WebSphere Database Tuning
As you move from the database driver implementations and various programmable-level constructs such as DAOs, CMPs, and so forth, you'll learn about some specific aspects of optimizing your WebSphere platform for several of the leading database vendors products.
Specifically, in this section, you'll explore the optimization and tuning recommendations for the two most common database products used with WebSphere:
-
Oracle 8 i and 9 i
-
IBM DB2
Something I find as a useful tool is a checklist of configuration and design considerations. From a database implementation perspective, the following ten items make up my performance checklist for database-to-WebSphere implementation (in no order of priority):
-
Use prepared SQL statements where possible.
-
Plan and design your data file layout architecture.
-
Memory, memory, memory: Databases like memory for buffers.
-
Use connection pooling.
-
Manage your persisted sessions properly ”tune, test, tune, test.
-
Design and test your data persistence mechanism carefully (for example, CMP and BMP).
-
Use indexes ”always.
-
Locate your databases within one hop of your WebSphere application servers for performance.
-
Don't share database instances for different workload characteristics.
-
Always implement some level of high availability.
It's important to note that this is in no way an exhaustive list in the same way this book isn't a database administrator's reference manual! However, you need to consider many specific WebSphere (J2EE) factors when optimizing WebSphere and databases. At the same time, you can consider other database architectural and administrative factors. However, what I'm covering here are design considerations that impact WebSphere performance.
Also, it's important to note that in this chapter, I'm discussing only the implementation aspects of interfacing WebSphere with databases, not application development best practices ( please see Chapter 10 for information about this). You'll look at some key points for implementing or architecting a WebSphere implementation with one of the aforementioned vendor databases.
You'll explore generic Relational Database Management System (RDBMS) performance guidelines for integration to WebSphere environments and then each of the two databases in terms of specific optimization configuration parameters. Then, you'll look at ways to monitor the two databases and understand what constitutes poor performance, as well as learn how to diagnose where the problems are.
You'll now look at the specific key optimization and design points for the two databases discussed earlier ”Oracle and DB2.
Generic Database Performance Architecture with WebSphere
All relational databases typically follow the same rules when it comes to planning and architecting high-performance, high-availability implementations. In this section, you'll look at these rules and learn how WebSphere benefits from each of them. Although databases all follow similar rules in terms of what produces high performance, the implementation of those rules is different between each database.
Common to all database platforms is their sizing requirements. Most, if not all, will invariably have similar requirements when it comes to the sizing of databases. Essentially , it's not a database requirement but a set of guidelines for the type of workload an RDBMS will put onto a server.
If someone asks me what factors they should consider when implementing a database for a WebSphere-based environment, I typically ask the following questions:
-
What are you going to be using your database for?
-
What sort of transaction or SQL query rate do you expect to have to your database?
-
How dependant is your WebSphere-based application on database performance and usage?
-
What sort of SQL transactions are you looking to support ”complex or small?
-
What sort of scalability are you expecting from your database platform?
You should ask yourself these same questions.
The Purpose of the Database
What are you going to be using your database for? Are you running WebSphere 4, which will need table spaces for the administrative repository plus potential table spaces for application data?
If you're not in need of an RDBMS for your application and just in need of a WebSphere-based repository sitting on the RDBMS, then your database requirements will be minimal. On the other hand, if your WebSphere-based applications will be performing high transaction rates to multiple database instances or table spaces, then your design model is completely different.
The answer to this question will determine just how complex and how much effort you'll need to spend to ensure that your WebSphere-based applications will perform optimally.
Transaction Rate
What sort of transaction or SQL query rate do you expect to have to your database? You may have a complex database environment with many database instances; however, if your SQL or transaction rates are low, then your database size won't need to be complex.
Complex sizing means expensive hardware, and complex database and data architecture means expensive design work. You don't have to have a complex infrastructure platform if you have a complex data requirement (and vice versa).
However, you can safely assume that if your SQL or transaction rate is high, you'll need to invest in both hardware and solid database architecture.
Reliance on the Database
How dependant is your WebSphere-based application on database performance and usage? You need to understand what would happen if your database became unavailable. What would happen to your application? Would it stop operating and serving customers? Does it frequently use the database, or does it operate via an in-memory WebSphere caching mechanism where data is sourced from?
If your application must have a database available at all times, then your platform architecture will need to consider high-availability services. You'll need hot-standby servers, highly available solutions, or active clustered solutions.
Type of Transactions
What sort of SQL transactions are you looking to support ”complex or small? Although similar to the second question, this question explores the type of transaction your database will be serving.
