TECHNIQUE DESCRIPTION
In this section, we describe the principle of the technique based on binary neural network as well as on CMM itself. Usually, a fast conventional technique is used for text searching tasks , e.g., Boyer-Moor or Shift-or algorithms. Conventional techniques go through text and compare it with a searched pattern. Our technique is based on storing associations between words and their location in the text. The association is stored in CMM. This approach is similar to techniques such as inverted file lists or hash tables (Hodge & Austin, 2001).
Our approach is shown in Figure 1. It operates in two phases ” the learning and the recalling. The learning phase stores associations between words and their positions in the text document. The recalling phase searches for a query word. In fact, there is no search during the recalling phase; it simply recalls a proper association.
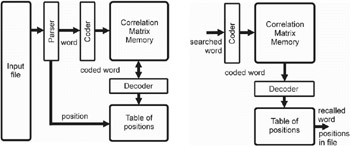
Figure 1: Learning (left side) and Recalling (right side) Phase of the Technique
In the learning phase, the parser goes trough the text and cuts off the words. All words are coded and pass their code word to the input of the CMM. Coding input words significantly influences properties of CMM and the recall process. It checks whether the input word has been already learned. If it has, the word is learned no more; but its position in the text is added to a proper entry of the position table. Otherwise, a code for this word is produced and put at the output of CMM. Then, a new association is learned, and a new entry in the position table is added. The position table contains entries for all learned words. Each entry in the table consists of positions for the particular word. The code addresses the proper entry in the position table.
In the recalling phase, an input word is coded in the same way as it is during the learning phase, and the result is applied to the input of CMM. CMM then recalls the association or answers that there is no association for this pattern. If CMM gives a represent code, it is then decoded to obtain the address in the position table. The entry contains all positions of the query word in the text document.
Correlation Matrix Memory
Correlation Matrix Memory is an associative memory. It allows information to be stored in a content-addressable way. The information that memory stores are the associations between an input and an output. The associative memory has similar properties to other forms of neural networks: the ability to learn, the ability to generalize, inherent parallelism. We use the correlation matrix memory with binary elements. This type of CMM is called weightless, or binary, CMM. It means that both the inputs and the weights of the network are binary (0 or 1). Because of binary processing, CMM is a fast neural network. While some other neural networks require a long time for training, its learning process is not iterative (it uses so-called "one shot" learning process).
The learning process starts with all elements of the matrix set to 0. The matrix is formed by the superposition of the outer product matrices created from the training pairs. Superposition means applying the logical or of the matrices.
Learning is evaluated as follows (see also Figure 2):
where the operator ˆ means logical or over its arguments (of binary type), a is the input pattern, b is the output pattern, and p is the number of associations. For a more detailed description (see O'Keefe, 1997).
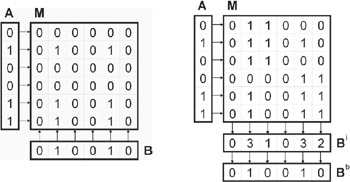
Figure 2: Learning (left side) and Recalling (right side) Phases of CMM
The recalling process is done in two steps. First, an integer vector is evaluated from the summation of some rows of the matrix. Then, the integer vector is thresholded to obtain an output binary vector. Those rows of the matrix are chosen for the summation, which correspond to the ones in the input vector. The integer ( accumulating ) vector is given by:
where M is the binary matrix and r is the integer vector. Then, the thresholding process is applied to the integer vector. Thresholding evaluates the binary vector. Thresholding influences the ability of CMM to reject noise ” to answer correctly to an incomplete input pattern. Thresholding also adds a nonlinear aspect to the recalling process. There are several types of thresholding. In our tests, we use so-called L-max thresholding .
L-max thresholding is based on a presumption that all output vectors have a constant number of ones. It implies that we do not need to care about the values in the summation vector. We simply choose L biggest values in the integer vector and set the corresponding bits in the output binary vector to 1.
Table 1 shows an example of L-max thresholding for L = 2. We can see from the table that the technique could produce an uncertain output in special cases. In such cases, we choose a random one. An appropriate coding of output vectors could distinguish correct patterns.
| Integer vector | Output binary vector and its alternatives | ||
|---|---|---|---|
| 3 3 2 1 | 1 1 0 0 | - | - |
| 3 1 2 0 | 1 0 1 0 | - | - |
| 3 3 2 3 | 1 1 0 0 | 0 1 0 1 | 1 0 0 1 |
There is a mechanism commonly applied to an input vector before it is put to the matrix. It processes input binary vectors and converts them into a form with more manageable properties. This mechanism is called n-tuple preprocessing . It divides the input vector into n parts (called tuples), which are independently coded. The coded tuples are concatenated to produce the whole input vector of the matrix. The tuples have the same length. They are coded by the "1 of N" code. This code has two useful properties for behavior of the correlation matrix. Firstly, it transforms the arbitrary number of ones in the input vector into the constant number of ones (equal to number of tuples). Secondly, it produces a vector that is sparser then the original one.
Capacity of CMM
As mentioned above, CMM associates pairs of input and output vectors. Clearly, it is able to associate just a certain number of the associations. After that limit, CMM starts recalling incorrectly. This limit depends on the size of matrix as well as on the character of trained pairs. The capacity of CMM can be defined in several ways. We adopt the definition of O'Keefe (1997), which measures capacity as the number of trained pairs when the probability of correct output is 0.5. For this probability, the number of trained associations is given by:
where T is the number of trained associations, R is the number of elements in the input vector, NI is the number of bits set in the input vector, H is the number of elements in the output vector, and N is the number of bits set in the output vector.
EAN: N/A
Pages: 171