J2EE Database Integration
In the Java 2 Enterprise Edition (J2EE) world, there's many ways to do everything! The same goes for database connectivity. I'll discuss the two types of integration in the following sections. First, you'll look at the four common ways to communicate to a database from within your application code. That is, how do you implement SQL queries to your relational database? Second, you'll look at two connectivity driver types that are commonly used within WebSphere environments.
So, you'll now look at the SQL implementation methods used within WebSphere, learn about the pros and cons of each, and understand when, where, and how you should use them.
Persistence Layer Implementation
The two primary ways of utilizing the J2EE capability of default persistence layering are with Container Managed Persistence (CMP) and Bean Managed Persistence (BMP). Both are commonly used globally, and both have specific pros and cons, including areas that you should investigate for performance optimization.
Container Managed Persistence (CMP)
CMP is a fairly contentious subject when it comes to J2EE and database connectivity. Essentially , CMP is a WebSphere-managed, or container-managed, persistence layer that manages the SQL statements and data persistence between the business components ”in other words, the entity Enterprise JavaBeans (EJBs) ”and the database.
The reason why CMP is contentious is that it's a "black box" to the developer and, to a large extent, the system manager. In theory, it's rock solid. If you've performed any Java development work before that requires a fair amount of SQL code, you know that implementing SQL code can be cumbersome at times. The concept behind CMP is that the developer writes against a series of J2EE EJB Application Programming Interfaces (APIs) that allow interrogation of the database via an abstract layer. For example, if a developer wanted to find a specific entry in a database, he would create an entity EJB and include methods such as findByPrimaryKey , which would allow him to search the database for a particular row via the call findByPrimaryKey(primary_key) .
However, in practice, entity EJBs, when incorrectly implemented, can be a performance killer on the database and WebSphere application server tiers. Unlike most other J2EE components, the entity EJBs are "sessionized" within the context of a client (or user ) transaction. The entity EJBs are then cached (just the wrapper, not the object data itself) at the end of each client transaction, which is a key component of EJB life cycles (in other words, session, stateless, and entity EJBs). Clearly, however, this depends on the EJB caching strategy and general cache options (for example, the time in cache).
In the past (pre-EJB 2.0), the problem with container-managed entity EJBs was that there was significant overhead associated with the synchronization of the persistence layer (between the entity EJBs and the database). The EJB 2.0 specification that arrived with J2EE 1.3 (within WebSphere 5) provides a great deal better performance over that of the entity beans in EJB 1.1 (within WebSphere 4). Local EJB interfaces, new in EJB 2.0, have played a bit part in this performance improvement.
Even so, you can tune a number of items within WebSphere to help improve CMP performance. In Chapter 10, I'll discuss the specific details of code-level EJB performance tuning. In this chapter, you'll see what you can do with CMP entity EJBs, once they're deployed, in a production environment.
Before getting into the EJB container tuning of CMP, though, you'll look at BMP.
Bean Managed Persistence (BMP)
BMP, unlike CMP, requires that the developer creates the persistence layer using entity EJBs. The developer needs to implement all the database SQL routines and various finder methods within the entity EJBs.
Out of all the various data persistence layer mechanisms, the BMP technology is probably the most involved to develop and manage. The performance, overall, is somewhat the same between CMP and BMP ( assuming both have been implemented correctly); however, BMP provides an additional level of flexibility over that of CMP because the developer can code the persistence layer the desired way.
From my experience, BMP is higher performing than CMP for high write-based environments, and CMP, for the majority of situations, outperforms BMP for high read-based environments. This is only because of the default implementation nature of CMP and the way in which the container-managed persistence layer retrieves the relational data from the database. CMP has a caching-like data persistence architecture, more so than that of CMP. You can make BMP perform in the same fashion because, by its nature, BMP uses many of the same ideologies as CMP. The major difference is that the developer has to implement the persistence management.
BMP, overall, is good for circumstances where your developers may want to implement a nonstandard persistence layer ”one that isn't specifically handled by CMP.
Tuning Your CMP and BMP EJB Environments
In Chapter 9, I discussed EJB caching. As a refresher, EJB caching is the technology, as part of the J2EE EJB specification, pertaining to the container's support of caching EJB communications between client transactions. In essence, the WebSphere EJB containers support three types of EJB caching known as Option A, Option B, and Option C. You'll now look at these in the context of entity EJBs.
