11.3 Sets
| Unlike other implementations of the Collection interface, implementations of the Set interface do not allow duplicate elements. This also means that a set can contain at most one null value. The Set interface does not define any new methods , and its add() and addAll() methods will not store duplicates. If an element is not currently in the set, two consecutive calls to the add() method to insert the element will first return true , then false . A Set models a mathematical set (see Table 11.3), that is, it is an unordered collection of distinct objects. Multisets (a.k.a. bags ) that allow duplicate elements cannot be implemented using the Set interface since this interface requires that elements are unique in the collection. Table 11.3. Bulk Operations and Set Logic
HashSet and LinkedHashSetThe HashSet class implements the Set interface . Since this implementation uses a hash table, it offers near constant-time performance for most operations. A HashSet does not guarantee any ordering of the elements. However, the LinkedHashSet subclass of HashSet guarantees insertion-order. The sorted counterpart is TreeSet , which implements the SortedSet interface and has logarithmic time complexity (see Section 11.6, p. 452). A HashSet relies on the implementation of the hashCode() and equals() methods of its elements (see Section 11.7, p. 461). The hashCode() method is used for hashing the elements, and the equals() method is needed for comparing elements. In fact, the equality and the hash codes of HashSet s are defined in terms of the equality and the hash codes of their elements. As mentioned earlier, the LinkedHashSet implementation is a subclass of the HashSet class. It works similarly to a HashSet , except for one important detail. Unlike a HashSet , a LinkedHashSet guarantees that the iterator will access the elements in insertion order , that is, in the order in which they were inserted into the LinkedHashSet . The LinkedHashSet class offers constructors analogous to the ones in the HashSet class. The initial capacity (i.e., the number of buckets in the hash table) and its load factor (i.e., the ratio of number of elements stored to its current capacity) can be tuned when the set is created. The default values for these parameters will under most circumstances provide acceptable performance. HashSet() Constructs a new, empty set. HashSet(Collection c) Constructs a new set containing the elements in the specified collection. The new set will not contain any duplicates. This offers a convenient way to remove duplicates from a collection. HashSet(int initialCapacity) Constructs a new, empty set with the specified initial capacity. HashSet(int initialCapacity, float loadFactor) Constructs a new, empty set with the specified initial capacity and the specified load factor. Example 11.2 Using Sets import java.util.*; public class CharacterSets { public static void main(String[] args) { int numArgs = args.length; // A set keeping track of all characters previously encountered. Set encountered = new HashSet(); // (1) // For each program argument in the command line ... for (int i=0; i<numArgs; i++) { // Convert the current argument to a set of characters. String argument = args[i]; Set characters = new HashSet(); // (2) int size = argument.length(); // For each character in the argument... for (int j=0; j<size; j++) // add character to the characters set. characters.add(new Character(argument.charAt(j))); // (3) // Determine whether a common subset exists. (4) Set commonSubset = new HashSet(encountered); commonSubset.retainAll(characters); boolean areDisjunct = commonSubset.size()==0; if (areDisjunct) System.out.println(characters + " and " + encountered + " are disjunct."); else { // Determine superset and subset relations. (5) boolean isSubset = encountered.containsAll(characters); boolean isSuperset = characters.containsAll(encountered); if (isSubset && isSuperset) System.out.println(characters + " is equivalent to " + encountered); else if (isSubset) System.out.println(characters + " is a subset of " + encountered); else if (isSuperset) System.out.println(characters + " is a superset of " + encountered); else System.out.println(characters + " and " + encountered + " have " + commonSubset + " in common."); } // Update the set of characters encountered so far. encountered.addAll(characters); // (6) } } } Running the program with the following arguments: java CharacterSets i said i am maids results in the following output: [i] and [] are disjunct. [d, a, s, i] is a superset of [i] [i] is a subset of [d, a, s, i] [a, m] and [d, a, s, i] have [a] in common. [d, a, s, m, i] is equivalent to [d, a, s, m, i] Example 11.2 demonstrates set operations. It determines a relationship between two sets of characters:
Given a list of words as program arguments, each argument is turned into a set of characters. This set is compared with the set containing all the characters encountered prior to the current argument in the argument list. The set keeping track of all the characters encountered prior to the current argument, is called encountered . This set is created at (1). For each argument, a set of characters is created, as shown at (2). This set, called characters , is populated with the characters of the current argument, as shown at (3). The program first determines if there is a common subset for the two sets, as shown at (4): // Determine whether a common subset exists. (4) Set commonSubset = new HashSet(encountered); commonSubset.retainAll(characters); boolean areDisjunct = commonSubset.size()==0; Note that the retainAll() operation is destructive. The code at (4) does not affect the encountered and the characters sets. If the size of the common subset is zero, the sets are disjunct; otherwise , the relationship must be narrowed down. The subset and superset relations are determined at (5) using the containsAll() method. // Determine superset and subset relations. (5) boolean isSubset = encountered.containsAll(characters); boolean isSuperset = characters.containsAll(encountered); The sets are equivalent if both the previous relations are true. If they are both false, that is, no subset or superset relationship exists, they only have the common subset. The set of characters for the current argument is added to the set of all characters previously encountered. The addAll() method is used for this purpose, as shown at (6): encountered.addAll(characters); // (6) Textual representation of a set is supplied by the overriding method toString() in the AbstractSet class on which the HashSet implementation is based (see Figure 11.2). |
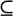 a (subset)
a (subset)  b (union)
b (union) 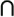 b (intersection)
b (intersection) EAN: N/A
Pages: 284