1.3 XML Document Examples and Terms
|
|
1.3 XML Document Examples and Terms
XML documents are composed of entities. These entities are storage units for pieces of the document structure. Each entity has a name and can be referenced by its name. The document entities can be parsed or unparsed. Parsed entities are all of the character content of the document and the markup tags. Parsed entities are also called replacement text and are processed like mail merge documents in a word processor. Unparsed entities are all of the non-content and may be text other than XML, graphics, and sound, according to the World Wide Web Consortium, http://www.w3.org/TR/REC-xml#sec-physical-struct. This section discusses XML document terms and gives you examples of these terms.
| Note | You will see references to DTDs, Document Type Definitions, throughout this chapter. FileMaker Pro has provided these for you for use with XML publishing on the web or for imports and exports with XML. FileMaker Pro DTDs will be discussed in Chapters 2 and 4. If you wish to write your own Document Type Definitions, see Chapter 3. |
1.31 Well-formed and Valid XML Documents
To meet the goals of the XML standard, all documents should be well formed. This means:
-
The document contains at least one entity.
-
The document begins with a root or document element, which is the starting point for XML processors.
-
XML processors build a tree-like nested structure from the text of the well-formed document.
-
All parsed entities are also well formed.
-
All markup is composed of start tags, end tags, or empty tags that are properly nested.
The nested markup in many of the listings in this book is indented for reader convenience, but this is not a requirement for a well-formed XML document. In some cases the tab and return characters are considered viable to the XML document, and extraneous indentation can invalidate the document. Study the needs for your data exchange and don't introduce extra data.
The well-formed XML document has one or more elements: root element, parent elements, and child elements. The XML document in Listing 1.5 starts and ends with a root element, but the name of the element can be anything. All the elements are properly formatted with a start and end tag or empty tag. The child elements are nested within the parent elements, and all elements are within the root element.
Listing 1.5: Properly nested markup tags in a document
<root> <parent> <child> <grandchild /> </child> </parent> </root>
The same document could be compacted with no white space and still follow the rules for well-formedness:
<root><parent><child><grandchild /></child></parent></root>
Conforming XML parsers and processors should verify that a document is well formed. If not, they stop processing and produce a report as soon as any errors are encountered. Improper nesting of elements causes a typical error.
XML parsers can be validating or nonvalidating. A valid XML document has an associated Document Type Definition (DTD), but not all XML documents require a DTD. An XML formatted document can be well formed and not valid. However, a valid XML document must be well formed.
A Document Type Definition is a list of the "fields" that are allowable in a particular XML document type. However, in XML they are not called fields but entities. The DTD contains the entities with element names, attributes of those elements, and the rules governing the entities and the document. For data exchange in a business-to-business situation, the DTD can be the map of the entities of a document. Creating well-formed and valid documents increases the accuracy of the data in those documents. Creating well-formed and valid XML documents also helps standardize the data to assist the exchange of information. There are many DTDs, schemas, XML grammars, and other XML standards such as MathML (Mathematical Markup Language), SMIL (Synchronized Multimedia Integration Language), and XBRL (Extensible Business Reporting Language).
1.32 Data Validation in FileMaker Pro
You have a similar way to assist with data integrity (validity) in FileMaker Pro. When you create a FileMaker Pro database file, you add fields in the Define Fields dialog. You define a field by naming the field and setting it to one of these data types: text, number, date, time, container, calculation, summary, or global. To further define the field, you can specify options to automatically enter specific data, to validate the data entered, and to store the field's index or recalculation as needed. Figure 1.1 shows the Define Fields options dialog for setting validation in FileMaker Pro. The following exercise restricts a number field to only allow number values.
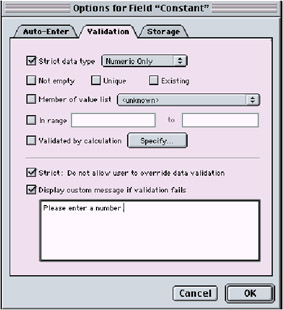
Figure 1.1: FileMaker Pro Define Fields Options dialog
Exercise 1.1: Validate Field Data Entry
-
Open the Define Fields dialog by choosing File, Define Fields… or using the keyboard shortcut Command+Shift+D on Macintosh, or Control+Shift+D on Windows.
