Gathering Performance Information
With release 7.2, the PostgreSQL developers introduced a new collection of performance-related system views. These views return two distinct kinds of information. The pg_stat views characterize the frequency and type of access for each table in a database. The pg_statio views will tell you how much physical I/O is performed on behalf of each table.
Let's look at each set of performance-related views in more detail.
The pg_stat_all_tables contains one row for each table in your database. Here is the layout of pg_stat_all_tables:
perf=# d pg_stat_all_tables View "pg_stat_all_tables" Column | Type | Modifiers ---------------+---------+----------- relid | oid | schemaname | name | relname | name | seq_scan | bigint | seq_tup_read | bigint | idx_scan | numeric | idx_tup_fetch | numeric | n_tup_ins | bigint | n_tup_upd | bigint | n_tup_del | bigint |
The seq_scan column tells you how many sequential (that is, table) scans have been performed for a given table, and seq_tup_read tells you how many rows were processed through table scans. The idx_scan and idx_tup_fetch columns tell you how many index scans have been performed for a table and how many rows were processed by index scans. The n_tup_ins, n_tup_upd, and n_tup_del columns tell you how many rows were inserted, updated, and deleted, respectively.
Query ExecutionIf you're not familiar with the terms "table scan" or "index scan," don't worryI'll cover query execution later in this chapter (see "Understanding How PostgreSQL Executes a Query"). |
The real value in pg_stat_all_tables is that you can find out which tables in your data base are most heavily used. This view does not tell you how much disk I/O is performed against each table file, nor does it tell you how much time it took to perform the operations.
The following query finds the top 10 tables in terms of number of rows read:
SELECT relname, idx_tup_fetch + seq_tup_read AS Total FROM pg_stat_all_tables WHERE idx_tup_fetch + seq_tup_read != 0 ORDER BY Total desc LIMIT 10;
Here's an example that shows the result of this query in a newly created database:
perf=# SELECT relname, idx_tup_fetch + seq_tup_read AS Total perf-# FROM pg_stat_all_tables perf-# WHERE idx_tup_fetch + seq_tup_read != 0 perf-# ORDER BY Total desc perf-# LIMIT 10; relname | total --------------+------- recalls | 78482 pg_class | 57425 pg_index | 20901 pg_attribute | 5965 pg_proc | 1391
It's easy to see that the recalls table is heavily usedyou have read 78,482 tuples from that table.
There are two variations on the pg_stat_all_tables view. The pg_stat_sys_tables view is identical to pg_stat_all_tables, except that it is restricted to showing system tables. Similarly, the pg_stat_user_tables view is restricted to showing only user-created tables.
You can also see how heavily each index is being usedthe pg_stat_all_indexes, pg_stat_user_indexes, and pg_stat_system_indexes views expose index information.
Although the pg_stat view tells you how heavily each table is used, it doesn't provide any information about how much physical I/O is performed on behalf of each table. The second set of performance-related views provides that information.
The pg_statio_all_tables view contains one row for each table in a database. Here is the layout of pg_statio_all_tables:
perf=# d pg_statio_all_tables View "pg_statio_all_tables" Column | Type | Modifiers -----------------+---------+----------- relid | oid | schemaname | name | relname | name | heap_blks_read | bigint | heap_blks_hit | bigint | idx_blks_read | numeric | idx_blks_hit | numeric | toast_blks_read | bigint | toast_blks_hit | bigint | tidx_blks_read | bigint | tidx_blks_hit | bigint |
This view provides information about heap blocks (heap_blks_read, heap_blks_hit), index blocks (idx_blks_read, idx_blks_hit), toast blocks (toast_blks_read, toast_blks_hit), and index toast blocks (tidx_blks_read, tidx_blks_hit). For each of these block types, pg_statio_all_tables exposes two values: the number of blocks read and the number of blocks that were found in PostgreSQL's cache. For example, the heap_blks_read column contains the number of heap blocks read for a given table, and heap_blks_hit tells you how many of those pages were found in the cache.
PostgreSQL exposes I/O information for each index in the pg_statio_all_indexes, pg_statio_user_indexes, and pg_statio_sys_indexes views.
Let's try a few examples and see how you can use the information exposed by pg_statio_all_tables.
