How Does XSLT Transform XML?
By now you are probably wondering exactly how XSLT goes about processing an XML document in order to convert it into the required output. There are usually two aspects to this process:
-
The first stage is a structural transformation, in which the data is converted from the structure of the incoming XML document to a structure that reflects the desired output.
-
The second stage is formatting, in which the new structure is output in the required format such as HTML or PDF.
The second stage covers the ground we discussed in the previous section; the data structure that results from the first stage can be output as HTML, a text file, or as XML. HTML output allows the information to be viewed directly in a browser by a human user or be input into any modern word processor. Plain text output allows data to be formatted in the way an existing application can accept, for example comma-separated values or one of the many text-based data interchange formats that were developed before XML arrived on the scene. Finally, XML output allows the data to be supplied to one of the new breed of applications that accepts XML directly. Typically, this will use a different vocabulary of XML tags from the original document: for example, an XSLT transformation might take the monthly sales figures as its XML input and produce a histogram as its XML output, using the XML-based SVG standard for vector graphics. Or, you could use an XSLT transformation to generate Voice XML output, for aural rendition of your data.
Information about VoiceXML can be found at http://www.voicexml.org/ .
Let's now delve into the first stage, transformation-the stage with which XSLT is primarily concerned and which makes it possible to provide output in all of these formats. This stage might involve selecting data, aggregating and grouping it, sorting it, or performing arithmetic conversions such as changing centimeters to inches.
So how does this come about? Before the advent of XSLT, you could only process incoming XML documents by writing a custom application. The application wouldn't actually need to parse the raw XML, but it would need to invoke an XML parser, via a defined Application Programming Interface (API), to get information from the document and do something with it. There are two principal APIs for achieving this: the Simple API for XML (SAX) and the Document Object Model (DOM).
The SAX API is an event-based interface in which the parser notifies the application of each piece of information in the document as it is read. If you use the DOM API, then the parser interrogates the document and builds a tree-like object structure in memory. You would then write a custom application (in a procedural language such as C#, Visual Basic, or Java, for example), which could interrogate this tree structure. It would do so by defining a specific sequence of steps to be followed in order to produce the required output. Thus, whatever parser you use, this process has the same principal drawback: every time you want to handle a new kind of XML document, you have to write a new custom program, describing a different sequence of steps, to process the XML.
So, how is using XSLT to perform transformations on XML better than writing custom applications? Well, the design of XSLT is based on a recognition that these programs are all very similar, and it should therefore be possible to describe what they do using a high-level declarative language rather than writing each program from scratch in C#, Visual Basic, or Java. The required transformation can be expressed as a set of rules. These rules are based on defining what output should be generated when particular patterns occur in the input. The language is declarative in the sense that you describe the transformation you require, rather than providing a sequence of procedural instructions to achieve it. XSLT describes the required transformation and then relies on the XSLT processor to decide the most efficient way to go about it.
XSLT still relies on an XML parser-it might be a DOM parser or a SAX-compliant one, or one of the new breed of "pull parsers"-to convert the XML document into a tree structure. It is the structure of this tree representation of the document that XSLT manipulates, not the document itself. If you are familiar with the DOM, then you will be happy with the idea of treating every item in an XML document (elements, attributes, processing instructions, and so on) as a node in a tree. With XSLT we have a high-level language that can navigate around a node tree, select specific nodes, and perform complex manipulations on these nodes.
The XSLT tree model is similar in concept to the DOM but it is not the same. The full XSLT processing model is discussed in Chapter 2 .
The description of XSLT given thus far (a declarative language that can navigate to and select specific data and then manipulate that data) may strike you as being similar to that of the standard database query language, SQL. Let's take a closer look at this comparison.
XSLT and SQL: An Analogy
In a relational database, the data consists of a set of tables. By themselves , the tables are not of much use, the data might as well be stored in flat files in comma-separated values format. The power of a relational database doesn't come from its data structure: it comes from the language that processes the data, SQL. In the same way, XML on its own just defines a data structure. It's a bit richer than the tables of the relational model, but by itself it doesn't actually do anything very useful. It's when we get a high-level language expressly designed to manipulate the data structure that we start to find we've got something interesting on our hands, and for XML data the main language that does that is XSLT.
Superficially, SQL and XSLT are very different languages. But if you look below the surface, they actually have a lot in common. For starters, in order to process specific data, be it in a relational database or an XML document, the processing language must incorporate a declarative query syntax for selecting the data that needs to be processed . In SQL, that's the SELECT statement. In XSLT, the equivalent is the XPath expression.
The XPath expression language forms an essential part of XSLT, though it is actually defined in a separate W3C Recommendation ( http://www.w3.org/TR/xpath ) because it can also be used independently of XSLT (the relationship between XPath and XSLT is discussed further on page 21). For the same reason, I cover the details of XPath in a companion book, XPath 2.0 Programmer's Reference .
The XPath syntax is designed to retrieve nodes from an XML document, based on a path through the XML document or the context in which the node appears. It allows access to specific nodes, while preserving the hierarchy and structure of the document. XSLT is then used to manipulate the results of these queries, for example by rearranging selected nodes and constructing new nodes.
There are further similarities between XSLT and SQL:
-
Both languages augment the basic query facilities with useful additions for performing arithmetic, string manipulation, and comparison operations.
-
Both languages supplement the declarative query syntax with semiprocedural facilities for describing the processing to be carried out, and they also provide hooks to escape into conventional programming languages where the algorithms start to get too complex.
-
Both languages have an important property called closure, which means that the output has the same data structure as the input. For SQL, this structure is tables, for XSLT it is trees-the tree representation of XML documents. The closure property is extremely valuable because it means operations performed using the language can be combined end-to-end to define bigger, more complex operations: you just take the output of one operation and make it the input of the next operation. In SQL you can do this by defining views or subqueries; in XSLT you can do it by passing your data through a series of stylesheets, or by capturing the output of one transformation phase as a temporary tree, and using that temporary tree as the input of another transformation phase. This last feature is new in XSLT 2.0, though most XSLT 1.0 processors offered a similar capability as a language extension.
In the real world, of course, XSLT and SQL have to coexist. There are many possible relationships but typically, data is stored in relational databases and transmitted between systems in XML. The two languages don't fit together as comfortably as one would like, because the data models are so different. But XSLT transformations can play an important role in bridging the divide. A number of database vendors have delivered (or at least promised ) products that integrate XML and SQL, and some standards are starting to emerge in this area. Check the vendor's Web sites for the latest releases of Microsoft SQL Server, IBM DB2, and Oracle 10 g.
Before we look at a simple working example of an XSLT transformation, we should briefly discuss a few of the XSLT processors that are available to effect these transformations.
XSLT Processors
The job of an XSLT processor is to apply an XSLT stylesheet to an XML source document and produce a result document.
With XSLT 1.0, there are quite a few good XSLT processors to choose from, and many of them can be downloaded free of charge (but do read the licensing conditions).
If you're working in the Microsoft environment, there is a choice of two products. The most widely used option is MSXML3/4 (Google for "Download MSXML4" to find it). Usually, I'm not Microsoft's greatest fan, but with this processor it's generally agreed that they have done an excellent job. This product comes as standard with Internet Explorer and is therefore the preferred choice for running transformations in the browser. The XSLT processor differs little between MSXML3 and MSXML4: the differences are in what else comes in the package. MSXML3 also includes support for an obsolete but still- encountered dialect of XSLT called WD-xsl (which isn't covered in this book), while MSXML4 includes more extensive support for XML Schema processing. For the .NET environment, however, Microsoft has developed a new processor. This doesn't have a product name of its own, other than its package name within the .NET framework, which is System.Xml.Xsl . This processor is often said to be slower than the MSXML3 product, but if you're writing your application using .NET technologies such as C# and ASP.NET, it's probably the one that you'll find more convenient .
In the Java world, there's a choice of open -source products. There's my own Saxon product (version 6.5.3 is the version that supports XSLT 1.0) available from http://saxon.sf.net/ , there's the Xalan-J product available from Apache at http://xml.apache.org/ , there is a processor from Oracle, and there is the less well known but highly regarded jd.xslt product from Johannes D bler at http://www.aztecrider.com/ , which is sadly no longer available for free download. The standard for all these products was set by James Clark's original xt processor, which has been updated by Bill Lindsay and is now available at http://www.blnz.com/xt/index.html . A version of Xalan-J is bundled with Sun's Java JDK software from JDK 1.4 onwards.
