FEATURE SELECTION IN UNSUPERVISED LEARNING
In this section, we propose a new approach to feature selection in clustering or unsupervised learning. This can be very useful for enhancing customer relationship management (CRM), because standard application of cluster analysis uses the complete set of features or a pre-selected subset of features based on the prior knowledge of market managers. Thus, it cannot provide new marketing models that could be effective but have not been considered. Our data-driven approach searches a much broader space of models and provides a compact summary of solutions over possible feature subset sizes and numbers of clusters. Among such high-quality solutions, the manager can select a specific model after considering the model's complexity and accuracy. Our model is also different from other approaches (Agrawal et al., 1998; Devaney & Ram, 1997; Dy & Brodley 2000b) in two aspects: the evaluation of candidate solutions along multiple criteria, and the use of a local evolutionary algorithm to cover the space of feature subsets and of cluster numbers. Further, by identifying newly discovered feature subsets that form well-differentiated clusters, our model can affect the way new marketing campaigns should be implemented.
EM Algorithm for Finite Mixture ModelsThe expectation maximization algorithm (Dempster, Laird, & Rubin,1977) is one of the most often used statistical modeling algorithms (Cheeseman & Stutz, 1996). The EM algorithm often significantly outperforms other clustering methods (Meila & Heckerman, 1998) and is superior to the distance-based algorithms (e.g., K-means) in the sense that it can handle categorical data. The EM algorithm starts with an initial estimate of the parameters and iteratively recomputes the likelihood that each pattern is drawn from a particular density function, and then updates the parameter estimates. For Gaussian distributions, the parameters are the mean μk and covariance matrix Σk. Readers who are interested in algorithm detail refer to Buhmann (1995) and Bradley, Fayyad, and Reina (1998). In order to evaluate the quality of the clusters formed by the EM algorithm, we use three heuristic fitness criteria, described below. Each objective is normalized into the unit interval and maximized by the EA. Faccuracy: This objective is meant to favor cluster models with parameters whose corresponding likelihood of the data given the model is higher. With estimated distribution parameters μk and Σk, Faccuracy is computed as follows:
where Zaccuracy is an empirically derived, data-dependent normalization constant meant to achieve Faccuracy values spanning the unit interval. Fclusters: The purpose of this objective is to favor clustering models with fewer clusters, if other things being equal.
where Kmax (Kmin) is the maximum (minimum) number of clusters that can be encoded into a candidate solution's representation. Fcomplexity: The final objective is aimed at finding parsimonious solutions by minimizing the number of selected features:
Note that at least one feature must be used. Other things being equal, we expect that lower complexity will lead to easier interpretability and scalability of the solutions as well as better generalization.
The Wrapper Model of ELSA/EMWe first outline the model of ELSA/EM in Figure 5. In ELSA, each agent (candidate solution) in the population is first initialized with some random solution and an initial reservoir of energy. The representation of an agent consists of (D + Kmax − 2) bits. D bits correspond to the selected features (1 if a feature is selected, 0 otherwise). The remaining bits are a unary representation of the number of clusters.[6] This representation is motivated by the desire to preserve the regularity of the number of clusters under the genetic operators; changing any one bit will change K by one.
Mutation and crossover operators are used to explore the search space and are defined in the same way as in previous section. In order to assign energy to a solution, ELSA must be informed of clustering quality. In the experiments described here, the clusters to be evaluated are constructed based on the selected features using the EM algorithm. Each time a new candidate solution is evaluated, the corresponding bit string is parsed to get a feature subset J and a cluster number K. The clustering algorithm is given the projection of the data set onto J, uses it to form K clusters, and returns the fitness values.
Experiments on the Synthetic Data
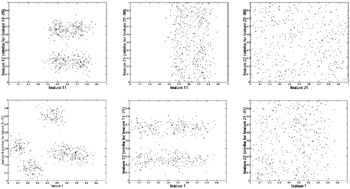
Data set and baseline algorithmIn order to evaluate our approach, we construct a moderate-dimensional synthetic data set, in which the distributions of the points and the significant features are known, while the appropriate clusters in any given feature subspace are not known. The data set has N = 500 points and D = 30 features. It is constructed so that the first 10 features are significant, with five "true" normal clusters consistent across these features. The next 10 features are Gaussian noise, with points randomly and independently assigned to two normal clusters along each of these dimensions. The remaining 10 features are white noise. We evaluate the evolved solutions by their ability to discover five pre-constructed clusters in a 10-dimensional subspace. We present some two-dimensional projections of the synthetic data set in Figure 6. In our experiments, individuals are represented by 36 bits 30 for the features and 6 for K (Kmax = 8). There are 15 energy bins for all energy sources, Fclusters, Fcomplexity, and Faccuracy. The values for the various ELSA parameters are: Pr(mutation) = 1.0, Pr(crossover) = 0.8, pmax = 100, Ecost = 0.2, Etotal = 40, h = 0.3, and T = 30,000.
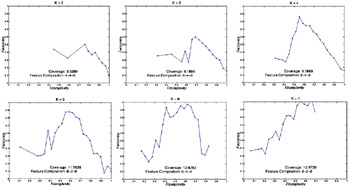
Experimental resultsWe show the candidate fronts found by the ELSA/EM algorithm for each different number of clusters K in Figure 7.
