Types of Indexes
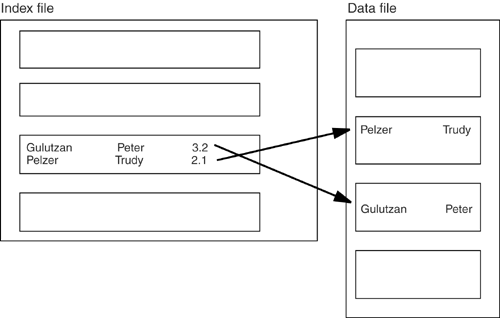
| In this section, we'll talk about the various kinds of indexescompound indexes, covering indexes, unique indexes, clustered indexesyou might encounter, and how you can take advantage of them. Compound IndexesA compound index is an index whose keys contain values derived from more than one data column. The terms compound index, composite index , and multicolumn index all mean the same thing and are equally valid. Each of the Big Eight support compound indexes. Figure 9-7 shows some keys from an index that is based on two columns : surname and given_name . Notice that the keys are in order by the left-most column ( surname ) so a search on given_name alone will not be advantageous. Figure 9-7. An extract from a compound index Similarly, a telephone book may contain both a surname and a given name , but we would be foolish to look for Peter or Trudy in a phone book. It follows then, that a compound index is good when you want to search for, or sort by (a) the left-most column or (b) the left-most column and any of the other column(s)and under no other circumstance. Why would you want to make a compound index instead of making two indexesone on surname and the other on given_name and letting the DBMS merge the results? That is, why don't we have this scenario:
Apparently this method is so obvious that people simply assume that it will happen. In fact it normally doesn't [3] . What really happens at step 4 is that, instead of reading the second index, the DBMS reads each of the data rows {7 , 35 , 102 , 448 , 930} . Each time it reads a row, the DBMS looks at the value in the given_name column to see if it is willy .
The error of thinking that the DBMS will take the sensible route and make full use of all indexes available for the query is probably what leads to the phenomenon of "over indexing" (making indexes for every column that appears in queries). Over indexing is useless. Most DBMSs pick only one index as a driver. The way to make use of an index on a second column is to put that column in a compound index. In that case, the DBMS takes this approach:
The general recommendations that apply for all DBMSs, then, are:
And one more recommendation that applies to an obsolete DBMS but does no harm now:
Covering IndexesSuppose you have a compound index (we'll call it Index_name_sex ) on Table1 's columns (name , sex) . You execute this SQL statement: SELECT sex FROM Table1 WHERE name = 'SAM' When you do so, the DBMS will use index_name_sex for the search because name is the left-most column in the index key. But once it has found the key {SAM , M} , the DBMS says, "Whoa, there's no need to get the data row," because sex is right there in the key. So the DBMS is able to return M directly from the index. When, as in this case, everything in the select list is also in the index that will be used, the index is called a covering index . Ordinarily, using a covering index will save one disk read (GAIN: 6/8). The gain is automatic but only if the columns in the select list exactly match the columns in the covering index. You lose the gain if you select functions or literals, or if you put the column names in a different order. Affairs get even better if you can persuade the DBMS to use a covering index regardless of whether it's searching for anything. For example, suppose you search Table1 without a WHERE clause, as in: SELECT name FROM Table1 ORDER BY name Will the DBMS do the "smart" thing and scan the covering index, instead of scanning the table and then sorting? Answer: Sometimes. But Cloudscape won't use covering indexes unless it needs them for the WHERE clause anyway, and Oracle won't use an index if the result might involve NULLs. So there's a gain if you assume that NULL names don't matter and you change the search to: SELECT name FROM Table1 WHERE name > '' ORDER BY name GAIN: 7/8 Even if you don't care about either selecting or ordering, a gain might still be achieved using a covering index. If the rows in the table are large, and the index keys are small, then it stands to reason that a scan of the entire index will be quicker than a scan of all the rows in the table. For example, if you want to list the sex column, don't use Query #1. Use Query #2 instead. Query #1: SELECT sex FROM Table1 /* this causes a table scan */ Query #2: SELECT name, sex FROM Table1 /* this causes an index scan */ GAIN: 2/8 By using Query #2 even though you don't care about name , you speed up the search by selecting an unnecessary column. In this example, you're really using the index, not as a tool to enhance access to the table, but as a substitute for the table. Thus it's a cheap way to get some vertical partitioning. The benefits of " treating the index as a table" are often significant, provided you keep a few sobering facts in mind:
Unique IndexesRecall that index selectivity is calculated as follows: Selectivity can be less than one if NULLs are indexed, or it can be less than one if duplicate keys are allowed. When selectivity equals one, you have perfect selectivityand a unique index . The name is misleadingit's not the index that's unique; it's the keys in the index that are unique. But nobody's confused about the main thing: Unique indexes are good, and optimizers love 'em. Here's some good reasons to make your indexes unique:
