a distribution of data in the boxes like this purely by random chance, given that there was no relationship, is slim. Thus, the conclusion is that the null hypothesis should be rejected and the alternate "Data are dependent" should be accepted instead. In English, we conclude there is something fishy going on, because the chances of getting a loan varies by day of the week. To understand how this is manifested, the next step is to look to the contingency table in the analysis output as shown in Figure 7.09.2. To read this table, the numbers 1 to 5 down the left side represent the days Monday to Friday. The first number in each box is the observed data; that is how the decisions were actually made. The second number in each box is what would be expected if the decision were independent of the day. The final number is the Chi-Square statistic for the difference of the Observed versus the Expected values; the larger the number, the bigger the signal that is present. Looking at the table it is clear that Friday has the larger deviation from expected, and this is contributing most of the Chi-Square total (5.063 + 2.531 out of 10.888). Looking at the observed versus expected values in the Friday row shows for Rejection an expected of 16 and an observed of 25; it seems on Friday a significant number of people get rejected more than we would expect. The next steps would be to
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
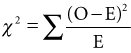
EAN: 2147483647
Pages: 138