Exploring the System.Data Namespace
| Now that we're finished our initial tour of the SqlClient namespace, we're ready to move on to the .NET Framework classes used to manage in-memory datathe System.Data namespace. This namespace contains the base classes used to store and manipulate the data returned from queries or generated through whatever means you devise. Basically, the System.Data classes implement a lightweight in-memory database populated by a data source provider like SqlClient. The System.Data namespace currently supports a number of data munging operations so you can filter, sort, find, and inter-relate data. These classes also expose interfaces to permit bound controls to display the data and post changes to it, as well as fire events as the data is loaded or validated, or its state changes. When coupled with the data provider classes I've already discussed in this chapter, the System.Data classes can feed data back into the SqlDataAdapter Update method so changes and new rows can be posted back to the database. Deciphering System.Data Naming ConventionsThe Class Diagram in Figure 8.15 lays out the System.Data namespaceat least, the parts you'll use most of the time. It shows how the objects and containers are related. You'll observe that the DataSet object is used as the container for all of the other (related) objects, such as collections of Table, Relation, Constraint, Row, Column, and Property objects. Unfortunately, the .NET Framework naming convention and hierarchies shown by the Object Browser is not particularly consistent. While there are DataColumn objects in the Columns collection, and DataRow objects in the Rows collection, you might expect the Constraints collection to hold objects named "DataConstraints" to follow the symmetrythey're not. Instead, the Constraints collection contains Constraint objects, which is understandable. However, what about the PropertyCollection and ExtendedProperties? I suppose that these objects were created by Microsoft groups working in different buildings (or countries). Figure 8.15. The System.Data namespace showing the DataSet and DataTable objects.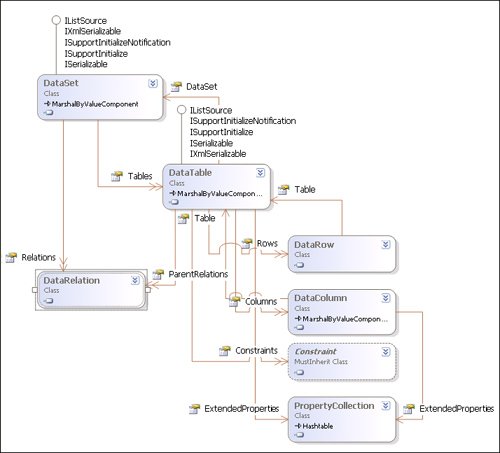 I'm also not thrilled with the choice of a few of these object names. Yes, I like the fact that Microsoft decided on DataColumn instead of "DataField", but why call a set of rows (a rowset) a DataTable? Since a DataTable shouldn't (necessarily) map to an entire database table, but to a subset of database table rows returned by a SELECT, IMHO, it should have been called a "Rowset" object and stored in the "Rowsets" collection. IMHO Don't be confused by the names. Just keep in mind that you should not simply fill a DataTable with the contents of your database table just because it's called a DataTable objectnot if you expect to create an application that performs and scales well. The next section walks you through these System.Data namespace objects and highlights basic and new ADO.NET 2.0 functionalityjust like I did for the SqlClient objects. Understanding the System.Data.DataSet and DataTable ObjectsI'm not sure it makes sense to discuss the DataSet object before you get a better understanding of what it containsbut I have to start somewhere. The DataSet is basically a container for the Relations, Tables, and ExtendedProperties object collections (exposed as properties), which, in turn, contain Relation, DataTable, Row, Column, and Property objects. As I said, the DataSet forms the foundation for ADO.NET's disconnect in-memory data architecture. This approach was initially implemented (at least, in part) in COM-based ADO classic by the "disconnected" Recordset. The disconnected ADO.NET DataTable class can be seen as simply an extension of the Recordset conceptalbeit, fairly different in content, approach, and usage methodology. Okay, they're not at all alike, except that they both hold data rows. However, instead of implementing a single stand-alone object that holds both schema and data, the DataSet object is designed to hold (virtually) any number of DataTable objects and (optionally) connect them relationally or informally on the client using Relation objects. A DataSet can address one or more rowsets in DataTable objects, define relationships between the DataTable rowsets (regardless of their source), sort, filter, and find and save changes to the data. You can also bind to DataSet objects and the DataTable objects they contain. This architecture is implemented such that the data residing in the DataTable objects stored in the DataSet can come from anywhereso you can "relate" data from two or more totally random data sources, if that's necessary. For example, a single DataSet can contain a DataTable object from the Customers database, another from the AccountsPayable database, and another from lower Manhattan. Your code can define relationships between these DataTable objects despite the fact they are not formally related in their respective databases. Of course, you might need their parent's permission if they are underage. As I've said, the SqlDataAdapter can populate a DataSet, and, given the right configuration, the Update method can post changes to one of the underlying database tablesthat is, you can choose only one of the DataTable objects to update with the DataAdapter. The DataSet object can be serialized to either XML or binary (in 2.0), so it can be transported from place to place and reconstituted wherever needed. Changes made to the DataSet can also be exposed as an XML "DiffGram," in case you need to send the updates to space aliens or people in the government who understand data only if it's spelled out very simply. Populating a DataSet with DataTable ObjectsThis section provides a quick look at several techniques to populate a DataSet with DataTable objects. Chapter 11 discusses these techniques (and others), including how to populate the DataSet and DataTable objects with schema and data from a variety of data sources. Once I focus on solving specific problems in the later chapters, you'll be in a better position to know which technique to use and which makes the most sense in your particular situation.
