TEXT CODING AND EXPERIMENTS
This section explains the influence of word coding on the properties of CMM. Two proposed method of coding are also defined. Experiments comparing those coding methods are shown.
The important part of the described technique is transforming input words into a binary form. We need to impose some restrictions on input data in order to improve the behavior of the matrix. The input data should be sparse and orthogonal. It allows for filling the matrix regularly (with uniform distribution). It increases the capacity of CMM and also improves its ability to deal with corrupt patterns. The real text without any preprocessing does not have these optimal properties.
Simple Text Coding
Figure 3 shows the frequencies of letters in English text where word duplicities are omitted. That is more suitable for CMM, because each word is trained just once. The simple text coding could not be efficient. For example, the most frequent letter ˜e is 81 times more frequent then the letter ˜z . Simple coding does not take into account this fact. Therefore, it generates saturated locations in the matrix during the learning process. These locations consequently cause faults when recalling.

Figure 3: Histogram of Letters for Non-Repeated English Words
In our experiments, we have tested three types of coding. The first one is a simple coding. It divides input words into letters that are then coded independently. Each letter on a particular position is assigned with only one logical 1 in the binary vector. This simple coding does not provide for changes to the distribution of the letters so it does not have good properties for the matrix.
Proposed Text Coding
In this subsection, we describe two codes for the real text. The aim is to eliminate the inappropriate properties of the real text. The name of the first coding is "coding by equal intervals". The idea of this coding method is the division of the trained set into several intervals of equal, or almost equal ( differs at most by one), parts . The intervals are produced for each symbol (a letter) of the patterns. Each position generates a sub-code that is given by putting the letter under the particular interval. These sub-codes are then concatenated to obtain the whole code word for CMM.
In order to get intervals for the first letter, we sort the patterns in lexicographic order. We divide this list into intervals of equal length. The second group of intervals we achieve in a similar way. The only difference is that we sort the patterns starting from the second letter. The first letter of patterns is moved after the last letter, etc. The code word for the first letter is then determined by the interval (of the first group) to which the letter belongs.
For the recalling process, we need to remember the words on the boundaries of the intervals. So, we need the additional information stored in a memory (apart from storing the associations to CMM). We find out which interval belongs to the word by comparing the word with the boundary of the intervals. We can use the binary search method, particularly for more intervals. This type of coding partly eliminates the inappropriate character of the real text ” big frequency differences among individual letters. Therefore, we code equal intervals, instead of letters. The drawback of this method is that it takes a lot of time to create the intervals. For words of length D , we need to sort all set of words D -times. But, the advantage of this coding is that it maintains the ability of the matrix to recall incomplete corrupt patterns. We will use this ability for approximate searching.
The second proposed coding is called "coding with random shift" (Tregner, 1999). This method adds a pseudorandom number to each letter in the pattern. The operation module (with the size of the alphabet) is then applied on the summation. The result is then processed by the 1 of N code. This coding gives us nearly uniform distribution over the patterns passing to CMM. We need the same pseudorandom numbers to get the same code for the recalling process. Thus, the random numbers for letters in a word should be generated from the word.
We use the summation of ASCII codes of letters in the word as the seed for a pseudorandom series. This summation is the only linking point of a particular pattern for both the training and recalling processes. This coding is simple and efficient. Unfortunately, this method cannot work with a corrupt word. If there is only one letter modified in the input word, we obtain an incorrect seed for the pseudorandom series. That will cause all the letters to be decoded to incorrect numbers, and the recalling pattern will be completely different from the original one. The solution could be in getting the seed in another way. We can obtain it, for example, from the first two letters of the words. Then, the value of the seed will be sensitive only to the first two letters of words. However, this way loses the desired uniform distribution.
The graph (in Figure 4) shows a big difference between simple text coding and the two proposed methods of coding. The simple text coding does not provide uniform distribution of code words in the alphabet. Words containing more frequent letters cause locally oversaturated places in the matrix. These locations result in more faults during the recalling process (capacity drops ). The method of "equal intervals" gives almost the same result (slightly better) with the method of "random shift".
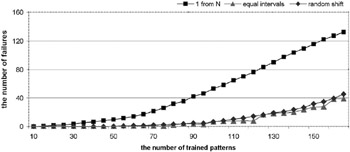
Figure 4: The Comparison of Three Methods of Coding
In order to obtain more uniform distribution of ones in the matrix, we tried coding two neighboring letters as one symbol. The distribution of code words for two letters is much better compared to the one-letter coding. However, it is still far from the uniform distribution.
Speed Comparison
We have compared the speed of the CMM technique to the Boyer-Moore algorithm (Mraz, 2000). Figure 5 illustrates the results of this test. We also tested the CMM technique on a dedicated CMM hardware accelerator. This board was developed at the University of York (Austin & Kennedy, 1995).
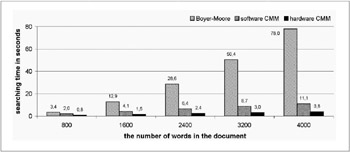
Figure 5: The Comparison of Speed of Conventional Techniques and CMM
We used the following parameters for the CMM technique: word length was 6, the number of ones in the input vector was 6, the matrix size was 192 x 192 bits, and we used L-max thresholding . For a more detailed description, (see Mraz, 2000). The test shows that the conventional technique, Boyer-Moore, is significantly slower for use with more words in text documents. The reason is the linear processing of Boyer-Moore algorithms. Using a hardware accelerator of CMM is approximately three-times faster than using a software simulation of CMM.
EAN: N/A
Pages: 171