-
Type Age in the Field Name box and select the Number radio button. Click the Create button to define the field. Now click the Options… button and select the Validation tab.
-
Check Strict data type and select Numeric Only from the pop-up. Close the Options dialog box by selecting OK or pressing Enter on your keyboard, and close the Define Fields dialog by selecting the Done button.
-
Enter Layout mode by choosing View, Layout Mode or using the keyboard shortcut Control+L on Windows or Command+L on Macintosh.
-
Place the new field on the layout if it is not already there by choosing the menu item Insert, Field.
-
Choose View, Browse Mode or use the shortcut Control+B on Windows or Command+B on Macintosh.
-
Enter the Age field by pressing the Tab key or by clicking into the field. Enter any number and tab out of the field or click anywhere else on the layout. You should not get a warning message.
-
Create a new record by choosing Records, New Record or the shortcut Command+N on Macintosh or Control+N on Windows.
-
Enter abc into the Age field. After you leave the field, you will be presented with the warning: "This field is defined to contain numeric values only. Allow this non-numeric value?" and the buttons: "Revert field", "No", and "Yes." This dialog will allow you to override the warning if you select Yes. This override feature can be valuable at times but not if you want to have a valid number field.
-
Open the Define Fields dialog again and select the Age field. Click on the Options button and change the validation to provide a custom warning message. Check Strict: Do not allow user to override data validation and Display custom message if validation fails, then type Please enter a number in the field.
-
When you enter abc in the Age field, you get your custom message and the validation cannot be overridden. Figure 1.2 shows this custom message.

Figure 1.2: FileMaker Pro invalid entry alert dialog
Using a DTD to validate an XML document or setting the validation on fields for FileMaker Pro data entry provides for reliability of the information exchanged. Your XML documents should be well formed and valid. You will see in Chapter 2 how FileMaker Pro exports your data in a well-formed and valid XML document. Examples of the terms in DTDs will be discussed in Chapter 3, "Document Type Definitions (DTDs)." Document Type Definitions for the three XML document types published by FileMaker Pro will be discussed in Chapter 4, "FileMaker Pro XML Schema or Grammar Formats (DTDs)."
1.33 XML Document Structure
An application that opens or reads files needs to know the type of document to process. Few applications are capable of processing all file types. Often the file type is determined by the file extension (.txt, .sit, .exe, .csv, .jpeg, .FP5, or .html) or the Creator Code and File Type on the Macintosh operating system. Sometimes the file type will also be embedded in the document itself. For example, you will find "%PDF" at the beginning of a Portable Document Format file created by Adobe Acrobat or "GIF89a" at the beginning of a Graphics Interchange Format (.gif) file.
Well-formed XML documents begin with a prolog. This opening statement tells the XML parser the type of file it will be processing. The XML document prolog contains an optional XML declaration, one or more miscellaneous entities (comments and processing instructions), and optional Document Type Declarations. An HTML document, for example, can be a well-formed XML document with minor corrections to the standard HTML markup. The well-formed HTML document includes the XML declaration in the prolog. You can read more about the other optional elements of the prolog in section 2.8 of the XML specification, "Prolog and Document Type Declaration", http://www.w3.org/TR/REC-xml#sec-prolog-dtd. Examples of XML declarations are listed below.
<?xml version="1.0" encoding="encoding type" standalone="yes" ?> <?xml version='1.0'?> <?xml version="1.0" encoding="ISO 8859-1" ?>
The version attribute is required in all XML declarations. When you include the version attribute, the document contains the information used should there be future versions of the XML specifications. The current version number is 1.0 and is based on the W3C Recommendation as of October 6, 2000, http://www.w3.org/TR/REC-xml.
The encoding attribute, optional in the XML declaration statement, specifies the character sets used to compose the document. This encoding attribute uses Unicode Transformation Formats (UTF-8) as the default. The 256 letters, digits, and other characters we commonly use for transmitting text are called ASCII (American Standard Code for Information Interchange) characters and are a subset of UTF-8. ASCII may also be called ISO 8859-1 or Latin-1, although only the first 128 characters of all these formats may be the same depending upon platform and font faces.
XML processors must be able to read both UTF-8 and UTF-16 encoding. UTF-16 allows for more characters, such as would be used to compose ideographical alphabets. Graphical alphabets could be symbols, icons, or Asian characters. You may specify other UTF or encoding types. See "Unicode vs. ASCII" in section 1.42 of this chapter, for further explanation and examples of encoding types. Three common encoding types are listed below.
encoding="UTF-8" encoding="UTF-16" encoding="ISO-8859-1"
FileMaker Pro and UTF-8
According to the FileMaker Pro Developer's Guide, p. 7-8, "About UTF-8 encoded data": All XML data generated by the Web Companion is encoded in UTF-8 (Unicode Transformation 8 Bit) format… UTF-8 encoded data is compressed almost in half (lower ASCII characters are compressed from 2 bytes to 1 byte), which helps data download faster. Note: Because your XML data is UTF-8 encoded, some upper ASCII characters will be represented by two or three characters in the text editor—they will appear as single characters only in the XML parser or browser. An example of this type of encoding is shown in Listing 2.4.
The new XML parser in FileMaker Pro 6 uses a larger set of encodings. The FileMaker Pro Help topic "Importing XML data" states: "FileMaker uses the Xerces-C++ XML parser which supports ASCII, UTF-8, UTF-16 (Big/Small Endian), UCS4 (Big/Small Endian), EBCDIC code pages IBM037 and IBM1140 encodings, ISO-8859-1 ('Latin1'), and Windows-1252." You can find additional information FileMaker Pro supports for encodings by typing "UTF" in FileMaker Pro Help under the Find tab.
Standalone Documents
Standalone is also optional in the XML declaration statement. If standalone="yes", there are no external markup declarations associated with this document. The XML processor needs to know whether to process or skip these. If standalone="no", then you will need to specify the location of the external declarations. A document can have both embedded markup declarations and external markup declarations. Documents that might have external calls could contain references to stylesheets or graphics and sounds. The following prolog tells the processors to look for external definitions and where to find them.
<?xml version="1.0" standalone="no"?> <!ENTITY % image1 SYSTEM "http://www.mydomain.com/images/image1.gif"> %image1;
1.34 Document Type Declarations (DOCTYPE)
You may have seen Document Type Declarations in web pages. The Document Type Declaration (DOCTYPE) should be one of the first statements in an HTML document, because it is part of the prolog of the document. The DOCTYPE tells more about the document and where the definition for this type of format can be found. A common declaration for an HTML 4.0 document follows.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/1998/REC-html40-19980424/loose.dtd">
They may sound similar, but Document Type Declaration (DOCTYPE) should not be confused with Document Type Definition (DTD). However, the declaration (DOCTYPE) can point to the location of any definition (DTD) to which a particular document should conform.
| Tip | While using an HTML editor, you may have the option or preference to check the syntax of your document as you edit. You can specify how strict (precise) the document should be if you insert the DOCTYPE statement first. When you check the document, the editor should warn you if you have not followed the rules according to the specified DOCTYPE. Good HTML editors will tell you what the error is and where it is located in your document. |
Let's analyze the parts of the DOCTYPE declaration. Only the topElement is required. Each of the other parts may be optional but occur in the declaration as follows:
<!DOCTYPE topElement availability "registration//organization//type label definition//language" "URL">
topElement is the root element (first significant markup) found in the document; "HTML" is the default for web pages. Remember that the DOCTYPE is part of the prolog and is placed above the root element in the document. Valid documents must have this element match the root element.
availability is a "PUBLIC" or a "SYSTEM" resource. Documents used internally or references to documents related to this one would have "SYSTEM" availability.
registration is "ISO" (an approved ISO standard), "+" (registered but not approved by the ISO), or "−" (not registered by the ISO). The International Organization for Standardization might not register XML or HTML DOCTYPEs.
organization is a unique label of the owner ID or entity that created the DTD. Common organizations are "IETF" (Internet Engineering Task Force) and "W3C" (World Wide Web Consortium).
type is the type of object being referenced. "DTD" is the default.
label is a unique description for the text being referenced. "HTML 4.0", for example, refers to the version of these recommendations.
definition is the type of document. "Frameset", "Strict", or "Transitional" are common definitions for HTML documents. Strict documents have more limited markup but can be used across a broader set of devices.
language is the two-character code of the language used to create the document. "EN" is English and "ES" is Spanish. The ISO 639 standard is used for this code, which are the same codes used for the "xml:lang" attribute. Here, language is used for the entire document, although specific elements in the document can still be redefined by using "xml:lang."