So, when the keys really are unique, should you always make the index with CREATE UNIQUE INDEX instead of just CREATE INDEX? Yeswith two exceptions. The first exception is that you don't want to create an index at all if the DBMS will create one automatically due to a UNIQUE or PRIMARY KEY clause in the table constraints. Most DBMSs will make unique indexes automatically to enforce constraints, so you don't have to. Table 9-2 shows which DBMSs automatically create indexes when you define a constraint and whether redundant index creations are blocked. The second exception is that you don't want to enforce uniqueness if the database is in an early stage and not all values are known yet. You might think that you could just do this: INSERT INTO Table1 (unique_column) VALUES (NULL) Butsurprise!IBM, Informix, Microsoft, and Sybase won't let you have two NULL keys in a unique index, while Ingres and InterBase won't accept any NULLs at all (see Table 10-1 in Chapter 10, "Constraints"). Get used to it: Portable programs can't use both NULLs and unique indexes. Notes on Table 9-2:
Table 9-2. DBMSs and Auto-Creation of Indexes
Unique indexes can cause optimizer confusion. Here's a way to confuse a simple optimizer:
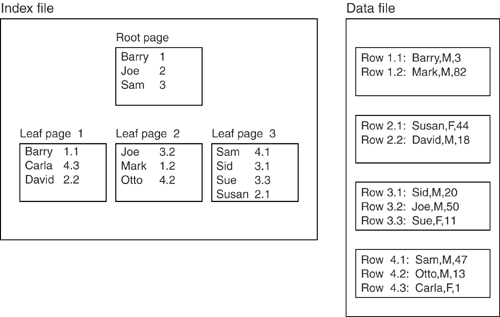
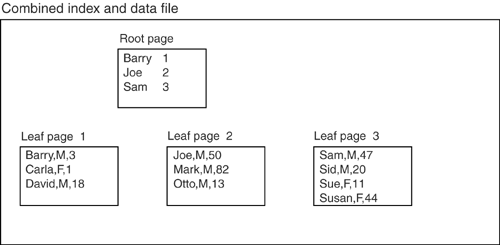
See the problem? Because sex is associated with a unique index, Index1 will be chosen as the driver even though Index2 is doubtless more selective. Luckily, none of the Big Eight are so stupidprovided they're in cost-based rather than rule-based modeand none of the world's database programmers are so stupid either because they know and follow this maximWhen defining a compound index, put the most selective key on the left. Clustered IndexesClustered indexes have been around since SQL was in its cradle, and six of the Big EightIBM, Informix, Ingres, Microsoft, Oracle, and Sybasesupport them. There are two varieties, which we will call by the nonstandard names "weak" and "strong." In both varieties, the objective of clustering is to store data rows near one another if they have similar values. For example, suppose you have a one-column tablecall it Table1 that has these values in column1 : 'Jones' 'Smith' 'Jones' 'Abbot' 'Smith' 'Jones' This is disorganized. If the rows could be reorganized so that this was the order: 'Abbot' 'Jones' 'Jones' 'Jones' 'Smith' 'Smith' then there would be a better chance that all 'Jones' rows are on the same page. If all 'Jones' rows are on the same page, this query is faster because there are fewer pages to fetch: SELECT * FROM Table1 WHERE column1 = 'Jones' This query is also faster, because of presorting: SELECT * FROM Table1 ORDER BY column1 In a cluster, data rows are lined up the way we want them for a range search, an ORDER BY or a GROUP BY. Not only is this good for selections, it also reduces the number of "hot spots"a potential problem that we'll discuss in Chapter 15, "Locks." Clustering speeds up queries even if rows aren't 100% in order. Provided that there is any ordering, queries will be faster on averageprovided that the cluster key ( column1 in our earlier example) is important. The DBMS can use a clustered index to find out what the row order should be (an index is a handy structure for the purpose because indexes are ordered). You just have to tell the DBMS that you want a clustered index and that you want column1 to be the cluster key. There can, of course, be only one clustered index per table because the data rows can only be sorted in one order. In contrast, when a table has only a nonclustered index, pages and data rows are not stored in an order based on the index key, but rather in a heaplike the pile of papers on an untidy person's desk. Usually a new row is just dumped wherever it can fit in the filethat's why it's called a heap. The difference between a weak-clustered index and a strong-clustered index is the fierceness with which the DBMS maintains cluster-key order. Most DBMSs have weak-clustered indexes, and they only guarantee to make a good-faith attempt to maintain order. Two of the Big EightMicrosoft and Sybasehave strong-clustered indexes, and they maintain order forcibly , even when this requires a lot of reorganizing of both index keys and data rows. (Oracle has both weak-clustered indexes and index-organized tables; index-organized tables are in fact strong-clustered indexes, but Oracle doesn't call them that.) Because their effect is major, we will examine strong-clustered indexes more closely. Strong-clustered indexesThe concept is simple: The leaf level of a strong-clustered index doesn't contain mere index keys. Instead, the leaf level contains the data rows themselves . Figure 9-8 and Figure 9-9 illustrate this by showing a conventional "data heap and separate" structure (Figure 9-8) and a radical "clustered index with integrated data" structure (Figure 9-9) containing the same data. Figure 9-8. A heap-and-index structure Figure 9-9. A clustered index The pointer from an index key to a data row is called a row locator . The structure of the row locator depends on whether the data pages are stored in a heap or are clustered. For a heap, a row locator is a pointer to the row. For a table with a strong-clustered index, the row locator is the cluster key. Strong clustering certainly looks like a winning idea. Assume you have two tables based on