Option A caching assumes that the particular entity EJBs have exclusive access to the underlying data store ”the database. During active client transactions, no changes to the underlying data structure can be facilitated.
Option A shouldn't be used with any form of WebSphere clustering or workload management. Introducing one of these groups of high-availability technologies means you may introduce changes to the data store, effectively "breaking" the active entity EJBs. Using this caching option (Option A) with a truly read-only entity EJB paradigm will result in a dramatic improvement in performance. The challenge is to ensure that the entity EJB constructs are in fact read-only.
Option B caching, unlike Option A, allows for shared access to the underlying data store or the database. After each client transaction, the entity EJB synchronizes data back to the database (via the ejbStore() method), and the instance of the entity EJB remains active and is returned to the contain pool after a client transaction has completed.
The final option, Option C, is similar to Option B in that it allows shared access to the database or data store between other entity EJBs. The difference, however, is that at the end of each transaction, the container passivates the EJB. Passivation is when the EJB method closes down an instance of an EJB. In this option, when the next client transaction requests an EJB from the pool, the container creates a new entity EJB.
From this, you can choose from the three options per entity EJB implementation type. I find the most efficient way to modify this setting is to edit the IBM extension's EJB Java Archive (JAR) descriptor for your specific EJBs. It's possible, and recommended if you're less familiar with this area of WebSphere, to do this at deployment time through the assembly tools provided by WebSphere.
Each EJB is detailed in a file called ibm-ejb-jar-ext.xmi . This file is the IBM extension deployment descriptor for EJBs deployed in WebSphere.
| Note | This file will only be present if you've initially created it when deploying an EJB JAR application. |
The file contents will look similar to the following line:
<beanCache xmi:id="BeanCache_5" activateAt="TRANSACTION" loadAt="TRANSACTION"/>
Each EJB you deploy and configure with EJB caching will have a similar entry in this file per EJB JAR. BeanCache_5 represents the iteration of EJB cache entries in that particular file. Unless you know or are confident with what you're editing, it's best to change these settings via the assembly tools.
Table 11-3 defines the three configuration items available.
| Option | Activation Settings | Load Settings |
|---|---|---|
| Option A | Once | Activation |
| Option B | Once | Transaction |
| Option C | Transaction | Transaction |
Option C is the default option for these settings. That is, if you don't specifically configure the EJB caching, Option C is used.
Note that you must use each setting in the combination that's mentioned in Table 11-3. That is, if you manually edit the IBM extension's deployment descriptor and change the EJB cache setting to, let's say, Option B, you must set it as follows :
<beanCache xmi:id="BeanCache_5" activateAt="ONCE" loadAt="TRANSACTION"/>
-
You can't mix and match the activateAt and loadAt settings. Use these tips to identify what setting works best for you:
-
Option A is only possible on single-channel, single-instance, noncloned WebSphere environments. It's quite fast given that the bean isn't returned to the EJB pool, meaning that an ejbLoad() isn't called on each client transaction, greatly improving performance.
-
Option B, as a general rule, is the next best option. It can be used in workload management-based (clustered) environments. Although each client transaction incurs an ejbLoad() call to obtain cached EJBs from the pool, there's no ejbActivate() called. Essentially, this option greatly reduces the number of methods called to the EJB container constructs over that of Option C.
-
Option C is the safest, or most generalized, caching method. Each time a call to an entity EJB is requested , the container must create a new entity EJB instance. Given that the EJBs aren't sitting in memory the whole time (unlike Option A and B), this option uses less memory. However, there's a performance hit if you're using entity EJBs frequently.
At the risk of sounding like a broken record, these are only guidelines and are recommendations based on my experience. In other words, test, test, test. If you have a simple, nonclustered environment, Option A is the best choice. If you have clustering or workload management active and your developers utilize entity EJBs frequently, Option B is the best. If you have clustering or workload management active yet don't rely on entity EJBs, Option C is the most memory friendly.
Embedded SQL
Embedded SQL is a quick-and-dirty (albeit sometimes completely legitimate !) way of compiling SQL queries and commands within your application code. As you can probably guess, SQL code is simply hard-coded into the deployed application classes. There's no management of the persistence mechanism, but it can use features such as connection pooling and the like. The primary reason why I recommend you push your developers away from this method is just as much about performance is it is good (or best) practice.
