Leveraging the XML Technology Family
| | |
Team-Fly  |
 | XML, Web Services, and the Data Revolution By Frank P. Coyle |
| Table of Contents | |
| Chapter 2. The XML Technology Family |
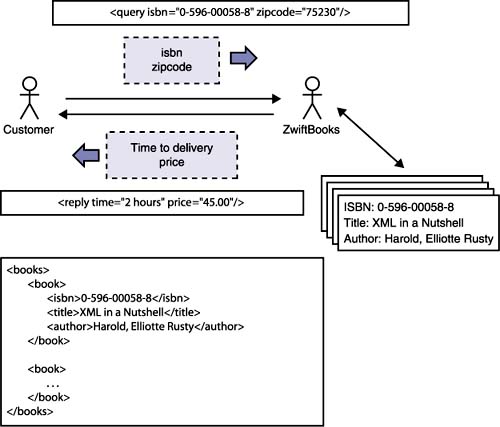
In the following section we explore aspects of the different XML technologies from the perspective of a fictitious company called ZwiftBooks. ZwiftBooks is a company that has decided to build its business around XML, not unlike many companies today that are trying to leverage XML and its various supporting technologies. ZwiftBooks' business is rapid book delivery. Its customers are people who just have to get their hands on a particular book, often within a matter of hours. ZwiftBooks fills this need by offering a local number that customers can call and get a guaranteed price and maximum waiting time for a book based on the customer's zip code. ZwiftBooks maintains a warehouse of in-demand books and does business in a city heavily populated with pager-carrying cyclists and skateboarders who are happy to earn extra money by zooming around town delivering books. When an order for a book comes in, the operator at the telephone desk sends out a paging message for all available riders to call in and report their locations. The operator uses rider location to determine estimated pickup and delivery times and gives the job to the closest rider . Within minutes the customer is given a price and a guaranteed delivery time. If the customer agrees, the closest delivery person is given the go-ahead and another ZwiftBooks customer is soon handed the vital book. As we follow Zwiftbooks in its effort to XML-ize its operations, sometimes we'll find immediate applications for a new technology; at other times we won't, especially if the technology has not ripened into a W3C Recommendation, an indication of stability in the world of open standards. But even if a supporting technology is still under development, it can be useful to consider whether the expected capabilities of the technology fit in any way with corporate strategic objectives and vision. If a technology is promising , ZwiftBooks should at least begin to think about how it might utilize it once it is formalized or ZwiftBooks is ready to adopt it. What's important for ZwiftBooks to keep in mind is that, as it steps into the XML world, the XML family's ability to combine technologies results in being able to get to market more quickly with applications that simply plug into new technology capabilities. This is not to say that development is without cost, only that using capabilities and features of supporting technologies designed to plug into an XML foundation can reduce both cost and risk. In the following sections we'll look at several XML technologies to determine if any can contribute to ZwiftBooks' objective to take its business global. It's not the intent here to provide a tutorial on XML syntax and structure, but rather to give a broad overview of the technology in the context of a business application. Those looking for more detail about XML can consult Appendix A or one of the references listed at the end of this chapter. XML 1.0For a company like ZwiftBooks, deciding on an XML representation for their data is a first step. In trying to come up with an XML data vocabulary that may be useful in automating operations, it's helpful to examine use cases that describe what occurs during a business interaction. Figure 2.2 illustrates the essence of a ZwiftBooks customer request and response. Figure 2.2. A ZwiftBooks business scenario and some XML representations.
Let's look at three different simple XML definitions: one for a customer request, one for the ZwiftBooks response to that request, and a third that illustrates an XML vocabulary for structuring the book data maintained by ZwiftBooks. It should be noted that these examples of XML are created more with an eye toward explaining how ZwiftBooks might use XML technologies rather than as a final take on ZwiftBooks' commercial distribution system, which of course would involve additional data elements and definitions. Let's begin with the customer query. <query isbn="0-596-00058-8" zipcode="75230"/> Technically this represents an XML element called query with the data represented as the value of the two attributes isbn and zipcode . Because we are packing all the information into this one element, we've elected to write this element using an "empty" element tag ending with a slash. Empty element tags stand alone and are generally used when only attributes are specified and there is no element or subelement content. The reply element is similarly defined, using attributes to hold the data. <reply time="2 hours" price="45.00"/> To maintain information about ZwiftBooks' inventory, we create a hierarchy of elements. <books> <book> <isbn>0-596-00058-8</isbn> <title>XML in a Nutshell</title> <author>Harold, Elliotte Rusty</author> </book> <book> </book> ... </book> </books> This XML structure differs from the query and reply elements in that the data is stored as the content of individual isbn , title , and author elements. Another difference is that the books and book elements do not have content but instead are used to contain other elements. It is this hierarchy or tree structure, implicit in all XML documents, that is processed and understood by the many XML-based tools available today. Using these XML definitions as a starting point, let's move on and explore how other XML technologies can fit into ZwiftBooks' effort to bring its manual operation into the Internet age.