As you saw in several of the earlier chapters, you can break down transactional characteristics into two groups. First, you can have a high transaction rate but a small or lightweight transaction characteristic (for example, select * from usertable where username = "me"; ). Or, you can have a high transaction rate with a large or heavyweight transactional characteristic (for example, the same previous SQL query but with several table joins and conditional WHERE clauses). On the other hand, you can have a low transaction rate with a small or lightweight transactional characteristic or a large or heavyweight transactional characteristic .
This sounds somewhat simple, but it's an important consideration to remember. High transaction rates will typically require faster disks and will benefit from more disks (spindles) because the overall I/O rate will be high, regardless of the transaction characteristic. Typically, well- tuned buffers will also be advantageous, and therefore memory will be important.
Scalability
What sort of scalability are you expecting from your database platform? This question looks at the long- term lifespan of your environment. If you don't believe you'll need to scale up in the future, you can reduce your hardware costs by not purchasing servers with room for expansion.
The same applies to how you lay out your database architecture. For example, raw partitions provide additional performance over that of native or " cooked " partitions; however, they're cumbersome to manage.
If you're looking at a fairly static system architecture, you may be able to go with raw partitions to gain the extra performance, considering that your operational overhead won't be large if you're not looking to scale and change your database architecture often.
Scalable systems require scalable designs, and scalable designs are typically more complex and more costly to implement.
Generic WebSphere Database Sizing
Sizing a database is a fairly complicated undertaking in itself, and it's one of those "how long is a piece of string" situations. I'll highlight some key points about sizing an RDBMS that synergize well with WebSphere platforms.
Most databases perform well with lots of memory and lots of disk drives. As a rule, you can never have enough disk drives in a relational database platform. These are the three types of database usage you may require with WebSphere:
-
First, for WebSphere 4, you'll want to operate a WebSphere repository on your database that's efficient but doesn't need to be massively high performing. If you don't happen to need a database for anything other than the WebSphere repository, then your life is easy. Even with a multinode WebSphere cluster operating many WebSphere domains, the load on the WebSphere administration database (the repository) will be minimal to low.
-
The second form of database usage is for WebSphere session persistence. In this situation, the performance of your database has a direct result on the attributed performance experienced by your end users. If your database is underpowered or not performing, then you'll find that your session management will be a major bottleneck of your environment.
-
The third form of database usage is for the applications that operate under WebSphere. This is all the custom or third-party applications deployed into the WebSphere environment that use a database for storing information, logs, configuration information, and so on.
The WebSphere repository database performance has the lowest overall impact on a WebSphere environment, with the application database having the highest impact.
You should consider the following key items carefully when implementing high-end databases:
-
Disks and disk configuration (including controllers)
-
Memory and memory configuration
-
System configuration, including Central Processing Units (CPUs) and backplanes
-
The network
You'll now learn about each of those.
Disks and Disk Configuration
You explored the science of disks and disk controllers in Chapter 6. You'll now look at some more database-specific considerations that will help you with database sizing. The key to database sizing for your application database is to spread the database files as much as you can. Distribute load across many spindles to reduce single-disk bottlenecks.
Even with the more advanced disks available on the market being able to push theoretically more than 300 megabytes per second (MBps) over a data bus, a single disk performing this operation will still result in poor performance for many concurrent requests .
Consider your usage type based on Table 11-4 (later in the chapter). Although this is a guide, be sure to model your database sizing requirements carefully before implementing the end solution.
| Database Type Network Workload | Disk Workload | Memory Workload | System Workload |
|---|---|---|---|
| DSS | High I/O rate | High memory usage | Medium to high ” dependant on size of DSS database Low network requirements |
| Batch based | High I/O | High memory usage | Medium to high Low to medium network requirements |
| OLAP | Generally low I/O Rate | High memory usage | Medium to high Medium network requirements |
| OLTP | Medium to high I/O | Medium to high memory usage | Medium to high ” generally lower than DSS |
For both performance and redundancy, be sure to split your data buses as much as possible. For example, although SCSI and Fibre Channel can both support a fair amount of devices on each bus, consider only loading each bus up by 50 percent to facilitate both overhead (peak contingency) and promote redundancy.
Refer to Table 11-4 for a breakdown of various I/O types.
Memory and Memory Configuration
Memory is really just a high-speed (albeit volatile) version of a disk drive. Given that the access speed of memory is in the order of 10 nanoseconds (ns) as opposed to 10 milliseconds (ms) for disk drives, the more you can reference your data out of memory or buffer, the better.
All the major databases provide methods of caching queries, caching results, and caching frequently accessed data into memory. You'll look at some parameters for the leading databases that provide this functionality shortly.
There's no rule of thumb to capture all types of database memory requirements. Proper sizing and modeling is the only way you can understand your requirements. Therefore, the only guide is to ensure that your cache and buffer hit ratios are as high as possible and that you continue to monitor them.
In Oracle, the Shared Global Area (SGA) is a key to the amount of memory your database has available to it; in DB2, it's known as the buffer pool .
For each of the leading database vendors, you'll look at how to tell if your database environment is choking for memory. Also, refer to Table 11-4 for a high-level overview of differing database transaction characteristics.
System Configuration
The system configuration boils down to the type and number of CPUs in your database environment. All the processing of queries and updating of database files as well as administrative functions such as logging and locking and so forth need to be processed by the CPU(s).
If your WebSphere application database is of a high Decision Support System (DSS) workload, then it's going to be more CPU hungry than a WebSphere application that uses a database in an Online Transaction Processing (OLTP) workload.
Therefore, you need to make this decision based on your requirements, your modeling, and your future scalability. Chapter 5 showed ways to understand your performance and sizing of different technologies, and Chapter 4 showed the different families and types of CPUs available.
Network
Only in a large database workload environment will the network be an issue. Again, nothing will provide you with better supporting information than proper modeling. As a general rule, the faster the network between the WebSphere application servers and the database server tier , the better or more efficient transactions will be.
On a small or low-end WebSphere application environment, the overall response times for a database connected via a 10 megabyte per second (Mbps) network versus that of a 1 gigabit per second (Gbps) network will be marginal. It's only when the transaction rate or the transaction characteristics start to increase in number and size that this will be an issue.
Nowadays, 100Mbps switched is the default standard for any server. This will provide most small- to medium- sized systems with enough bandwidth at high loads.
Summary Matrix
Table 11-4 summarizes the four main areas of database sizing between the most common flavors of database workloads:
-
DSS
-
Batch-based workloads
-
Online Analytical Processing (OLAP)
-
OLTP
Table 11-4 shows the four main areas discussed and summarizes the areas within a database architecture that make up the difference between low and high performing. It's not possible to quantify what high memory or high I/O rate means because they're somewhat arbitrary guides. You should consider these guiding principles when looking at performance or the design of a WebSphere-based application database.
Before you look at specific database vendor performance considerations, you'll take a moment to rehash file system designs and options with databases.
Database Data Layout and Design
Both Oracle and DB2 support a number of different file system types. You can divide them into three groups:
-
Standard Unix file systems
-
Advanced or journaling file systems
-
Raw devices
As you'd expect, each has its advantages and disadvantages. Standard Unix file systems such as the Berkeley System Distribution (BSD) and Unix File System (UFS) provide a satisfactory file system for smaller, lower-end systems.
For Windows-based servers, the equivalent would be a FAT32-type file system.
Advanced file systems are file systems that offer journaling and logging, which provide improvements in reliability and performance on an order of magnitude of the standard file systems. Veritas File System, IBM Journaling File System (JFS), Network File System (NTFS), Compaq Advanced File System, and Solaris UFS-8 are some examples.
Raw file systems are disks with no formatted file system on them. In theory (and in some practice), raw file systems offer greater performance over that of nonraw or formatted file systems. Because there's no middle layer to go through for I/O, the performance is greater.
This is usually the case, however, because more advanced files systems are starting to support features such as Direct I/O, which come close to the performance of raw partitions. Because of the operational and management overhead of supporting raw partitions, you're better off using a file system that supports Direct I/O than one with raw partitions.
If you're fairly confident that your system isn't going to grow in size and if changes to your existing or initial database requirements aren't going to overly high, consider using raw partitions. If you're looking to have a fairly dynamic database environment, consider using one of the more advanced file systems and, where possible, using Direct I/O.
Oracle 8 i and 9 i
The Oracle database is one of the leading database implementations available. I'll cover both versions 8 i and 9 i because of their wide installation base globally and common use with WebSphere 4 and 5.
The two products are somewhat similar at a high level. Like any comparison with a new and older version of enterprise software, Oracle 9 i comes with more features than Oracle 8 i and, in most cases, outperforms Oracle 8 i .
Figure 11-6 shows a high-level overview of the Oracle architecture. Note that this includes only the standard Oracle 8 i /9 i database architecture and doesn't include the Real Application Clusters (RAC) product.
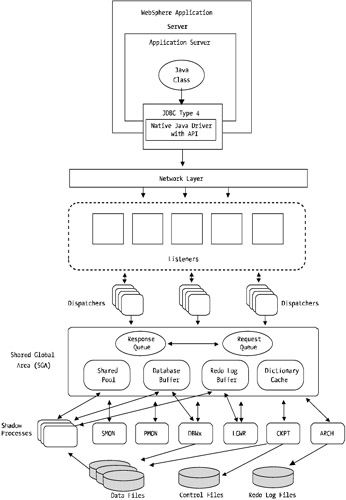
Figure 11-6: Oracle 8 i /9 i high-level architecture
Each database has a centralized buffer or memory area to store cached data to aid in performance. Other supporting processes govern log files, data I/O, and other management functions but are essentially controlled or mastered by a centralized entity, the SGA.
As you'll see shortly with DB2, Oracle's performance hinders around memory and cache or buffer space. Tuning and optimizing this area of the database will yield the best results. The I/O or speed at which I/O can take place to and from the data files on the disk is the next best area to consider tuning. Oracle 9 i also allows you to integrate the Oracle 9 i RAC layer that provides a true active-active database cluster solution, providing ultra -high levels of database availability.
A multitude of available configuration items within Oracle can help performance. Unfortunately, this isn't an Oracle performance optimization manual. Table 11-5 summarizes each of the parameters that you can tune in an Oracle system.
| Parameter/Feature | Description |
|---|---|
| db_block_buffers/db_cache_size | The amount of memory set aside within the Oracle SGA for buffer cache. More is best. |
| db_block_size | The default block size for the specific database. I recommend 8KB-16KB for standard database loads. |
| l og_buffer | The log buffer size. This is important because if it's too small, the log writer will be constantly active. Use 1MB-2MB as a guide when sizing. |
| parallel_max_servers | This sets the size or the amount of query servers. It helps with parallelism of queries. As a guide, set this to four times the number of CPUs in your system. |
| hash_area_size | This sets the maximum size in bytes of the peruser hash join space. Carefully issue changes to this setting based on the number of pooled connections you have from the JDBC connection manager within WebSphere. |
| Shared_pool_size | This is the size, in bytes, of the SGA for your database instance. The setting of this value will be a result of your sizing and memory requirements as a whole. |
| Sort_area_size | This sets the maximum size in bytes of the area in memory of sorts. If your WebSphere-based application is performing many sorts within the query sets, this parameter will be helpful. |
Please don't change your init.ora file based on each of these listed items. Changing it without knowing what you're changing may have dire effects on your system's performance. Use these a guide and talk to your Database Administrator (DBA) or reference your Oracle manuals for more information.
As you can see, you can use a number of settings to help with WebSphere performance.
Several tools are available that can help with Oracle performance monitoring. I'll touch on them in Chapters 13 and 14. However, immediate tools you can use that'll provide the current state and status of the aforementioned parameters are two scripts that come with Oracle.
These tools, called utlbstat and utlestat , provide a good snapshot of the performance and associated optimization metrics. They provide you with a start and end script that activate a number of timers and settings. When you run the completion script, utlestat , you'll get output in a report.txt file.
If you're familiar with using the Oracle sqlplus tool, connect to your database as the sysdba user and run this command:
alter system set timed_statistics = true;
This command will turn on the Oracle-timed collection statistics. The overhead is minimal, and according to Oracle, the impact is negligible to production performance.
Once you've run the previous command, run the utlbstat command as follows :
SQL> @ORACLE_HOME/rdbms/admin/utlbstat;
Leave this command running, and you'll see some output.
Let your database operate normally for a defined period, and then stop the collection by issuing this command:
SQL> @ORACLE_HOME/rdbms/admin/utlestat;
The report.txt file will be created, which will have statistics you can study to gain insight into the performance of your application database.
IBM DB2
IBM DB2 is what I'd consider the other industry database heavyweight. As IBM's RDBMS platform, you can imagine that there are some nifty performance features available for interfacing with WebSphere. The DB2 product suite is fairly large, but many of the parameters are generic across the various platforms.
Like the Oracle section, I'll present some of the key tuning parameters and considerations that impact the way WebSphere communicates to DB2. This is a somewhat generic shopping list of items that you should use while planning and designing your overall environment or as a reactive checklist when there are problems.
Shortly you'll look at DB2 system configuration and tuning parameters that help to improve WebSphere-to-DB2 performance.
Figure 11-7 shows the DB2 architecture at a high level. Similar to Oracle, DB2 has a number of individual processes that make up the core engine.