I've written a simple utility (called timer) that makes it a little easier to see the statistical results of a given query. This utility takes a snapshot of pg_stat_all_tables and pg_statio_all_tables, executes a given query, and finally compares the new values in pg_stat_all_tables and pg_statio_all_tables. Using this utility, you can see how much I/O was performed on behalf of the given query. Of course, the database must be idle except for the query under test.
Execute this simple query and see what kind of I/O results you get:
$ timer "SELECT * FROM recalls" +-------------+--------------------------------+-------------------------------+ | | SEQUENTIAL I/O | INDEXED I/O | | |scans |tuples |heap_blks |cached|scans |tuples |idx_blks |cached| |-------------+------+-------+----------+------+------+-------+---------+------+ |pg_aggregate | 0 | 0 | 1 | 0 | 1 | 1 | 2 | 0 | |pg_am | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | |pg_amop | 0 | 0 | 2 | 10 | 10 | 24 | 4 | 16 | |pg_amproc | 0 | 0 | 1 | 5 | 6 | 6 | 2 | 10 | |pg_attribute | 0 | 0 | 8 | 14 | 21 | 65 | 6 | 57 | |pg_cast | 0 | 0 | 2 | 6 | 60 | 8 | 2 | 118 | |pg_class | 4 | 740 | 5 | 32 | 18 | 17 | 7 | 34 | |pg_database | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | |pg_index | 2 | 146 | 3 | 11 | 8 | 12 | 4 | 12 | |pg_namespace | 2 | 10 | 1 | 2 | 2 | 1 | 2 | 2 | |pg_opclass | 0 | 0 | 2 | 11 | 5 | 73 | 4 | 6 | |pg_operator | 0 | 0 | 4 | 6 | 10 | 10 | 4 | 26 | |pg_proc | 0 | 0 | 6 | 8 | 14 | 14 | 12 | 31 | |pg_rewrite | 0 | 0 | 1 | 1 | 2 | 2 | 2 | 2 | |pg_shadow | 0 | 0 | 1 | 2 | 3 | 3 | 4 | 2 | |pg_statistic | 0 | 0 | 3 | 5 | 33 | 8 | 2 | 64 | |pg_trigger | 0 | 0 | 1 | 1 | 2 | 2 | 2 | 2 | |pg_type | 0 | 0 | 2 | 5 | 7 | 7 | 2 | 12 | |recalls | 1 | 39241 | 4413 | 0 | 0 | 0 | 0 | 0 | +-------------+------+-------+----------+------+------+-------+---------+------+ |Totals | 11 | 40139 | 4458 | 119 | 202 | 253 | 61 | 394 | +-------------+------+-------+----------+------+------+-------+---------+------+
The timer utility shows that a simple query generates a lot of buffer traffic. The PostgreSQL server must parse and plan the query and it consults a number of system tables to do sothat explains the buffer interaction incurred on behalf of all of the tables that start with pg_. The recalls table generates most of the buffer traffic.
This query retrieved 39,241 rows in a single table scan. This scan read 4,413 heap blocks from disk and found none in the cache. Normally, you would hope to see a cache ratio much higher than 4,413 to 0! In this particular case, I had just started the postmaster so there were few pages in the cache and none were devoted to the recalls table. Now, try this experiment again to see if the cache ratio gets any better:
$ timer "SELECT * FROM recalls" recalls +-------------+--------------------------------+-------------------------------+ | | SEQUENTIAL I/O | INDEXED I/O | | |scans |tuples |heap_blks |cached|scans |tuples |idx_blks |cached| |-------------+------+-------+----------+------+------+-------+---------+------+ |recalls | 1 | 39241 | 4413 | 0 | 0 | 0 | 0 | 0 | +-------------+------+-------+----------+------+------+-------+---------+------+
You get exactly the same results for the recalls tableno cache hits. Why not? We did not include an ORDER BY clause in this query so PostgreSQL returned the rows in (approximately) the order of insertion. When we execute the same query a second time, PostgreSQL starts reading at the beginning of the page file and continues until it has read the entire file. Because my cache is only 512 blocks in size, the first 512 blocks have been forced out of the cache by the time I get to the end of the table scan. The next time I execute the same query, the final 512 blocks are in the cache, but you are looking for the leading blocks. The end result is no cache hits.
Just as an experiment, try to increase the size of the cache to see if you can force some caching to take place.