URL (Uniform Resource Locator) is the location of the DTD.
You can name your own document type. This is the only required element of the DOCTYPE statement. You should remember this naming suggestion: Stick with alphanumeric characters and the underscore character and you cannot go wrong! Also avoid any combination of the letters "X" or "x", "M" or "m", and "L" or "l", in that order, when naming your document type, as these are reserved.
DOCTYPES can contain internal Document Type Definitions (DTDs) or external DTDs. Internal DTDs stay with the document and can only be used with that document. You are making the definition of the document in itself. External DTDs can be used for multiple documents and are referenced by the PUBLIC location, or if used internally, by the SYSTEM location as relative path to the document. Listing 1.6 shows some examples of XML documents with external DTD references. Compare them to the code below, which is complete with internal DTD:
<?xml version="1.0" standalone="yes" ?> <!DOCTYPE myDoc [<!ELEMENT myDoc (#PCDATA)>]> <mydoc>Here's the text!</mydoc>
Listing 1.6: XML documents with external DTD references
Example 1: <?xml version="1.0" standalone="no" ?> <!DOCTYPE myDoc SYSTEM "myDoc.dtd"> <myDoc> <head>This is the first element of my document</head> <main> <para>Now I can add content.</para> <para>Each line is another child of the main element</para> </main> </mydoc> Example 2: <?xml version="1.0" standalone="no" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/2000/REC-xhtml1-20000126/DTD/ xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head> <meta http-equiv="content-type" content="text/html; charset=utf-8" /> <title>New Document</title> </head> <body> <div> Because this is strict XHTML, every tag needs "closure"<br /> Including the break just inserted before this line and the meta tag in the head. </div> <div> Also note the way the quote mark is encoded around the word closure.<br /> You will see this later as a predefined entity in Element Content. </div> </body> </html>
1.35 Processing Instructions
You can include processing instructions in your document prolog. Processing instructions begin with "<?" and end with "?>." Although the XML declaration in the prolog has similar markup, it is not used as a processing instruction. You may find processing instructions used to reference an XSL (XML Stylesheet Language) document. Use processing instructions rather than comments if you wish the XML processor to see them.
<? target ?>
The target is the name of the application to receive the instruction. Because the end of this special markup is "?>", do not use these characters in your target declaration. The code below shows examples of the processing instructions that FileMaker Pro produces if you use a stylesheet. In section 5.2, "XML Request Commands for Web Companion", you will see the request for stylesheets.
<? xml-stylesheet href="headlines.css" type="text/css" ?> <? xml-stylesheet href="headlines.xsl" type="text/xsl" ?>
1.36 Comments
When you create documents, you may wish to add comments near any statements that need further clarification. Comments should not contain any important part of the document as any processing may ignore them. However, some processors may use comments or they may be helpful to humans reading the document. Comments may be anywhere in the document; they are not only for inclusion in the prolog of the document.
Comments are placed outside any other markup. Comments are simply created using "<!–" at the start of the comment and "–>" at the end. These characters are reserved, so they should not be used anywhere else in a document. Additional "–" or "-" should not be used within any comment. Any white space is ignored, so you may have spaces and returns in a comment. Example comments can be found in Listing 1.7.
Listing 1.7: Example comments
<!-- THIS IS A COMMENT --> <!-- THIS IS ALSO A COMPLETE COMMENT ALTHOUGH IT SPANS MULTIPLE LINES --> <!-- While it is permissible to begin and end the comment next to the --> <!-- markup, it may be easier to read if you include some white space --> <!-- as well. This is an ILLEGAL comment. Note the additional dash at --> <-- the end: --->
Using Comments to Test HTML Documents
Comments can be very useful when checking HTML and CDML documents for accuracy in the markup, including FileMaker Pro replacement tags, such as "[FMP-Field: myField]". This can be a valuable tool when troubleshooting or debugging a problematic document. You may place comment tags around a large portion of the document so a browser will not process this part of the document. If the result is as you desired, move the comments around a smaller portion and check again. Errors in HTML and CDML markup can be found easily this way.