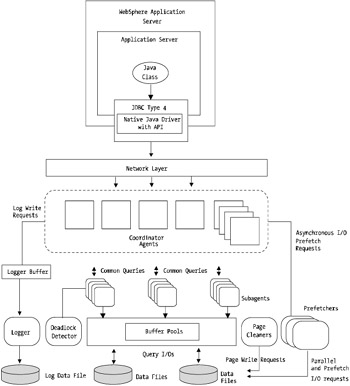
Figure 11-7: DB2 architectural overview
As you can see from Figure 11-7, DB2, like Oracle, is a fairly complex beast . The major components are the agents , subagents, logger, buffer pools, page cleaners, prefetchers, and the data files themselves .
The agents are the master controlling elements within the DB2 engine. These agents coordinate where all the requests need to go ”whether it's to a prefetch agent to start populating the buffer pool with data or whether it's to a subsequent SQL query looking to retrieve information from the buffer pools.
The buffer pool is analogous to Oracle's SGA. It provides all the buffering and caching of data from the disks because, as discussed at length, the more you can retrieve your data and queries from cache or buffer, the faster the overall system response time will be.
Therefore, the optimization of the buffer pool is essential.
Like Oracle, DB2 likes well-optimized memory and buffer configurations. Table 11-6 summarizes the recommended DB2 parameters and commands that help to focus on performance via the use of efficient memory and buffer configurations.
| Parameter/Feature | Description |
|---|---|
| MinCommit | This setting allows you to change the frequency and kickoff of a commit. Changing this setting may reduce CPU load and disk I/O. Use the command update db cfg for <insert DB_NAME> using mincommit <new setting> . Refer to Chapters 13 and 14 and the previous section of this chapter to understand what commands you can use to monitor this setting. |
| MaxAgents | This setting allows you to tune the number of active connections into the DB2 database. This setting should be tuned in conjunction with your queuing model, focusing on your JDBC connection pool manager. Also, you should ensure that MaxAgents is at least the same value as MaxAppls. Consider your maximum connections from all your JDBC providers, multiplied by the number of application servers using the JDBC providers and then by the number of clones . |
| BuffPage | This is a DB2 setting that affects the buffer hit ratio of your DB2 database. The buffer hit ratio should be no less than 95 percent. Use this in conjunction with the following three settings. |
| SortHeap | This setting tunes the query engine for applications that may conduct a lot of sorting within their SQL queries. This can help with databases to reduce CPU loading. |
| Query Heap | You can use Query Heap (variable query_heap_sz ) similarly to SortHeap to provide more buffer space for queries. If you have a high transaction rate, this value can help to improve performance of inbound queries. |
| Logbufsz | This setting allows you to cache or buffer data for a period before writing to logs. Increasing this value can decrease I/O loading to disks. |
| Pckcachesz | This value allows you to tune the amount of buffer allocated to both static and dynamic SQL statements. Tuning this value can improve the efficiency of SQL queries, especially for high transaction rate platforms. |
Again, use this table as a guideline, but don't take each setting for granted. Because the details of these settings are beyond the scope of this book, take the time to understand and research what each setting means and does. Most of these settings are quite common; however, these specific groupings of settings best support WebSphere performance. You can change these settings via the DB2 CLP tool or via the DB2 Control Center application.
Table 11-6 isn't an exhaustive list, but it does provide a guide for tuning DB2 for WebSphere-based application environments.
Monitoring Oracle and DB2 for Performance Issues
You can use a number of tools to understand the current load and state of your database. I'll explore this in more detail during Chapter 13, but Table 11-7 provides an overview of the best-suited applications.
| Tool | Monitoring Purpose | Targeted Database |
|---|---|---|
| iostat | The iostat command monitors disk activity, including utilization. This is useful when there are disks being overly utilized or bottlenecking overall performance. | DB2 and Oracle on Unix platforms |
| netstat | The netstat command provides the capability to understand the number of active Transmission Control Protocol (TCP) or User Datagram Protocol (UDP) connections to your database. It can help reveal socket exhaustion or overloading of inbound network activity. | All databases, all operating systems |
| vmstat | The vmstat command provides a number of features to help understand the status of the system load, memory swapping, and disk load. This is useful when your system is bottlenecking in a single-view application. | Available on Unix operating systems for DB2 and Oracle |
| Windows Performance tool | The Performance tool in Windows NT, XP, 2000, and 2003 provides a graphical view of the state of disk, CPU, network, and swapping within your Windows-based server environment. | Available for DB2 and Oracle on Windows-based platforms |
As noted, you'll explore each of these, and more, in detail in Chapter 13 when you see how to actually use the tools and understand their output.
EAN: 2147483647
Pages: 111