We omit the candidate front for K = 8 because of its inferiority in terms of clustering quality and incomplete coverage of the search space. Composition of selected features is shown for Fcomplexity corresponding to 10 features (see text). We analyze whether our ELSA/EM model is able to identify the correct number of clusters based on the shape of the candidate fronts across different values of K and Faccuracy. The shape of the Pareto fronts observed in ELSA/EM is as follows: an ascent in the range of higher values of Fcomplexity (lower complexity), and a descent for lower values of Fcomplexity (higher complexity). This is reasonable because adding additional significant features will have a good effect on the clustering quality with few previously selected features. However, adding noise features will have a negative effect on clustering quality in the probabilistic model, which, unlike Euclidean distance, is not affected by dimensionality. The coverage of the ELSA/EM model shown in Figure 7 is defined as:
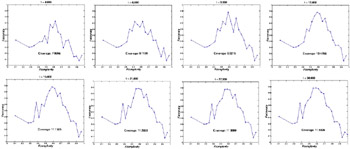
We note that the clustering quality and the search space coverage improve as the evolved number of clusters approaches the "true" number of clusters, K = 5. The candidate front for K = 5 not only shows the typical shape we expect, but also an overall improvement in clustering quality. The other fronts do not cover comparable ranges of the feature space either because of the agents' low Fclusters (K = 7) or because of the agents' low Faccuracy and Fcomplexity (K = 2 and K = 3). A decision-maker again would conclude the right number of clusters to be five or six. We note that the first 10 selected features, 0.69 ≤ Fcomplexity ≤ 1, are not all significant. This notion is again quantified through the number of significant / Gaussian noise / white noise features selected at Fcomplexity = 0.69 (10 features) in Figure 7.[7] None of the "white noise" features is selected. We also show snapshots of the ELSA/EM fronts for K = 5 at every 3,000 solution evaluations in Figure 8. ELSA/EM explores a broad subset of the search space, and thus identifies better solutions across Fcomplexity as more solutions are evaluated. We observed similar results for different number of clusters K.
Table 3 shows classification accuracy of models formed by both ELSA/EM and the greedy search. We compute accuracy by assigning a class label to each cluster based on the majority class of the points contained in the cluster, and then computing correctness on only those classes, e.g., models with only two clusters are graded on their ability to find two classes. ELSA results represent individuals selected from candidate fronts with less than eight features. ELSA/EM consistently outperforms the greedy search on models with few features and few clusters. For more complex models with more than 10 selected features, the greedy method often shows higher classification accuracy.
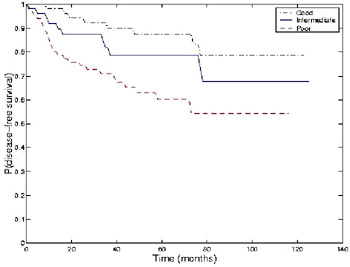
Experiments on WPBC DataWe also tested our algorithm on a real data set, the Wisconsin Prognostic Breast Cancer (WPBC) data (Mangasarian, Street, & Wolberg, 1995). This data set records 30 numeric features quantifying the nuclear grade of breast cancer patients at the University of Wisconsin Hospital, along with two traditional prognostic variables tumor size and number of positive lymph nodes. This results in a total of 32 features for each of 198 cases. For the experiment, individuals are represented by 38 bits 32 for the features and 6 for K (Kmax = 8). Other ELSA parameters are the same as those used in the previous experiments. We analyzed performance on this data set by looking for clinical relevance in the resulting clusters. Specifically, we observe the actual outcome (time to recurrence, or known disease-free time) of the cases in the three clusters. Figure 9 shows the survival characteristics of three prognostic groups found by ELSA/EM. The three groups showed well-separated survival characteristics. Out of 198 patients, 59, 54, and 85 patients belong to the good, intermediate, and poor prognostic groups, respectively. The good prognostic group was welldifferentiated from the intermediate group (p < 0.076), and the intermediate group was significantly different from the poor group (p < 0.036). Five-year recurrence rates were 12.61%, 21.26%, and 39.85% for the patients in the three groups. The chosen dimensions by ELSA/EM included a mix of nuclear morphometric features, such as the mean and the standard error of the radius, perimeter, and area, and the largest value of the area and symmetry along three other features.
We note that neither of the traditional medical prognostic factors tumor size and lymph node status is chosen. This finding is potentially important because the lymph node status can be determined only after lymph nodes are surgically removed from the patient's armpit (Street, Mangasarian, & Wolberg, 1995). We further investigate whether other solutions with lymph node information can form three prognostic groups as good as our EM solution. For this purpose, we selected Pareto solutions across all different K values that have fewer than 10 features including lymph node information, and formed three clusters using these selected features, disregarding the evolved value of K. The survival characteristics of the three prognostic groups found by the best of these solutions were very competitive with our chosen solution. The good prognostic group was welldifferentiated from the intermediate group (p < 0.10), and the difference between the intermediate group and the poor group was significant (p < 0.026). This suggests that lymph node status may indeed have strong prognostic effects, even though it is excluded from the best models evolved by our algorithms.
ConclusionsIn this section, we presented a new ELSA/EM algorithm for unsupervised feature selection. Our ELSA/EM model outperforms a greedy algorithm in terms of classification accuracy while considering a number of possibly conflicting heuristic metrics. Most importantly, our model can reliably select an appropriate clustering model, including significant features and the number of clusters. In future work, we would like to compare the performance of ELSA on the unsupervised feature selection task with other multi-objective EAs, using each in conjunction with clustering algorithms. Another promising future direction will be a direct comparison of different clustering algorithms in terms of the composition of selected features and prediction accuracy.
[6]The cases of zero or one cluster are meaningless, therefore we count the number of clusters as K = κ + 2 where κ is the number of ones and Kmin = 2 ≤ K ≤ Kmax.
[7]For K = 2, we use Fcomplexity = 0.76, which is the closest value to 0.69 represented in the front.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

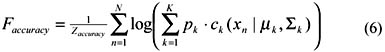


EAN: 2147483647
Pages: 194