For small applications that conduct only one or two queries, you can use basic SQL queries without too much of an impact. An example is a simple select or insert statement such as this:
SQL> select phone_number from user_table where user_ID = '123456';
The problems start to arise when you have many or complex queries and SQL commands being used and high-volume environments. Trying to maintain and write Java code with unmanageable amounts of static SQL commands is impossible . If you're constrained to using embedded SQL commands, then my recommendations are somewhat straightforward.
| Note | I discuss these concepts in more detail in Chapter 10. |
Prepared SQL Statements
You could safely assume that a system using embedded SQL commands would be a smaller size than a system using CMP or Data Access Objects (DAOs). However, small systems can expect failures in the same fashion as large systems. In some cases, the costs of failures in smaller systems are, unit for unit, greater than that of large systems. This is because problems occur longer after deployment because the load and volume of usage is typically lower. Therefore, it's important to use common sense regarding performance.
Specifically, use prepared SQL statements. It's easier to maintain a handful of prepared SQL statements rather than a large collection of them. Prepared SQL statements work when only the statement, without the data, is passed to the database layer. This causes the database to see that the statement has been issued and compiled previously (a previous request) and, therefore, doesn't need to parse and compile the statement again. The key with databases is to minimize the disk seek time and parsing and compilation time by pushing requests into cache.
Smaller environments can benefit greatly from this approach, and you won't have to purchase a large environment. I'll discuss this in a little more detail in Chapter 10.
As a guide, use prepared SQL statements for SQL statements that will transact fewer than 15 or so similar queries or calls to the database. If you find that you'll have many of the same SQL calls made to the database by your applications ”more than 20 ”prepared SQL statements will start to become better performing than standard SQL statements.
Having WebSphere manage connections for less time to the database means that overall performance is increased (less overhead on the pool manager), fewer threads are used, and memory utilization is decreased by transactions completing faster. It's possible to see a 70 “90 percent improvement in speed for smaller WebSphere environments and a 50 “70 percent improvement for larger WebSphere environments when using prepared SQL statements.
SQL Statement Management
Given that the use of embedded SQL commands implies hand development of code, it's important that your developers do in fact follow the rules discussed in Chapter 10 about closing all connections and statements at the end of each SQL query set. In more advanced configurations, your developers may implement helper beans or use DAOs where all the database connectivity plumbing work is taken care of (the connection, closure, and so on).
If this isn't the case, then you'll need to ensure that statements are closed. By not doing so, one of two things will happen (and probably both). First, by not closing statements, your WebSphere application server's Java Virtual Machine (JVM) will show signs of memory leaks. Statements have "handles" open to them (they're essentially objects, remember), and by not declaring them closed, they remain open , even if the statement has finished processing.
Second, by not closing the connections to the database or the pool manager, you'll quickly find that you'll run out of available connections to the database. Over time, if you're using a pool manager, it'll help by closing idled or orphaned connections (see Chapter 9) when they're unused for a defined duration. However, if your developers aren't using pool managers and not closing connections, you'll run out of connections to the database (or more correctly, the database will run out of available connections).
The following code shows an example of proper object closure:
// establish new connection object connection conn = null; // set the JDBC class Class.forName("some.driver.string"); // build up the JDBC connection URL conn = java.sql.DriverManager.getConnection("jdbc:some_jdbc_connection_url"); Statement stmt=conn.createStatement(); ResultSet rs = stmt.executeQuery("select * from username; ") ; // position us in our resultset object rs.last(); int count = rs.getRow(); rs.first(); while (!rs.isAfterLast()){ out.println(rs.getString(1)) ; out.println(rs.getString(2)) ; out.println("\n") ; rs.next(); } // close result set object rs.close(); // close statement stmt.close(); // close conection conn.close(); Don't worry too much about understanding this code; it's provided merely as an example. The important aspects are the last three Java commands:
-
The first command, rs.close() , closes the result set object that was used to store the results of the query. This primarily reduces memory consumption.
-
The second command, stmt.close() , closes the stmt (or statement object) that was used to build the query. This also reduces memory consumption by cleaning up unwanted objects.
-
The last command, conn.close() , closes the JDBC database connection. This reduces memory as well as removes an active connection to the database, preventing it from connection exhaustion.
Using prepared SQL statements and closing objects and connections to the database are the essential WebSphere performance winners when using embedded SQL.