In case you can't tell, I try to use techniques that are not code-intensivethey're cheaper to develop and support and easier to learn (and teach). Actually, the amount of code the Fill and Load methods execute behind the scenes is about the same as the code you would write to perform the same functions, but it's written and debugged by the Microsoft minions, and you don't have to support it, figure out why it's not working, or hope that it is. No, this does not mean I'm a staunch fan of the drag-and-drop approaches to constructing DataSet objects, as these code-generators can lead to other issues that can waste your timeI'll get to that approach later in this chapter. That said, Visual Studiogenerated code is all well and good for many situations, but not nearly all. There will come a time when you're going to want to solve problems that the automated code generators just can't handle. I'll show you how along the way. A DataSet data and schema (or both) can be populated in a number of ways, but they're most easily created by calling the SqlDataAdapter Fill method, as described earlier, or the new Load methods that I describe later in this section and explore in depth in Chapter 11. By "population," I mean the process of configuring the DataTable Columns collection with the schema (which defines the column names, datatypes, sizes, and other properties) and filling the Rows collection with a rowset. This can be done by hard-coding the methods and properties, but this makes your code brittlesubject to fail if the underlying schema changes or if some newbie does not understand the code. This is another argument for use of the feature-rich Fill and Load methods. Among the techniques you can call on to populate a DataTable are:
Consider that if the Fill method is used against "empty" (unpopulated) DataTable objects, ADO.NET creates one or more new DataTable objects, populates the Columns collection, and fills in the Rows collection with data. But what happens when the target DataTable object(s) already contain data? The Fill method has to deal with this situation in several scenarios, so you'll need to provide some guidance as to how ADO.NET should deal with existing data. I'll discuss this issue and many others in Chapter 11.
A feature that you might not expect if you're accustomed to working with ADO classic Recordset objects is the ability to define a DataSet and modify it post-open. That is, even after you populate a DataSet by whatever means, you can still add, change, rename, remove, or reposition the Columns collection. This makes it easy to add special "computed" or expression columns to your DataSetwhich makes it even easier to show these special columns in your bound controls. What's a DataRow and a DataColumn?When it comes time to store data with ADO.NET, you or ADO.NET clone a new DataRow by calling the NewRow method on the DataTable. This method generates a new, empty row that you subsequently populate with data. This row is not part of the DataTable until you use the Rows collection Add method. A DataRow is stored as a set of object-type arrays unless you get Visual Studio to create a strongly typed DataRow. No, data is not stored behind the scenes in XML, despite what some might say. A new DataTable can also be constructed in code. This gives you the ability to create client-side data structures of your own design. Creating a DataTable is simply a matter of instantiating a new DataTable object and populating the Columns collection. Since online help is a bit skimpy in this area, I've included an example that walks through that process. First, the DataTable needs a DataColumn that defines the primary keyan Identity column. Sure, ADO.NET knows how to manage client-side identity values just like SQL Server. The example in Figure 8.16 illustrates doing just that. Selecting a valid DataType is really pretty easyif you use this syntax. Intellisense pops up to list valid datatypesat least, in Visual Basic. Figure 8.16. Creating a new DataColumn to act as the DataTable object's primary key. Note that I added the newly created (and configured) DataColumn to the DataTable Columns collection using the Add method. This example also illustrates how to use the AutoIncrement property. In this case, I enable AutoIncrement and set the step to 1. This way, when a row is added to the DataTable, a new Identity value is created. I also set the Unique property to True to ensure that no duplicate rows are added to the table. The next step is to add the detail columns to the DataTable. In this case, I created an array of DataColumn objects and used the AddRange method to add them to the DataTable Columns collection. The example shown in Figure 8.17 illustrates how this is done. Figure 8.17. Creating and configuring the detail columns for the DataTable. Each column is given a unique name as the array is populated. No, ADO.NET won't complain about duplicates until you execute AddRange. Each DataColumn is assigned a datatype, but the data is stored as an Objectas I've discussed before. The datatypes are used to ensure that the values assigned to the column's row value conform to the type constraintsinteger size, range, and so forth. Each type has its own constraints, which I'm sure you know by now. Of course, as I've discussed before, setting a datatype does not make the data pure, as far as business rules are concernedbut at least the data is type-safe. Note that as you create DataColumn objects, you have the opportunity to set ancillary properties, such as:
Once the array of DataColumn objects is populated, you can use the AddRange method to add it to the DataTable Columns collection. Now is when you'll throw exceptions if there is something wrong with the expressions, you have duplicate column names, or other issues arise. I usually test my newly created DataTable objects by simply binding them to a DataGridView. This way, I can test the expression handler and see how the other columns are handled. Drilling into the DataRow ObjectThe DataRow object is used to hold the value for each of the columns defined in the DataColumn collection. That's a big difference from the ADOc Recordset, which stores both schema (column definitions) and data values in the same structure. In ADO.NET, most of the schema is maintained in a separate DataColumnCollection (addressed by the DataTable Columns property), and the data is stored in a separate DataRowCollection (addressed by the DataTable Rows property). Each DataRow object holds the "current" value for each column, as well as the "original" and "proposed" values. All of these values can be referenced by addressing the Item property for each columnif they exist. As you create new instances of the DataRow and set the value, or fetch a row from the database and change the value, the original value and proposed values are managed separately, so you can "undo" change made to the row. When we get to Chapter 11, on populating the DataTable, and Chapter 12, on updating, you'll see how you can return and reset these "versions" of the column value. Note that, by default, the DataRow value is stored as an object type, even though you define a datatype for the DataColumn. I discuss strongly typed DataSet objects and type safety later in this chapter.
No, don't go looking for a "Value" property on the DataRowit's not there. The DataRow value is stored in the Item or the ItemArray properties. As you create and modify the DataRow, each instance is tagged with a RowState property that's used to indicate its "state".
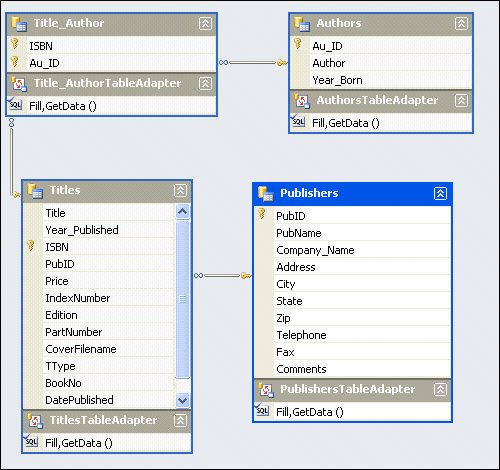
As you can see, the RowState property is very important, as it determines whether or not the DataAdapter Update method executes one of the DML action commands or simply steps over the row as it searches for changes to post to SQL Server. Since a DataTable object's rows can be "updated" by repopulating from another rowset, you should carefully consider how this is done. Perhaps you wish to preserve client-side changes already made to the DataTable Rows collection or simply overlay them. I explore how to manage these values and other DataTable population issues in Chapter 11. Before long, you're going to want to set the RowState property yourself instead of using the "approved" methods to do so. To make this easier (and possible), ADO.NET 2.0 exposes two new methods (SetAdded and SetModified) on the DataRow class to support changes (albeit limited) to the RowState propertyassuming the current RowState is Unchanged. If the current RowState property is not Unchanged or Added, an InvalidOperation exception is thrown. While this seems somewhat limited in usefulness, when I get to Chapter 12, I'll show other ways to set or reset the RowState property. I'll also show ways to "undelete" rows or simply remove rows from the Rows collection where their changes can't be posted to the database. Visual Studio and Code GenerationA dramatic difference between Visual Basic 6.0 and Visual Studio .NET is the fact that Visual Studio no longer depends on "black-box" routines to implement its behind-the-scenes work. Instead, Visual Studio now generates and integrates this code into your projects to construct the interfaces it needs to perform a litany of operations. This can make your projects seem far more complex. Thankfully, Visual Studio 2005 has moved most of this generated code to partial classes that are (initially) hidden. Sure, it's more than the ADO.NET code that's tucked in behind the curtains. As you add components to your Windows Form or ASP page, Visual Studio generates the code needed to generate and configure these objects at runtime. This code is placed in separate files in your project. Part of the magic here is accomplished by using "partial" classes. New for the 2.0 versions of Visual Studio languages, this construct permits a class to be defined in any number of separate files. This way, Visual Studio can more easily generate classes that you, the developer, should be able to see (and modify), and other classes that you should not see (or modify). When it comes time to regenerate code (as when you use a wizard or change one of the diagram-based code generators), Visual Studio knows that it can alter any code in the partial classes that it has generated. It should not change any adjunct additions you have made to these classes. Using Strongly Typed DataSetsAs you should have already surmised, by default, DataTable objects generated by the Fill and Load method are "weakly typed" data structures because they store and return "objects" (untyped data)not strongly typed data elements like integers, strings, or dates. This means that the CLR language has to add considerable code to address specific data values buried deep in the object hierarchy. Figure 8.18 illustrates two techniques to address a row value from a DataTable in a recent test. To give you a feel for the performance difference, consider that the first addressing technique (which appears in countless examples) takes about 2,500 ticks. In contrast, by simply replacing the string DataTable and Item referencing with enumerations (or integers), the same operation takes only 350 ticks. To put this in perspective, using strongly typed DataSet referencing takes about 150 ticks to perform the same operation. The point? Well, you can gain most of the performance benefits of a strongly typed DataSet by using enumerations. This technique is demonstrated again later in this chapter and throughout the book as more sophisticated examples are built. Why doesn't Microsoft use enumerations in their code generation (and examples) instead of late binding? You'll have to ask them, but I suspect it's because they think that enumerations are frail, in that they have to be independently maintained. That's very true, but if the tools helped.... Figure 8.18. Moving a row value to a TextBox using untyped data referencing. In subsequent chapters, I'll show how to use Visual Studio to build strongly typed DataSet objects, but before I go there, keep in mind that there has been an ongoing debate about whether it makes sense to create strongly typed DataSet objects. On one hand, strongly typed DataSet objects perform faster than their untyped equivalents, but as was just illustrated, you can recover most of the performance benefit by using enumerations. However, the process of creating a strongly typed DataSet is labor-intensive and still fairly brittle. That is, suppose you invest some time to build a strongly typed DataSet using the Visual Studio wizards. Behind the scenes, more than several hundred lines of complex code can be generated for a single strongly typed DataSet class. Yes, it's possible to safely tune this code, as long as you do so in your own segment of the partial class that defines the strongly typed DataSet. However, if the schema used to define the strongly typed DataSet changes, as it often does, Visual Studio 2005 overlays the previous definition with the new class. Your code in the partial class remains, but it might not match the Visual Studiogenerated strongly typed class. Introducing the TableAdapterAs with earlier versions of Visual Studio, the 2005 version generates a tremendous amount of code to expose strongly typed DataSet objects. To this end, Visual Studio creates customized DataSet, TableAdapter, DataTable, and DataRow objects using wizards, prompted dialogs, graphical designers, and drag-and-drop techniques. This generated code inherits from the System.Data and SqlClient base classes, extending the functionality. In a TableAdapter, individual data columns are defined as strongly typed and referenced by column name. In addition, Visual Studio 2005 permits you to define relationships for the DataTable objects so you no longer have to hard-code these relationships. The schema definition for your strongly typed DataSet is stored in an XSD (XML) file that can be used to manually alter the schema or feed the DataSet Designer, as shown in Figure 8.19. Figure 8.19. The DataSet Designer showing four related tables from the Biblio database. To create this relationship diagram (and the code behind it), I simply created a project Data Source that pointed to the Biblio database and four tables that I knew were related. Visual Studio did the rest. Once the code was generated, I right-clicked on the generated Data Source and chose "View in Designer". Note that the relationships between the tables have been discovered and incorporated into the graphic display. In addition, each DataTable includes a custom "Fill, GetData()" item that can be customized to alter the initial SELECTas when you wish to define a custom query to incorporate a parameter-based query or a stored procedure. You can also add as many of these items as you needthey are exposed as methods on the strongly typed TableAdapter generated behind the scenes. If you recall, I focused Chapter 6 on generating strongly typed DataSet objects, including the TableAdapter. The advantages of this approach include:
Figure 8.20. Binding the TableAdapter to a DataGridView using drag-and-drop. However, to be clear, strongly typed DataSet objects are brittle. If the underlying schema changes, you usually have to go back to Visual Studio to alter the generated code. Yes, this means going through the wizards again and repeating the drag-and-drop operation used to initially generate the codeunless you dig into the XSD file, make your changes there, and get Visual Studio to regenerate the code. Then again, there are those who would counsel that if the schema changes, you'll still have to revisit the code. I agree, but the tools don't really help identify what parts have changed until you regenerate the TableAdapterthen you have to track down all of the compile errors. Perhaps that's an advantage. The DataSet and DataTable Behind the ScenesThe ADO.NET base-class DataSet is designed around ADO.NET's "disconnected" architecture. It's designed to store and help manage data in separate DataTable objects without requiring a persistent connection to the data source(s) used to populate it. While it might (just might) be necessary to connect to a database or other data source to populate the DataSet Tables collection, once the rowsets have been moved to the DataTable (a process called rowset population), the connection can be (and probably should be) closed. At this point, the DataSet can be sorted or filtered (via a DataView), subsets of rows can be selected via property settings, new DataTable objects can be generated, additional DataTable objects can be incorporated, and the entire DataTable can be serialized to another tier. Serialization is an important feature of the DataSet and (now in 2.0) the DataTable objects. It permits data to be extruded (serialized) in XML or binary (in 2.0) so it can be transported to another application, layer, or tier, or persisted to a file. As I've said before, DataTable data is stored in binary arrays, one for each column in the DataTable. Sure, the DataSet can be populated by importing XML into its base DataTable objects using the ReadXml method, and it can extrude XML using the WriteXml method. You can populate a DataSet schema from XML with the InferXmlSchema and ReadXmlSchema. However, it's unwise to equate XML with performance. While XML is extremely flexible, it's also very (very) verbosekinda like listening to some senator drone on and on about his pet project when the same information could be communicated in a few words. XML data structures are, by their very nature, heavy consumers of RAM, CPU, and I/O resources, as they must be "compiled" into intelligent data on each access. No, they should not be used where you don't need "universal" or extremely flexible data access paradigms. A DataSet is capable of storing a large number of rowseven millions of rowssubject to the RAM constraints of your system and the sanity of the design. While storing even thousands of rows does not make sense for most applications, I understand that there are situations where it's necessary (albeit imprudent) to store that much information in memory. In this regard, ADO.NET 2.0 has dramatically improved performance when seeking, serializing, and editing data within giant DataSet objects. This can make it easier to implement "challenged" designs. Unlike the ADO classic Recordset, the DataSet is designed to manage several rowsets at once and manage them individually in DataTable objects. This means you can build a DataSet from one or several data sources, add relationships between the DataTable objects, and perform a number of powerful parent/child operations. For example, you can populate a DataTable with rows from the Customers table and another containing customer orders. By adding a DataRelation that specifies the primary and foreign keys, your code can inform ADO.NET that these two tables are related and should be treated as such. This means you'll be able to fetch related orders for selected customers or find the customer for a given order. Yes, the relationships can be defined several layers deeprelating customers with orders with items and so on.