Be careful when commenting out table elements. If you place the comment tags around complete tables or rows, you will not receive browser errors. If you need to be more precise, add the comment around the contents of a particular table cell but not the tags themselves. Listings 1.8 and 1.9 show the proper placement of comments inside of HTML table code.
Listing 1.8: Comments around table cell
<table> <tr> <td>content here</td> </tr> <tr> <td><!-- a new row --><td> </tr> </table>
Listing 1.9: Comment around table row
<table> <tr> <td>content here</td> </tr> <!-- <tr> <td><!-- a new row --><td> </tr> --> </table>
Comments for Future Reference
Comments may also be valuable if more than one person is helping create a document. Notes to others can be provided in the comments. Additional examples of comments are shown in Listing 1.10.
Listing 1.10: Single-line or multiple-line comments
<!-- === NEW RECORD BEGINS HERE === --> <!-- *** do not revise this section --> <!-- *** --> ... your static document text here ... <!-- *** --> <!-- *** end "do not revise" --> ... free to edit text here ... <!-- === NEW RECORD ENDS HERE === --> <!-- ******************************* * make comment highly visible * ******************************* --> <!-- created by me on 09 MAR 1999 --> <!-- revised by you on 21 MAR 2000 -->
1.37 Elements and Attributes
Each XML document has one or more elements. These elements are the entities where the content is declared. The construction of the element is simply the type of element as the name of the tag. Elements have a start and end tag. The tag name is the same for the start tag with "/" added to the end tag:
<elementName>content</elementName>
An empty element contains no content but may have attributes:
<elementName /> <elementName></elementName> <elementName attrName="attrValue"/> <elementName attrName="attrValue" attr2="too!" />
The question arises whether to place a space before the "/>" in the standalone empty element. Should you use "<emptyElement/>", "<emptyElement />", or simply make all elements paired ("<empty></empty>")? Section 3.1, "Start-Tags, End-Tags, and Empty-Element Tags", of the XML specification http://www.w3.org/TR/REC-xml, states that the empty element tag is composed of "<" followed by the name of the element, zero or more occurrences of spaces and attribute name/value pairs, ending with an optional space and "/>". For human readability, the space before the final characters in the empty element may be preferable. Another suggestion is made by the XHTML 1.0 recommendation: section C.2, "Empty Elements", http://www.w3.org/TR/xhtml1/, to always include the space for compatibility with browsers and other applications that may read or write HTML and XHTML.
Tag Names
Tag names may contain one or more of the following (in any combination): letter, number, period (.), dash (-), underscore (_), and colon (:). These tag names should begin with a letter, underscore, or colon. You should avoid the use of these reserved words (in any combination of upper- and lowercase): "XML" or "xml". Section 2.3, "Common Syntactic Constructs", of the XML specification http://www.w3.org/TR/REC-xml#sec-common-syn, gives some ideas of how names are to be constructed for elements and attributes in an XML document. The World Wide Web Consortium suggestions allow for more than alpha-numeric characters and the underscore in element and attribute names. However, you may have discovered that different systems use the period, dash, and colon to signify something special on each system. To maintain the portability of your documents, you should carefully consider the names you choose. For example, you may use lowerUppercase notation for element and attribute names, such as <myElement myPositive="yes" myNegative="no" />.
Attributes
Attributes are found in the start tag or empty tag for elements and are composed of name and value pairs. Attributes are used to refine the definition of the element. You do not want to name your attributes the same within a single element, but the same attribute name may be used for different elements. Generally, one piece of information is included in each attribute, although an element may have one or more attributes.
Attributes should always be quoted in element start tags and in empty elements. Attributes can use double or single quotes, but the quotes surrounding any single element must match (for example, <element myAttribute="bad quotes' /> is incorrect). Try to avoid "smart quotes" (also called curly quotes), as they may be interpreted incorrectly in documents that need to be read by different applications and systems. Listing 1.11 shows proper element attributes.