As noted, I discuss more SQL generic performance guidelines in Chapter 10. Later in this chapter, you'll look at specific database tuning options you can employ to help SQL queries perform better.
| Tip | If you're placing SQL statements into your Java code, best practices suggest placing object dereference methods (for example, resultset.close() ) into your Finally clause. If you're using other forms of JDBC code development such as DAOs, you can build these closure methods into factory classes or part of your value object management. |
Data Access Objects (DAOs)
DAOs are essentially a pattern in object-oriented design. In the context of databases and database access, DAOs provide a high level of abstraction to the developer. This means you can have a core developer write the actual database connection logic within a DAO construct, and the regular business developers can simply communicate to the database abstraction layer.
The abstraction layer is presented by the DAO, assuring you that any performance and optimization logic implemented by the core developer in the DAO data source logic will be used inherently . Figure 11-1 highlights how this works.
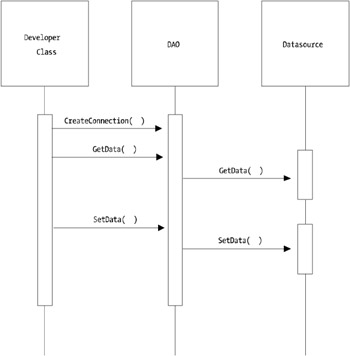
Figure 11-1: Example DAO pattern implementation
Essentially, Figure 11-1 shows how the interaction between a developer bean or some other Java component communicates to a database of any sort via the DAO.
Apart from being about insulating business component developers from the plumbing and having a centralized interface to get data to and from a database, it also shows a very abstracted model. If you wanted or needed to change your database vendor from, let's say, Sybase to Oracle, you'd only have to get your core developer to change the one location in the DAO where the database connectivity may occur. Typically, this is handled within WebSphere JDBC pool manager, and as such, all that would need to be changed is the Java Naming and Directory Interface (JNDI) name of the data source.
This is a high-level look at DAOs ”a topic that's beyond the scope of this book. However, from a conceptual point of view, the concept should be one with which you're familiar.
In terms of ensuring performance, the key to performance in a DAO-based environment is in the connection manager. Because a DAO predominantly would use a JNDI context lookup to find a predefined connection manager for a specific data source, the pool manager is the essential performance factor. Later in this chapter, you'll look at what you can do within WebSphere JDBC connection pool managers to optimize database connectivity.
| Note | For those with good eyes or an interest in patterns, Figure 11-1 doesn't show the complete DAO pattern. A key component missing is the ValueObject element. |
JDBC
JDBC is the standard J2EE/Java database driver used to communicate and interrogate a relational database. Java 2 Standard Edition (J2SE) JDBC 3.0 supports the SQL-99 command set, meaning that it's compatible with all the major relational database vendors and more.
JDBC in itself is any one of four driver types, known as JDBC type 1 through 4. Each driver level is a different incarnation or implementation of the JDBC. Each driver has its own reason for existence, along with its pros and cons.
You'll now take a quick moment to look at the four different JDBC types.
JDBC Type 1
JDBC type 1 is a JDBC-ODBC bridge. This version of driver is rare to use or find and in fact isn't supported under WebSphere.
The complexity in this driver is that all JDBC calls made to the driver are bridged to an internal ODBC driver, which then converts the calls to the native database vendor implementation driver before sending them onto the database. Figure 11-2 shows how the communication to a type 1 driver works.
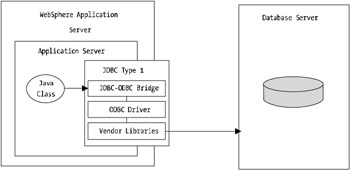
Figure 11-2: JDBC type 1 driver implementation
As you can see, there's a fair amount of abstraction in this type of driver. It should be obvious that there will be performance implications for the multiple levels of abstraction and command translation within the driver.
Overall, this driver shouldn't be used because of its inherent performance issues.
JDBC Type 2
JDBC type 2 drivers are quite common within application environments. WebSphere supports this form of driver, also commonly known as a thick driver. In essence, the thick driver implements local or vendor-specific APIs in the driver, which provide a high level of performance over that of type 1 drivers.
This driver, given that it implements vendor-specific or native APIs within the driver library, can take advantage of vendor-specific features and functions. In the case of Oracle, a thick JDBC driver incorporates Oracle Call Interface (OCI) libraries within the driver.