The PostgreSQL cache is kept in a segment of memory shared by all backend processes. You can see this using the ipcs -m command[6]:
[6] up7 In case you are curious, the key value uniquely identifies a shared memory segment. The key is determined by multiplying the postmaster's port number by 1,000 and then incrementing until a free segment is found. The shmid value is generated by the operating system (key is generated by PostgreSQL). The nattach column tells you how many processes are currently using the segment.
$ ipcs -m ------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x0052e2c1 1409024 postgres 600 5021696 3
The shared memory segment contains more than just the buffer cache: PostgreSQL also keeps some bookkeeping information in shared memory. With 512 pages in the buffer cache and an 8K block size, you see a shared memory segment that is 5,021,696 bytes long. Let's increase the buffer cache to 513 pages and see what effect that has on the size of the shared memory segment. There are two ways that you can adjust the size of the cache. You could change PostgreSQL's configuration file ($PGDATA/postgresql.conf), changing the shared_buffers variable from 512 to 513. Or, you can override the shared_buffers configuration variable when you start the postmaster:
$ pg_ctl stop waiting for postmaster to shut down......done postmaster successfully shut down $ # $ # Note: specifying -o "-B 513" is equivalent $ # to setting shared_buffers = 513 in $ # the $PGDATA/postgresql.conf file $ # $ pg_start -o "-B 513" -l /tmp/pg.log postmaster successfully started
Now you can use the ipcs -m command to see the change in the size of the shared memory segment:
$ ipcs -m ------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x0052e2c1 1409024 postgres 600 5038080 3
The shared memory segment increased from 5,021,696 bytes to 5,038,080 bytes. That's a difference of 16,384 bytes, which happens to be the size of two blocks. Why two? Because PostgreSQL keeps some bookkeeping information in shared memory in addition to the buffer cachethe amount of extra space required depends on the number of shared buffers. PostgreSQL won't add two blocks each time you increment shared_buffers by 1; it just happens that when you increase from 512 to 513, you cross a threshold that requires an extra page in the bookkeeping system.
Now, let's get back to the problem at hand. We want to find out if doubling the buffer count will result in more cache hits and therefore fewer I/O operations. Remember, a table scan on the recalls table resulted in 4,413 heap blocks read and 0 cache hits. Let's double the size of the shared buffer cache (from 512 to 1,024 blocks). Try the same query again and check the results:
$ pg_ctl stop waiting for postmaster to shut down......done postmaster successfully shut down $ pg_start -o "-B 1024" -l /tmp/pg.log postmaster successfully started $ ipcs -m ------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x0052e2c1 1409024 postgres 600 9338880 3 $ timer "SELECT * FROM recalls" recalls +-----------------------------------+----------------------------------+ | SEQUENTIAL I/O | INDEXED I/O | | scans | tuples | heap_blks |cached| scans | tuples | idx_blks |cached| +-------+--------+-----------+------+-------+--------+----------+------+ | 1 | 39241 | 4413 | 0 | 0 | 0 | 0 | 0 | +-------+--------+-----------+------+-------+--------+----------+------+
You have to run this query twice because you shut down and restarted the postmaster to adjust the cache size. When you shut down the postmaster, the cache is destroyed (you can use the ipcs -m command to verify this).
$ timer "SELECT * FROM recalls" recalls +-----------------------------------+----------------------------------+ | SEQUENTIAL I/O | INDEXED I/O | | scans | tuples | heap_blks |cached| scans | tuples | idx_blks |cached| +-------+--------+-----------+------+-------+--------+----------+------+ | 1 | 39241 | 4413 | 0 | 0 | 0 | 0 | 0 | +-------+--------+-----------+------+-------+--------+----------+------+
Still the same results as beforePostgreSQL does not seem to buffer any of the data blocks read from the recalls table. Actually, each block is buffered as soon as it is read from disk; but as before, the blocks read at the beginning of the table scan are pushed out by the blocks read at the end of the scan. When you execute the same query a second time, you start at the beginning of the table and find that the blocks that you need are not in the cache.
You could increase the cache size to be large enough to hold the entire table (somewhere around 4,413 + 120 blocks should do it), but that's a large shared memory segment, and if you don't have enough physical memory, your system will start to thrash.
Let's try a different approach. PostgreSQL has enough room for 1,024 pages in the shared buffer cache. The entire recalls table consumes 4,413 pages. If you use the LIMIT clause to select a subset of the recalls table, you should see some caching. I'm going to lower the cache size back to its default of 512 pages before we start:
$ pg_ctl stop waiting for postmaster to shut down......done postmaster successfully shut down $ pg_start -o "-B 512" -l /tmp/pg.log postmaster successfully started
You know that it takes 4,413 pages to hold the 39,241 rows in recalls, which gives you an average of about 9 rows per page. We have 512 pages in the cache; let's assume that PostgreSQL needs about 180 of them for its own bookkeeping, leaving us 332 pages. So, you should ask for 9 * 332 (or 2,988) rows:
$ ./timer "SELECT * FROM recalls LIMIT 2988" recalls +-------------+--------------------------------+-------------------------------+ | | SEQUENTIAL I/O | INDEXED I/O | | |scans |tuples |heap_blks |cached|scans |tuples |idx_blks |cached| |-------------+------+-------+----------+------+------+-------+---------+------+ |recalls | 1 | 2988 | 208 | 0 | 0 | 0 | 0 | 0 | +-------------+------+-------+----------+------+------+-------+---------+------+
PostgreSQL read 208 heap blocks. If everything worked, those pages should still be in the cache. Let's run the query again:
$ ./timer "SELECT * FROM recalls LIMIT 2988" recalls +-------------+--------------------------------+-------------------------------+ | | SEQUENTIAL I/O | INDEXED I/O | | |scans |tuples |heap_blks |cached|scans |tuples |idx_blks |cached| |-------------+------+-------+----------+------+------+-------+---------+------+ |recalls | 1 | 2988 | 0 | 208 | 0 | 0 | 0 | 0 | +-------------+------+-------+----------+------+------+-------+---------+------+
Now you're getting somewhere. PostgreSQL read 208 heap blocks and found all 208 of them in the cache.
Dead Tuples
Now let's look at another factor that affects performance. Make a simple update to the recalls table:
perf=# UPDATE recalls SET potaff = potaff + 1; UPDATE
This command increments the potaff column of each row in the recalls table. (Don't read too much into this particular UPDATE. I chose potaff simply because I needed an easy way to update every row.) Now, after restarting the database, go back and SELECT all rows again:
$ timer "SELECT * FROM recalls" recalls +-------------+--------------------------------+-------------------------------+ | | SEQUENTIAL I/O | INDEXED I/O | | |scans |tuples |heap_blks |cached|scans |tuples |idx_blks |cached| |-------------+------+-------+----------+------+------+-------+---------+------+ |recalls | 1 | 39241 | 8803 | 0 | 0 | 0 | 0 | 0 | +-------------+--------------------------------+-------------------------------+
That's an interesting resultyou still retrieved 39,241 rows, but this time you had to read 8,803 pages to find them. What happened? Let's see if the pg_class table gives any clues:
perf=# SELECT relname, reltuples, relpages perf-# FROM pg_class perf-# WHERE relname = 'recalls'; relname | reltuples | relpages ---------+-----------+---------- recalls | 39241 | 4413
No clues therepg_class still thinks you have 4,413 heap blocks in this table. Let's try counting the individual rows:
perf=# SELECT count(*) FROM recalls; count ------- 39241
At least that gives you a consistent answer. But why does a simple update UPDATE cause you to read twice as many heap blocks as before?
When you UPDATE a row, PostgreSQL performs the following operations:
- The new row values are written to the table.
- The old row is deleted from the table.
- The deleted row remains in the table, but is no longer accessible.
This means that when you executed the statement "UPDATE recalls SET potaff = potaff + 1", PostgreSQL inserted 39,241 new rows and deleted 39,241 old rows. We now have 78,482 rows, half of which are inaccessible.
Why does PostgreSQL carry out an UPDATE command this way? The answer lies in PostgreSQL's MVCC (multi-version concurrency control) feature. Consider the following commands:
perf=# BEGIN WORK; BEGIN perf=# UPDATE recalls SET potaff = potaff + 1; UPDATE
Notice that you have started a new transaction, but you have not yet completed it. If another user were to SELECT rows from the recalls table at this point, he must see the old valuesyou might roll back this transaction. In other database systems (such as DB2, Sybase, and SQL Server), the other user would have to wait until you either committed or rolled back your transaction before his query would complete. PostgreSQL, on the other hand, keeps the old rows in the table, and other users will see the original values until you commit your transaction. If you roll back your changes, PostgreSQL simply hides your modifications from all transactions (leaving you with 78,482 rows, half of which are inaccessible).
When you DELETE rows from a table, PostgreSQL follows a similar set of rules. The deleted rows remain in the table, but are hidden. If you roll back a DELETE command, PostgreSQL will simply make the rows visible again.
Now you also know the difference between a tuple and a row. A tuple is some version of a row.
When you make a change to a table, the tuples that you've changed are hidden from other users until you COMMIT your changes. If you INSERT 100,000 new rows into a table that previously contained only a few rows, another user might suddenly see a decrease in query performance even though he can't see the new rows. If you roll back your changes, other users will never see the new rows, but the dead tuples that you've created will continue to affect performance until someone VACUUMs the table.
You can see that these hidden tuples can dramatically affect performanceupdating every row in a table doubles the number of heap blocks required to read the entire table.
There are at least three ways to remove dead tuples from a database. One way is to export all (visible) rows and then import them again using pg_dump and pg_restore. Another method is to use CREATE TABLE ... AS to make a new copy of the table, drop the original table, and rename the copy. The preferred way is to use the VACUUM command. I'll show you how to use the VACUUM command a little later (see the section "Table Statistics").
Index Performance
You've seen how PostgreSQL batches all disk I/O into 8K blocks, and you've seen how PostgreSQL maintains a buffer cache to reduce disk I/O. Let's find out what happens when you throw an index into the mix. After restarting the postmaster (to clear the cache), execute the following query:
$ timer "SELECT * FROM recalls ORDER BY record_id;" recalls +-----------------------------------+----------------------------------+ | SEQUENTIAL I/O | INDEXED I/O | | scans | tuples | heap_blks |cached| scans | tuples | idx_blks |cached| +-------+--------+-----------+------+-------+--------+----------+------+ | 0 | 0 | 26398 | 12843| 1 | 39241 | 146 | 0 | +-------+--------+-----------+------+-------+--------+----------+------+
You can see that PostgreSQL chose to execute this query using an index scan (remember, you have an index defined on the record_id column). This query read 146 index blocks and found none in the buffer cache. You also processed 26,398 heap blocks and found 12,843 in the cache. You can see that the buffer cache helped the performance a bit, but you still processed over 26,000 heap blocks, and you need only 4,413 to hold the entire recalls table. Why did you need to read each heap block (approximately) five times?
Think of how the recalls table is stored on disk (see Figure 4.2).
Figure 4.2. The recalls table on disk.
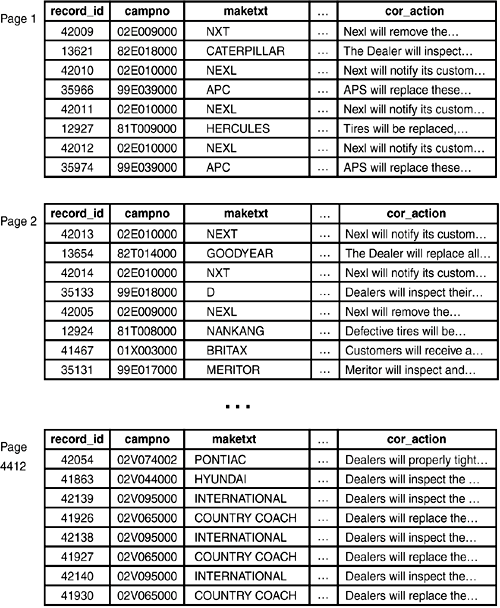
Notice that the rows are not stored in record_id order. In fact, they are stored in order of insertion. When you create an index on the record_id column, you end up with a structure like that shown in Figure 4.3.
Figure 4.3. The recalls table structure after creating an index.