Figure 9-8 and Figure 9-9 and execute this query on each: SELECT * ... WHERE column1 = 'SUSAN' Which query is faster? Well, the DBMS will need three I/Os if it has a heap (two I/Os to scan the index and one more to get the data row)but only two I/Os if it has a cluster (two I/Os to scan the index and zero needed to get the data row). It doesn't really matter even if the data rows in the leaf page are likely to be twice as big as the index keys, becauseremember the earlier talk about the number of layers being the important criterion?doubling the key size doesn't double the access time. This advantage appears for strong-clustered indexes only. With either a weak- or a strong-clustered index, data rows are in order. But the fact that the expression WHERE column1 = 'SUSAN' works with one less I/O is an additional effect that appears only with strong-clustered indexes. To sum it up, both varieties of clustered indexes are good for GROUP BY, ORDER BY, and WHERE clauses. Strong clusters are also good for long keys (because a strong-clustered index on a long key takes no extra space for the leaf level). An extra benefit if the DBMS is Microsoft is automatic garbage collection (Microsoft doesn't have automatic garbage collection for ordinary heap tables). INSERTs are harder with strong clusters because you have to make room between existing rows to fit in the new value according to cluster key order. But two subsequent INSERTs probably won't go to the same place, so clusters reduce contention . UPDATEs are harder with strong clusters because any change in the cluster key means the row order can change too. But you are less dependent on ROWID with clusters; access using the cluster key is almost as quick. There is no question that any changes that affect the cluster key will be huge and slow, because when the key value changes, the whole row must move in order to stay in order. However, there is a simple remedy: Never update the cluster key. In fact, under the hood, there is no such thing as an UPDATE of a cluster keythe DBMS translates such an UPDATE to a DELETE followed by an INSERT. Choice of clustered keyThe conventional advice is that you should have a clustered index for almost any table that's not tiny or temporary. This means you have to pick a set of columns for the cluster keyand it better be a good pick, because it is extremely inconvenient to change the cluster key after the table is full of data. By definition, there can only be one cluster key because the rows can only have one order. So what columns should form the cluster key? Good news. Many have asked that question before, and a body of sage counsel can guide the picking. Unfortunately, there's also bad newspriorities differ depending on whether the DBMS has strong or weak clustering. When clustered indexes are strong, the primary key can be the cluster key. This saves time and confusion, and is often the default behavior, so we'll just defer this piece of sage counsel to Chapter 10, "Constraints." In situations where the primary key isn't there or isn't an obvious choice for a cluster key, you should explicitly state that the primary key is nonclustered. Then choose a cluster key with these characteristics:
However, when clustered indexes are weak, the rule "the primary key can be the cluster key" is weak too. Here are two rules for choosing the cluster key for a weak-clustered index, especially popular among IBM experts:
Beware, though, if the possible cluster key is a monotonically sequential, or serial keyfor example, an integer whose values always go up and always go up by the same amount, when you INSERT. The problem with monotonics (which are sometimes hidden behind names like "identity" or "timestamp" columnssee Chapter 7, "Columns") is that the nth row and the (n + 1)th row will both fit in the same pageso there might be contention for the same resource. Usually, in multiuser systems, you want rows to be dispersed. This above allThe benefits of clustered indexing depend on a monster assumption; namely, that you want to retrieve and sort by the cluster key far, far more often than with any other key. Secondary indexes to a strong-clustered indexConsider this scenario. You've defined Table1 with a strong-clustered indexthe cluster key is column1 and inserted the following data:
Now you want to add a secondary indexa nonclustered index on column2 . Here's the problem. Because each row of the table is in an index leaf page, it can move within the page whenever another row is inserted or deleted above it, and it can even move to a different page if there's an index split. If that happens, the column2 pointers are useless because the pointer part of an index key (aka row locator or bookmark ) is normally a row identifier (aka ROWID or RID). Recall from Chapter 5, "Joins," that a row identifier is a physical address, such as {File number, Page number, Row number within page} . But the physical address of the row can changeso a ROWID is unreliable. One solution to this problemthe old Oracle8 solutionis to disallow the creation of any nonclustered indexes to a strong-clustered table. [4] This has the unfortunate effect of limiting the usefulness of strong-clustered indexes, and in fact they're rarer in Oracle shops than in Microsoft shops . You can write your own schemes for doing "manual joins," and so on, but that's no fun.
Another solutionthe Microsoft solutionis to make the row locator be the cluster key. That way, when the DBMS looks up column2 , it ends up with the cluster key value that uniquely identifies the row: the value of column1 . For example, suppose you ask for information about Fiona : SELECT * FROM Table1 WHERE column2 = 'Fiona' Now the DBMS can look up the data row in the clustered index, by searching for the column1 valuean elegant solution. If the clustered index and the secondary index both have three levels, the DBMS needs (3 + 3) six I/Os to reach the data row, given the column2 value. The search would be faster if there was a ROWID. In fact, a heap is "as good" (same I/O) if you're always looking for a unique value. So let's suppose thisYou have a table with only two unique or nearly unique indexes. Access is equally likely via either index, so you're better off with a heap. This may sound counter-intuitive, so let's examine the situation more closely. Here, once again, are our assumptions:
Now, if you're looking up in a heap and the number of index levels is always three, then the average I/O count for the lookup is fourthree I/Os to access via either index and one I/O to access the heap page, given the ROWID. On the other hand, if you're looking up in a cluster, the time to look up with the cluster key is three I/Os, and the time to look up via the secondary index is six as shown earlier. The average when either index is equally likely is thus 4.5 I/Os ((3 I/Os + 6 I/Os)/2) . This is more than the four I/Os needed for a heap, and so a heap is better if access is equally likely with either index. Still, Microsoft recommends clustered indexes "always." While we're on the subject of strong-clustered indexes, here are some tips on their use:
The Bottom Line: Types of IndexesA compound index is an index whose keys contain values derived from more than one data column. A compound index is good when you want to search for, or sort by (a) the left-most column or (b) the left-most column and any of the other columns. Over indexing is useless because the DBMS often picks only one index as a driver. The way to make use of an index on a second column is to put the column in a compound index. Use compound indexes if queries often contain the same columns, joined with AND. Use compound indexes if you have any key based on a one-character column. The left-most column in a compound index should be the one that occurs in queries most often. It should also be the most selective column. When everything in the select list is in the index that will be used, the index is called a covering index. Ordinarily, using a covering index will save one disk read, but only if the columns in the select list exactly match the columns in the covering index. You lose the gain if you select functions or literals, or if you put the column names in a different order. Whenever possible, persuade the DBMS to use a covering index regardless of whether it's searching for anything. If the rows in the table are large, and the index keys are small, persuade the DBMS to use a covering index. The benefits of "treating the index as a table" are often significant. Just remember that (a) DBMSs never use covering indexes when there are joins or groupings, (b) the index selection can't be used for UPDATE statements, and (c) adding frequently changed columns to indexes strictly to make them covering indexes violates the principle that indexes should not be volatile. Index selectivity is calculated as: Selectivity can be less than one if NULLs are indexed, or it can be less than one if duplicate keys are allowed. When selectivity equals one, you have perfect selectivityand a unique index. If the DBMS knows in advance a value can occur only once, it can exit the loop quickly after it has found that value. It won't bother reading and checking again. So unique indexes can save time. Be prepared to drop redundant indexes. When defining a compound index, put the most selective key on the left. There are two main types of cluster indexes: "strong" clusters and "weak" clusters. Strong clusters have these characteristics:
Weak clusters have these characteristics:
Beware of the cluster key that is monotonically sequential. The problem with monotonics (aka serials) is that the nth row and the (n + 1)th row will both fit in the same pageso there might be contention for the same resource. Usually, in multiuser systems, you want rows to be dispersed. The benefits of clustered indexing depend on a monster assumptionthat you want to retrieve and sort by the cluster key far, far more often than with any other key. Choose your cluster keys accordingly . |
EAN: 2147483647
Pages: 125