Listing 1.11: Examples of elements with attributes
<elementName attributeName="attributeValue" /> <child firstborn="yes" /> <child firstborn='yes' /> <child firstborn="yes"> <firstName>Dawn</firstName> </child> <pen color="#EEEEEE" pattern="1" size="2" /> <fill color="#FF00FF" pattern="" />
1.38 Element Content
The content of most elements is your information. The content is the text or character data that you want to pass along from one application or system to another. Any text that is not considered markup is character data. You could think of this character data as the leaves on a tree. In the family tree metaphor, any branch can have multiple branches. Therefore, elements can also contain other elements. When an element contains character data and other elements, that element has mixed content. Listing 1.12 mixes content with other elements inside the root element element1.
Listing 1.12: Example of mixed content
<element1> <element2>Some text here</element2> Some content to element1 <emptyElement3/> <emptyElement4></emptyElement4> </element1>
Elements used for XML export or XML web publishing in FileMaker Pro do not contain mixed content. You may encounter XML documents using this format for the elements and need to understand the structure if you are importing XML into FileMaker Pro.
Character data can be composed of any letters, numbers, or symbols. The XML processors need to know if you are using characters as markup or as a part of your text content. The comparison symbols greater than (>) and less than (<) might be interpreted incorrectly if used in a computation statement. You might also be writing an XML document about markup that contains text that you do not want to be processed as markup. There is unique markup used to tell the processor to not parse the literal contents. You can see this unique markup in Listing 1.13. The only special character sequence is the "]]>" pattern, so you must not use this pattern anywhere in your content. You may, however, use the "<![CDATA[" beginning pattern within the content. The XML processors are looking for the end of the character data ("]]>" ) after encountering the beginning pattern.
Listing 1.13: Markup for raw or unparsed data
<![CDATA[your data goes here]]> <![CDATA[This text contains less than and greater than in a calculation, so must be treated in a special way. Is 1 >2 (one greater than two)? No,1 < 2 (one is less than two).]]> <![CDATA[In your HTML document if you want to hide data in an input form, use this: <input type="hidden" name="myField" value="">.]]> <![CDATA[ The text can be many lines & contain values that might otherwise be converted. ]]> <![CDATA[An example of an XML prolog statement is: <?xml version="1.0" encoding="encoding type" standalone="yes" ?>.]]>
Another way to include data that might otherwise get translated is to use predefined entities. The characters are encoded so that they will be passed through the XML parser but can be converted by the displaying application. The encoding uses the reserved character "&" (ampersand) followed by the entity name and ";" (semicolon). These entities are found in Table 1.1 and are used in the examples in Listing 1.14.
| Character | Entity | Name |
|---|---|---|
| & | & | ampersand |
| < | < | less than |
| > | > | greater than |
| ' | ' | apostrophe or single quote |
| " | " | double quote |
Listing 1.14: Character data using predefined entities
<element1>This has a greater than symbol in the function: if(a > b).</element1> <company>Brown & Jones Excavating</company> <title>"Gone With the Wind"</title>
1.39 The Element Tree Completed
Putting all of the element information together, you can build a well-formed XML document. You can have empty elements or elements containing data and other elements. You can have comments to further describe your tree, but they are not crucial to the structure of the tree. The image of the tree (Figure 1.3) follows the rules for the XML document in Listing 1.15.

Figure 1.3
Listing 1.15: The complete tree
<?xml version="1.0" standalone="yes" ?> <!DOCTYPE tree [ <!ELEMENT tree (BRANCH)> <!ELEMENT BRANCH (branchlet, twig)> <!ELEMENT branchlet (#PCDATA)> <!ELEMENT twig (#PCDATA)> ]> <tree> <!-- the root or trunk of the tree has some main branches --> <BRANCH> <!-- a BRANCH can have branchlets and twigs --> <branchlet> <twig>leaves</twig> <!-- empty element (no leaves) --> <twig/> <twig>leaves</twig> </branchlet> <branchlet> <twig>leaves</twig> <twig>leaves</twig> </branchlet> <twig>leaves</twig> </BRANCH> <BRANCH> <branchlet> <twig>leaves</twig> </branchlet> <branchlet> <twig>leaves</twig> <twig>leaves</twig> </branchlet> </BRANCH> </tree>
|
|
EAN: 2147483647
Pages: 100