Having the vendor-specific APIs in a type 2 driver means you can take advantage of load balancing and failover of your WebSphere applications as well as other advanced features. I'll discuss some of these in more detail later in this chapter. Figure 11-3 shows the type 2 JDBC driver implementations .
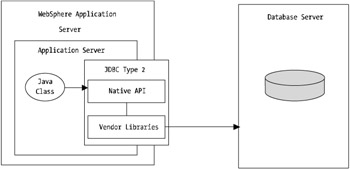
Figure 11-3: JDBC type 2 driver implementation
As you can see, unlike a type 1 driver, the type 2 implementation provides fewer layers to extend through, which ultimately provides far greater performance, with the added advantage of gaining vendor-specific capabilities such as Oracle OCI feature sets.
JDBC Type 3
Type 3 drivers are less common than types 2 and 4 but more common than type 1 drivers. Although the type 3 driver is nowhere near as common as types 2 and 4, it does have some smart features. But, again, with more layers, it's more involved to manage and support.
Suited well to client/server implementations where thick Java clients such as those using Java Swing or Abstract Window Toolkit (AWT) are used, this implementation of JDBC uses a three- tier approach. Figure 11-4 highlights this model.
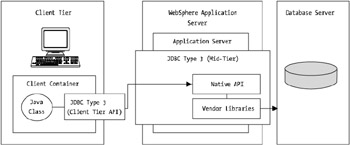
Figure 11-4: JDBC type 3 driver implementation
As you can see from Figure 11-4, the driver is split into three tiers. Interestingly, the middle tier may actually operate a type 1 or 2 driver while on the first tier, and then the pure-Java driver will ferry the JDBC-based request to the middle tier, which in turn will push it to the database.
This driver, because it can use existing type 1 and 2 driver implementations, provides the ability to use load balancing, failover, and other advanced features.
It also provides you as the WebSphere manager or operations architect with the ability to facilitate logging and auditing, given that the driver's client component can be written from scratch or modified from existing reference implementations.
The only performance issue with this model of driver is that because there are more tiers and more layers of technology to traverse, returning data sets will take longer to arrive on the client end. As such, large result sets will not perform as well with a type 3 driver as they would with a "thinner" driver.
JDBC Type 4
The JDBC type 4 driver, more commonly known as the JDBC thin driver, is a fully supported driver under WebSphere 4 and 5. Most major database vendors provide this form of driver, which is effectively a native Java-based driver.
For the majority of implementations, this driver is the highest performer. Because calls to the database layer don't have to be translated into an ODBC call or some other form of propriety protocol, the overhead is kept to a minimum.
Unfortunately, however, for the most complex environments where technologies such as advanced failover, load balancing, and so forth are required, this driver will not be able to provide vendor-specific capabilities. Although some vendors do incorporate connection-based failover into a type 4 driver, for the majority, the type 4 driver is a basic, high-performing JDBC interface to the database layer. Figure 11-5 shows just how simplistic this form of driver is.
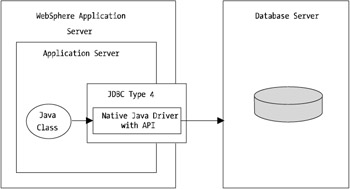
Figure 11-5: JDBC type 4 driver implementation
Still, type 4 drivers have a number of aspects that can affect performance. I'll discuss optimization in more detail later in the chapter when discussing connection pool managers.
ODBC
From an architectural purist's perspective, ODBC-based drivers are a less pure form of database connectivity. ODBC is a standard introduced by Microsoft many years ago to provide a programmable interface to its various SQL-compliant databases (Microsoft Access and, more recently, SQL Server).
Nowadays, if you're using databases with Java environments, the rule of thumb is that you don't use ODBC for database communications. Instead, you choose either type 2 or type 4 JDBC-based drivers. However, you can bend this rule where some more specialized data services vendors don't favor either JDBC or ODBC or they have limited support for JDBC, in which case you'll need to use ODBC.
If this is the case, then you're not out in the cold by yourself! WebSphere does support ODBC integration through its resource groups. The specific tuning and optimization of these types of interfaces is driver specific.
In most cases, refer to your ODBC driver vendor's documentation to understand what the driver settings should be and how they should be configured.
EAN: 2147483647
Pages: 111
- The Second Wave ERP Market: An Australian Viewpoint
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- Distributed Data Warehouse for Geo-spatial Services
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare