The Holmes Model of Tool Integration
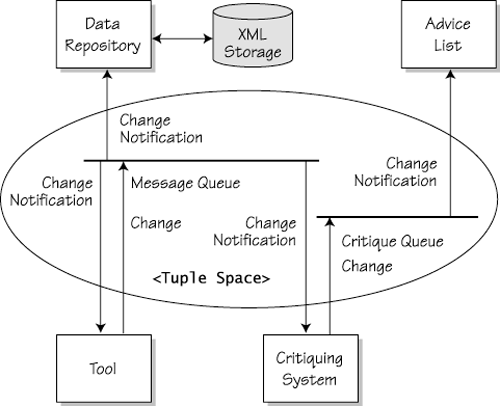
Holmes ArchitectureHolmes is built on a mixture of blackboard and implicit invocation architecture using a Linda tuple space [Gelernter1985], as implemented by Sun's JavaSpaces [Freeman+1999]. A tuple space is a form of virtual, shared, associative memory that generatively provides a repository for tuples. One of its features is that an entity that is put in the tuple space continues to reside there as long as some other process does not take it from the space. The existence of an entity in the tuple space is completely decoupled from the existence of the process that created that entity and put it into the space. Therefore, a tuple space can be used as persistent storage that holds data to be exchanged among processes whose execution should not be constrained to overlap in time. Another advantage of using a tuple space is that it provides an easy way to synchronize a number of processes that try to manipulate a set of shared objects. In that case, a process is given a random object among those that meet the criteria of the process. After the object is processed, it can be put back in the tuple space or disposed of, depending on the need. In addition to time decoupling, a tuple space also provides space decoupling. In the JavaSpaces implementation, this is realized by using the Jini distributed technology. Every process that wants to access a JavaSpace uses the same uniform way of connecting to it, independent of whether the JavaSpace is executed on the same machine or somewhere else over a network. Altogether, JavaSpaces supports the loose tool-to-framework integration that Holmes requires. Furthermore, the access method to any entity stored in JavaSpaces eliminates most of the difficulties usually associated with multiple users accessing a common resource. Certainly, such a method is not acceptable for any time-critical application, but strict timing is not an issue in our case. The different tools incorporated in Holmes communicate using an algorithm similar to message-based communication (see Figure 41.3). In the proposed implementation, there are a few improvements over standard message passing. As mentioned earlier, the use of JavaSpaces waives the difficulty of properly initializing the communication channels between tools after they are started. JavaSpaces stores messages for as long as specified, including infinity. Other improvements are that the messages exchanged among the tools are objects, not data; a message queue implemented in Holmes is not susceptible to the number of tools that "subscribe" to the data posted on that queue. Figure 41.3. Holmes architecture
The advantage of using messages as objects and not simple data is that an object encapsulates certain functionalities. Thus, the tools that communicate through objects are decoupled from the format of the data stored in the object, which actually represents a message. This flexibility is essential when dealing with diverse third-party tools, which use different output formats. Implementing messages as objects turns them into functional units that perform the communication protocol. That way, changes made to the communication protocol leave the tools intact. The opportunity of using object-oriented design patterns, such as Adaptor, Visitor, and Strategy [Gamma+1995], leaves space for broad future evolution of the behavior offered by object-based messages. Even though there are no clearly defined communication channels for exchanging messages among tools, the objects that represent these messages are organized into conceptual queues. These queues group messages belonging to semantically related data. A tool subscribes to queues that represent a flow of data the tool is interested in. A tool can act as either information provider or information subscriber. The way to enable that is to instantiate an object of type "writer" or "reader," respectively. All readers of a certain queue monitor JavaSpaces for specific types of messages. The order in which the readers subscribe to a queue is unrelated to the order in which they will actually read a message. In fact, that order is unpredictable and varies from message to message. Nevertheless, the sequence in which messages are posted to the queue is preserved when they are read. (For example, if message M1 is posted to a given queue before message M2, M1 will be read by a given reader before M2.) Tools that act as information subscribers are not aware and do not depend on the type of tools that act as information providers, as long as they post messages that conform to the agreed interface. The framework integrates the tools loosely in terms of time, type, and space. This implies a possible loss of performance, compared with structures supporting individual and clearly identified message channels among the tools. Persistent Storage in HolmesHolmes stores its data persistently through a number of tools, which are called repositories. Every repository stores semantically related information, just as queues group messages belonging to semantically related information. When a tool is started, all the other tools interested in the particular type of information provided by such a tool post a request for that information. If the repository responsible for that information is started and has activated its reader, it will notice the request, as will all other tools that monitor the queue, and will reply, posting the required data. Similarly, when a tool makes a change to a certain piece of data, it posts the change on the queue. This gives all other tools, including the repository tool, a chance to update their copies as well. When the Holmes application is terminated, only the data contained in the repository tools is saved to persistent storage. This way of storing data ensures that the repositories could hardly become a bottleneck in the system. The data, or parts of it, is distributed and duplicated among the tools that manipulate it. As explained, the use of JavaSpaces and objects as messages supports concurrent execution of multiple threads and polymorphic behavior on behalf of the tools. Holmes data is stored using the Holmes Markup Language (HML), which is essentially XML [OMG1998; W3C1998] with a custom Document Type Declaration (DTD). The advantage of an XML-based format is that the data can be viewed in human-readable form by using a text or XML viewer. This maintains independence of the data from the particular tool that manipulates it. The human-readable structure also provides the capability of building DTD translators to convert from HML to other XML-based languages. Although it does not completely eliminate the need to build adapters (in this case, DTD translators), the effort is somewhat standardized and reduced. Obviously, the advantages of this approach rely on the growing popularity of XML as a data format, especially for product data management systems [Gould2000] and UML CASE tools. |
EAN: 2147483647
Pages: 445