While earlier versions of ADO.NET forced you to define these relationships in code, the Visual Studio 2005 IDE now supports functionality to build the XSD (and XML structure) for you that includes these relationships. It can also generate the code to expose these hierarchical data structures as strongly typed DataSet objects. I discuss these IDE features and how they fit into an overall development plan in Chapter 6. A single DataSet object's DataTable changes can also be posted to the database when managed by a DataAdapter or TableAdapter objects. By defining the T-SQL commands to perform the UPDATE, INSERT, and DELETE operations (what's called DML[8] or action commands), you can program ADO.NET to pass these parameterized commands to SQL Server to post client-side changes to the database. Yes, Visual Studio can help create these action commands if they aren't too complex. I discuss update techniques, the CommandBuilder, and associated issues in Chapter 12.
Exposing Data with the DataView ClassOne of the most powerful (and useful) properties of a DataTable is DefaultView. This property returns a DataView object that's rich with functions, methods, and properties of its own. Since the DataView extends the properties of a DataTable, you'll find the DataView useful to sort, filter, and find rows in a variety of ways. Note that the DataView is simply thata "view" on the target DataTable. Changes made to the DataView rows are applied to the DataTable. Typically, once a DataTable is created, you can bind to the DataView. This way, when you change the properties of the DataView, the rows viewed in the bound control change as well. For example, changing the RowFilter property shows only rows based on the specified filter (such as "City = 'Redmond'"); only rows where the City column contains "Redmond" are displayed in the bound control. The most interesting of the functions, properties, and events exposed on the DataView include:
To JOIN or Not to JOINThat's The QuestionOne final point I would like to make before I move on. Ever since ADO.NET appeared, developers have asked one important question: "Should I fetch individual tables into a DataSet object and add the relations (or use Visual Studio to do it), or should I execute queries on the server that join the tables into a combined JOIN product and try to manage it in a single DataTable?" Unfortunately, the answer is not simple, so I need to spend some time discussing the issues so you can make an intelligent choice. When you choose to return multiple rowsets into separate DataTable objects, you can subsequently set up DataRelation objects to handle the relationships between the DataTable objects. As I've shown you, if you set up a Data Source and TableAdapter, Visual Studio builds these relationships for you. When it comes time to update the data, you'll have to set up a specific set of SqlCommand objects for each DataTable you intend to changeno, I don't expect that all of the rowsets you fetch will necessarily need to be updated on the server. Again, with Visual Studio 2005, the TableAdapter is built and programmed to include basic DML commands to post changes to the database. These updates must follow a specific sequence to maintain the parent/child relationship constraints. That is, you'll have to add new and change existing parent rows first, followed by adds, changes, and deletes to child rows, followed by deletes to parent rows. I detail this approach in Chapter 12. However, it might not work at all with a de-normalized table or a schema with a unique parent-child hierarchy. The problem with this approach is that folks tend to return too many rows to populate these DataTable objectsoften entire database tables. They then wonder why the performance is so poor. If your code focuses the rowsets from the task at hand and not the entire population of New Zealand, you should be able to get away with this approach. This approach can also be used with multiple stored procedure callseach returning one or more rowsets that are mapped to individual DataTable objects. However, in this case, you won't be able to use the SqlCommandBuilder or Visual Studio's tools to generate the DML queries to change the data. In most cases, you'll have already created stored procedures to perform these operations anyway, so this should not be an issue. When you choose to perform a server-side JOIN and return a combined product as a rowset, you're taking advantage of the indexes, query engine, and processing power of SQL Server (that you paid for). This approach is most common with those DBMS rigs that are built on a stored procedure foundation. In reality, when you build a DBMS around stored procedures, it's unusual to grant access to base tables, as all database I/O is done through protected stored procedures. Yes, you can set up DataRelation objects on these DataTables, and you get all of the benefits of this approach as if the rowsets were drawn directly from database tables. However, since the rowsets are composite products from several database tables, this approach might not make much sense. Updating these DataTable objects will also be more difficult, as you'll have to determine where the data came from in the first place. However, you can simply leave that up to your stored procedures. As your DBMS gets more sophisticated, being able to perform targeted table updates (as supported by the drag-and-drop code generation) is increasingly rare. The update procedures are often complex sets of logic that change not one, but several related tables and perform far more operations than ADO.NET can handle on its owneven with your help. Let's defer further discussion of update strategies until Chapter 12. |
EAN: 2147483647
Pages: 227