XML Namespaces
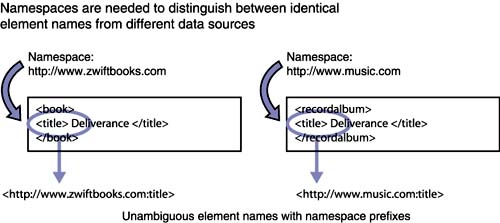
Having at least begun to define some ZwiftBooks XML data, we learn from a bit of research on the Internet that several other companies also use the tag name query , but they use it to describe requests for types of information other than data about books. The potential problem this creates is confusion when ZwiftBooks' XML is merged with XML from other sources. An XML processor will not be able to distinguish between a ZwiftBooks query and another company's query . Similar problems can arise with the ZwiftBooks definitions for reply and book . The solution to this potential confusion in working with XML from different sources is what XML namespaces is all about.
XML namespaces is a simple technology solution that allows ZwiftBooks' element and attribute names to be distinguished from the similarly named elements and attributes of other XML users. Figure 2.3 illustrates how a namespace may be used to disambiguate duplicate element names. XML namespaces solves the problem of clashing names by providing for a unique prefix to be attached to the beginning of element and attribute names. In practice, a company's Web address is often used as the unique prefix, but technically the namespaces specification allows any Uniform Resource Identifier (URI) to be used. URIs are more general than the common Uniform Resource Locator (URL) and include just about any unique name one wants to use. The usual result, though, is that when namespaces are used in an XML document, the official element name is actually a two-part name: the name of the XML namespace plus the name of the element or attribute. Figure 2.3. The XML namespaces Recommendation allows identical element names from different sources to be distinguished.
For ZwiftBooks, the namespace selection was easy: We use the address of the planned company Web site, www.zwiftbooks.com, as the namespace prefix to uniquely distinguish ZwiftBooks' XML from that of other companies. An important point to realize about this decision to use a future Web site as the namespace identifier is that XML namespaces makes no assumptions about the existence of a Web site for any URI used as the unique namespace prefix. This is something that often causes confusion when people first look at namespaces. The use of a URL such as http://www.zwiftbooks.com says nothing about the existence or nonexistence of the Web site. As it turns out, many URLs used as namespace identifiers do exist on the Web and often have links to DTDs or other information that pertains to their company's XML initiatives, but there is nothing in the namespace specification that requires an actual site to exist. Namespace DeclarationsThere are several ways to add a namespace to an XML document so that, when software is processing XML data from ZwiftBooks, it will see ZwiftBooks elements as http://www.zwiftbooks.com:title instead of just title . The simplest approach is to declare a namespace in a top-level element and let all the elements and attributes under the top element come under the scope of the namespace. For example, the following XML document adds a ZwiftBooks namespace to an XML book description document. <book xmlns="http://www.zwiftbooks.com"> <isbn>0-596-00058-8</isbn> <title>XML in a Nutshell</title> <author>Harold, Elliotte Rusty</author> </book> In this example, the namespace declaration is applied to the book element by adding the predefined attribute xmlns and giving as its value the unique URL of ZwiftBooks, http://www.zwiftbooks.com. Because the xmlns attribute appears in the book element, all subelements ( isbn , title , and author ) are included in the namespace.
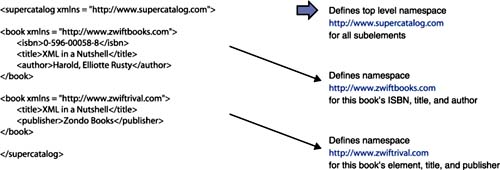
But what happens if the namespace declaration appears at some element other than the root element of the document? As you might expect, the namespace applies only to the element where it is declared and all its child elements. This ability to specify namespaces based on element hierarchies allows multiple namespaces to be used in the same document, which is why namespace is around after all: to help XML processors distinguish elements that have the same name but come from different sources. Figure 2.4 illustrates the use of multiple namespaces within the same document and how namespaces are useful in distinguishing which elements are which. In this example, the top-level element, supercatalog , is in its own namespace. Its two book subelements, technically within the scope of the supercatalog namespace declaration, define their own namespaces, so that we end up with three namespaces within the XML. Figure 2.4. An XML document with multiple namespaces. Namespace Abbreviations
The namespaces specification also makes it possible to use abbreviations for namespaces in order to make XML documents more readable. Figure 2.5 shows how we can define a shortcut name, zbooks , so that anywhere that zbooks appears in a document, a software program processing the document will replace it with the actual namespace, http://www.zwiftbooks.com . Figure 2.5. An XML document using a namespace abbreviation. The ZwiftBooks data shown in Figure 2.4 is identical in meaning to the XML in Figure 2.5. There are several issues to be aware of when using the shortcut abbreviation. One is that you may use whatever shortcut name you like within an XML document, and an XML processor reading the document will replace whatever shortcut you use with the URI namespace. Another point is that, if you declare you will use a shortcut by including xmlns:shortcut ="some URI" , then everywhere the shortcut is not used in an element name, the assumption is that the element is not part of the namespace. |

| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 106