Other popular XSLT processors include the libxslt engine ( http://xmlsoft.org/XSLT/ ), Sablotron ( http://www.gingerall.com/charlie/ga/xml/p_sab.xml ), and 4XSLT (part of 4suite, see http://4suite.org/index.xhtml).
Most of these products are XSLT interpreters, but there are two well-known XSLT compilers: XSLTC, which is distributed as part of the Xalan-J package mentioned earlier, and Gregor, from Jacek Ambroziak ( http://www.ambrosoft.com/gregor.html ).
The XSLT processor bundled with the Netscape/Mozilla browser is Transformiix ( http://www.mozilla.org/projects/xslt/ ).
There are a number of development environments that include XSLT processors with custom editing and debugging capabilities. Notable examples are XML Spy ( http://www.altova.com ) and Stylus Studio ( http://www.stylusstudio.com/ ).
However, these are all XSLT 1.0 processors, and this book is about XSLT 2.0. With XSLT 2.0, at the time of writing, you really have one choice only, and that is my own Saxon product. By the time you read this, you will be able to get the Saxon XSLT 2.0 processor in two variants, corresponding to the two conformance levels defined in the W3C specification: Standard Saxon 8.x ( http://saxon.sf.net/ ) is an open-source implementation of a basic XSLT 2.0 processor, and Saxon-SA 8.x ( http://www.saxonica.com/ ) is a commercial implementation of a schema-aware XSLT processor. You can run most of the examples in this book, using a basic XSLT processor, but Chapter 4 and Chapter 11 focus on the additional capability of XSLT when used with XML Schemas, with examples that will only run with a schema-aware product.
There are several other XSLT 2.0 processors under development, though it's not my job to pass on unofficial rumors. Oracle has released a beta implementation ( http://otn.oracle.com/tech/xml/xdk/xdkbeta.html ). Apache has said that they are developing an XSLT 2.0 version of Xalan, and although things have been very quiet in public since they announced this, if you poke around the archives of their internal developers' mailing list (which are all openly available) you can see that work is proceeding, slowly but steadily.
The biggest uncertainty at the moment is what Microsoft will do. The MSXML3/4 products have been highly successful technically, though whether Microsoft considers them a commercial success is anyone 's guess. The .NET processor also appears to be a competent piece of engineering. However, the unofficial rumor from Reston is that there is no XSLT 2.0 version of this technology under development. Instead, most of Microsoft's efforts seem to be going into the development of their XQuery engine, designed as part of the SQL Server release code-named Yukon. I have heard speculation that if and when Microsoft implements XSLT 2.0, it is likely to be done using this engine. XSLT 2.0 and XQuery 1.0 are so close in their semantics that it's entirely possible to implement both languages, using the same processing engine, as Saxon has already demonstrated.
It shouldn't really be a surprise that commercial vendors are keeping fairly quiet about their plans while the specifications are still working drafts. When a specification first comes out at version 1.0, there is a great deal of commercial advantage to be gained by releasing beta implementations as early as possible. With a 2.0 draft, it's more prudent to wait until you know exactly what's in the final specification. W3C specifications these days spend a long time in their "Candidate Recommendation" phase, and this is the time to look for evidence of implementation activity. Although XSLT 2.0 is close to reaching that phase, it isn't there yet at the time of writing.
I think it's a little unlikely that there will be quite as many XSLT 2.0 processors as there are for XSLT 1.0 (there is bound to be some shakeout in a maturing market), but I'm confident there will be four or five, which should be enough.
Meanwhile, there is Saxon, and that's what I will be using for all the examples in this book.
An XSLT 1.0 Stylesheet
We're now ready to take a look at an example of using XSLT to transform a very simple XML document.
| |
Kernighan and Ritchie in their classic The C Programming Language (Prentice-Hall, 1988) originated the idea of presenting a trivial but complete program right at the beginning of the book, and ever since then the Hello world program has been an honored tradition. Of course, a complete description of how this example works is not possible until all the concepts have been defined, and so if you feel I'm not explaining it fully, don't worry-the explanations will come later.
Input
What kind of transformation would we like to do? Let's try transforming the following XML document.
<?xml version="1.0" encoding="iso-8859-1"?> <?xml-stylesheet type="text/xsl" href="hello.xsl"?> <greeting>Hello, world!</greeting>
This document is available as file hello.xml in the download directory for this chapter.
A simple node-tree representation of this document is shown in Figure 1-2.
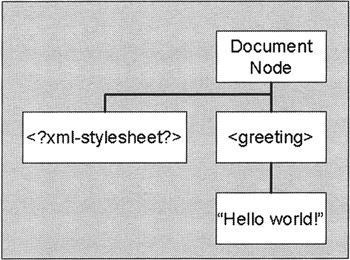
Figure 1-2
There are four nodes in this tree: a document node that represents the document as a whole; an <?xml-stylesheet?> processing instruction that identifies the stylesheet to be used; the <greeting> element; and the text within the <greeting> element.
The document node in the XSLT model performs the same function as the document node in the DOM model (it was called the root node in XSLT 1.0, but the nomenclature has been brought into line with the DOM). The XML declaration is not visible to the XSLT processor and, therefore, is not included in the tree.
I've deliberately made it easy by including an <?xml-stylesheet?> processing instruction in the source XML file. Many XSLT processors will use this to identify the stylesheet if you don't specify a different stylesheet to use. The href attribute gives the relative URI of the default stylesheet for this document.
Output
Our required output is the following HTML, which will simply change the browser title to "Today's Greeting" and display whatever greeting is in the source XML file:
<html> <head> <title>Today's greeting</title> </head> <body> <p>Hello, world!</p> </body> </html>
XSLT Stylesheet
Without any more ado, here's the XSLT stylesheet hello.xsl to effect the transformation.
<?xml version=''1.0" encoding="iso-8859-1"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Today's greeting</title> </head> <body> <p><xsl:value-of select="greeting''/></p> </body> </html> </xsl:template> </xsl:stylesheet>
Running the Stylesheet
You can run this stylesheet in a number of different ways. The easiest is simply to load the XML file hello.xml into any recent version of Internet Explorer or Netscape. The browser will recognize the <?xml-stylesheet?> processing instruction and will use this to fetch the stylesheet and execute it. The result is a display like the one in Figure 1-3.
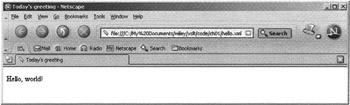
Figure 1-3
Note that this example is an XSLT 1.0 stylesheet. Current versions of Internet Explorer and Netscape don't yet support XSLT 2.0.
Saxon
Running the stylesheet with Saxon is a bit more complicated, because you first need to install the software. It's worth going through these steps, because you will need Saxon to run later examples in this book. The steps are as follows :
-
Ensure you have the Java SDK version 1.4 or later installed on your machine. You can get this from http://java.sun.com/ . Saxon is pure Java code, and so it will run on any platform that supports Java, but I will usually assume that you are using a Windows machine.
-
Download the Saxon processor from http://saxon.sf.net/ . Any version of Saxon will run this example, but we'll soon be introducing XSLT 2.0 examples, so install a recent version, say Saxon 7.9.
-
Unzip the download file into a suitable directory, for example c:\saxon..
-
Within this directory, create a subdirectory called data .
-
Using Notepad, type the two files mentioned earlier into hello.xml and hello.xsl respectively, within this directory (or get them from the Wrox Web site at http://www.wrox.com ).
-
Bring up an MSDOS-style console window (using Start Programs MSDOS Prompt on Windows 98 or NT, or look in the Accessories menu under Windows 2000 or Windows XT).
-
Type the following at the command prompt.
java -jar c:\saxon\saxon8.jar -a hello.xml -
Admire the HTML displayed on the standard output.
If you want to view the output using your browser, simply save the command line output as an HTML file, in the following manner.
java -jar c:\saxon\saxon8.jar -a hello.xml >hello.html (Using the command prompt in Windows isn't much fun. I would recommend acquiring a good text editor: most editors have the ability invoke a command line processor that is usually much more usable than the one provided by the operating system. I have recently started using jEdit , which is free and can be downloaded from http://www.jedit.org/ . Be sure to install the optional Console plug-in.)
How It Works
If you've succeeded in running this example, or even if you just want to get on with reading the book, you'll want to know how it works. Let's dissect it.
<?xml version="1.0" encoding="iso-8859-1"?> This is just the standard XML heading. The interesting point is that an XSLT stylesheet is itself an XML document. I'll have more to say about this, later in the chapter. I've used iso-8859-1 character encoding (which is the official name for the character set that Microsoft sometimes calls "ANSI") because in Western Europe and North America it's the character set that most text editors support. If you've got a text editor that supports UTF-8 or some other character encoding, feel free to use that instead.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
This is the standard XSLT heading. In XML terms it's an element start tag, and it identifies the document as a stylesheet. The xmlns:xsl attribute is an XML Namespace declaration, which indicates that the prefix xsl is going to be used for elements defined in the W3C XSLT specification. XSLT makes extensive use of XML namespaces, and all the element names defined in the standard are prefixed with this namespace to avoid any clash with names used in your source document. The version attribute indicates that the stylesheet is only using features from version 1.0 of the XSLT standard.
Let's move on.
<xsl:template match="/"> An <xsl:template> element defines a template rule to be triggered when a particular part of the source document is being processed. The attribute «match="/" » indicates that this particular rule is triggered right at the start of processing the source document. Here «/ » is an XPath expression that identifies the document node of the document: an XML document has a hierarchic structure, and in the same way as UNIX uses the special filename «/ » to indicate the root of a hierarchic file store, XPath uses «/ » to represent the root of the XML content hierarchy.
<html> <head> <title>Today's greeting</title> </head> <body> <p><xsl:value-of select="greeting"/></p> </body> </html>
Once this rule is triggered, the body of the template says what output to generate. Most of the template body here is a sequence of HTML elements and text to be copied into the output file. There's one exception: an <xsl:value-of> element, which we recognize as an XSLT instruction, because it uses the namespace prefix xsl . This particular instruction copies the textual content of a node in the source document to the output document. The select attribute of the element specifies the node for which the value should be evaluated. The XPath expression «greeting » means "find the set of all <greeting> elements that are children of the node that this template rule is currently processing." In this case, this means the <greeting> element that's the outermost element of the source document. The <xsl:value-of> instruction then extracts the text of this element and copies it to the output at the relevant place-in other words, within the generated <p> element.
All that remains is to finish what we started.
</xsl:template> </xsl:stylesheet>
| |
In fact, for a simple stylesheet like the one shown earlier, you can cut out some of the red tape. Since there is only one template rule, the <xsl:template> element can actually be omitted. The following is a complete, valid stylesheet equivalent to the preceding one.
<html xsl:version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <head> <title>Today's-greeting</title> </head> <body> <p><xsl:value-of select="greeting"/></p> </body> </html>
This simplified syntax is designed to make XSLT look familiar to people who have learned to use proprietary template languages that allow you to write a skeleton HTML page with special tags (analogous to <xsl:value-of> ) to insert variable data at the appropriate place. But as we'll see, XSLT is much more powerful than that.
Why would you want to place today's greeting in a separate XML file and display it using a stylesheet? One reason is that you might want to show the greeting in different ways, depending on the context; for example, it might be shown differently on a different device, or the greeting might depend on the time of day. In this case, you could write a different stylesheet to transform the same source document in a different way. This raises the question of how a stylesheet gets selected at run-time. There is no single answer to this question: it depends on the product you are using.
With Saxon, we used the -a option to process the XML document using the stylesheet specified in its <?xml-stylesheet?> processing instruction. Instead, we could simply have specified the stylesheet on the command line:
java -jar c:\saxon\saxon8.jar hello.xml hello.xsl >hello.html The same thing can also be achieved with the Microsoft XSLT product. Like Saxon, this has a command line interface; though, if you want to control it programmatically in the browser you will need to write an HTML page containing some script code to control the transformation. The <?xml-stylesheet?> processing instruction which I used in the example described earlier works only if you want to use the same stylesheet every time.
Having looked at a very simple XSLT 1.0 stylesheet, let's now look at a stylesheet that uses features that are new in XSLT 2.0.
An XSLT 2.0 Stylesheet
This stylesheet is very short, but it manages to use four or five new XSLT 2.0 and XPath 2.0 features within the space of a few lines. I wrote it in response to a user enquiry raised on the xsl-list at http://www.mulberrytech.com/ (an excellent place for meeting other XSLT developers with widely varying levels of experience); so it's a real problem, not an invention. The XSLT 1.0 solution to this problem is about 60 lines of code.
| |
The problem is simply stated: given any XML document, produce a list of the words that appear in its text, giving the number of times each word appears, together with its frequency.
Input
The input can be any XML document. I will use the text of Shakespeare's Othello as an example; this is provided as othello.xml in the download files for this book.
Output
The required output is an XML file that lists words in decreasing order of frequency. For Othello, the output file starts like this.
<?xml version="1.0" encoding="UTF-8"?> <wordcount> <word word="i" frequency="899"/> <word word="and" frequency="'796"/> <word word="the" frequency="764"/> <word word="to" frequency="632"/> <word word="you" frequency="494"/> <word word="of" frequency="476"/> <word word="a" frequency="453"/> <word word="my" frequency="427"/> <word word="that" frequency="396"/> <word word="iago" frequency="361"/> <word word="in" frequency="343"/> <word word="othello" frequency="336"/> <word word="it" frequency="319"/> <word word="not" frequency="319"/> <word word="is" frequency="309"/> <word word="me" frequency="281"/> <word word="cassio" frequency="254"/>
Stylesheet
Here is the stylesheet that produces this output. You can find it in wordcount.xsl .
<?xml version="1.0" encoding="iso-8859-1"?> <xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="xml" indent="yes"/> <xsl:template match="/"> <wordcount> <xsl:for-each-group group-by="." select=" for $w in tokenize(string(.), '\W+') return lower-case($w)"> <xsl:sort select="count(current-group())" order="descending"/> <word word="{current-grouping-key()}" frequency="{count(current-group())}"/> </xsl:for-each-group> </wordcount> </xsl:template> </xsl:stylesheet>
Let's see how this works.
The <xsl:stylesheet> element introduces the XSLT namespace, as before, and tells us that this stylesheet is designed to be used with an XSLT 2.0 processor.
The <xsl:output> element asks for the XML output of the stylesheet to be indented, which makes it much easier for humans to read.
There is one <xsl:template> element, as before, which defines the code to be executed when the document node of the source document is encountered. This generates a <wordcount> element in the result, and within this it puts the word frequencies.
To understand the <xsl:for-each-group> instruction, which is new in XSLT 2.0, we first need to look at its select attribute. This contains the XPath 2.0 expression
for $w in tokenize(string(.), '\W+') return lower-case($w) This first calculates string(.) , the string-value of the node currently being processed, which in this case contains the whole text of the input document, ignoring all markup. It then tokenizes this big string: that is, it splits it into a sequence of substrings. The tokenizing is done by applying the regular expression «\W+ » . Regular expressions are new in XPath 2.0 and XSLT 2.0, though they will be very familiar to users of other languages such as Perl. They provide the language with greatly enhanced text handling capability. This particular expression, «\W+ » , matches any sequence of one-or-more "non-word" characters , a convenient category that includes spaces, punctuation marks, and other separators. So the result of calling the tokenize() function is a sequence of strings containing the words that appear in the text.
The XPath «for » expression now applies the function lower-case() to each of the strings in this sequence, producing the lower-case equivalent of the word. (Almost everything in this XPath expression is new in XPath 2.0: the lower-case() function, the tokenize() function, the «for » expression, and indeed the ability to manipulate a sequence of strings.)
The XSLT stylesheet now takes this sequence of strings and applies the <xsl:for-each-group> instruction to it. This processes the body of the <xsl:for-each-group> instruction once for each group of selected items, where a group is identified as those items that have a common value for a grouping key. In this case the grouping key is written as «group-by="." » , which means that the values (the words) are grouped on their own value. (In another application, we might have chosen to group them by their length, or by their initial letter.) So, the body of the instruction is executed once for each distinct word, and the <xsl:sort> instruction tells us to sort the groups in descending order of the size of the groups (that is, the number of times each word appears). For each of the groups, we output a <word> element with two attributes: one attribute is the value we used as the grouping key, the other is the number of items in the group.
| |
Don't worry if this example seemed a bit bewildering: it uses many concepts that haven't been explained yet. The purpose was to give you a feeling for some of the new features in XSLT 2.0 and XPath 2.0, which will all be explained in much greater detail elsewhere in this book (in the case of XSLT features) or in the companion book XPath 2.0 Programmer's Reference .
Having dipped our toes briefly into some XSLT code, I'd now like to step back to take a higher-level view, to discuss where XSLT as a technology fits into the big picture of designing applications for the Web.
EAN: 2147483647
Pages: 324
- An Emerging Strategy for E-Business IT Governance
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- Governing Information Technology Through COBIT
- Governance in IT Outsourcing Partnerships