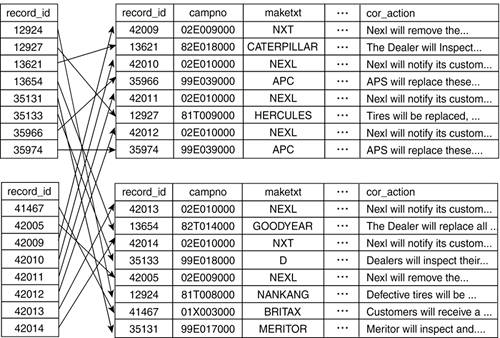
Consider how PostgreSQL uses the record_id index to satisfy the query. After the first block of the record_id index is read into the buffer cache, PostgreSQL starts scanning through the index entries. The first index entry points to a recalls row on heap block 2, so that heap block is read into the buffer cache. Now, PostgreSQL moves on to the second index entrythis one points to a row in heap block 1. PostgreSQL reads heap block 1 into the buffer cache, throwing out some other page if there is no room in the cache. Figure 4.2 shows a partial view of the recalls table: remember that there are actually 4,413 heap blocks and 146 index blocks needed to satisfy this query. It's the random ordering of the rows within the recalls table that kills the cache hit ratio.
Let's try reordering the recalls table so that rows are inserted in record_id order. First, create a work table with the same structure as recalls:
perf=# CREATE TABLE work_recalls AS perf-# SELECT * FROM recalls ORDER BY record_id; SELECT
Then, drop the original table, rename the work table, and re-create the index:
perf=# DROP TABLE recalls; DROP perf=# ALTER TABLE work_recalls RENAME TO recalls; ALTER perf=# CREATE INDEX recalls_record_id ON recalls( record_id ); CREATE
At this point, you have the same data as before, consuming the same amount of space:
perf=# SELECT relname, relpages, reltuples FROM pg_class
perf-# WHERE relname IN ('recalls', 'recalls_record_id' );
relname | relpages | reltuples
-------------------+----------+-----------
recalls_record_id | 146 | 39241
recalls | 4422 | 39241
(2 rows)
After restarting the postmaster (again, this clears out the buffer cache so you get consistent results), let's re-execute the previous query:
$ timer "SELECT * FROM recalls ORDER BY record_id;" recalls +-----------------------------------+----------------------------------+ | SEQUENTIAL I/O | INDEXED I/O | | scans | tuples | heap_blks |cached| scans | tuples | idx_blks |cached| +-------+--------+-----------+------+-------+--------+----------+------+ | 0 | 0 | 4423 | 34818| 1 | 39241 | 146 | 0 | +-------+--------+-----------+------+-------+--------+----------+------+
That made quite a difference. Before reordering, you read 26,398 heap blocks from disk and found 12,843 in the cache for a 40% cache hit ratio. After physically reordering the rows to match the index, you read 4,423 heap blocks from disk and found 34,818 in the cache for hit ratio of 787%. This makes a huge performance difference. Now as you read through each index page, the heap records appear next to each other; you won't be thrashing heap pages in and out of the cache. Figure 4.4 shows how the recalls table looks after reordering.
Figure 4.4. The recalls table on disk after reordering.
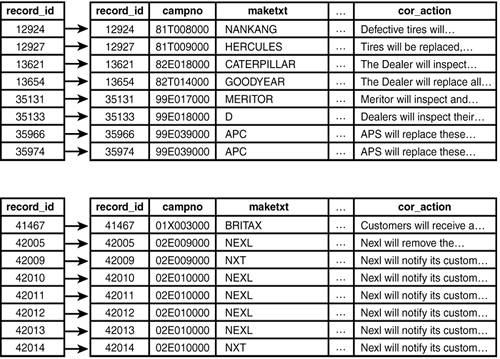
We reordered the recalls table by creating a copy of the table (in the desired order), dropping the original table, and then renaming the copy back to the original name. You can also use the CLUSTER commandit does exactly the same thing.
Part I: General PostgreSQL Use
Introduction to PostgreSQL and SQL
- Introduction to PostgreSQL and SQL
- A Sample Database
- Basic Database Terminology
- Prerequisites
- Connecting to a Database
- Creating Tables
- Viewing Table Descriptions
- Adding New Records to a Table
- Installing the Sample Database
- Retrieving Data from the Sample Database
- The CASE Expression
- Aggregates
- Multi-Table Joins
- UPDATE
- DELETE
- A (Very) Short Introduction to Transaction Processing
- Creating New Tables Using CREATE TABLE...AS
- Using VIEW
- Summary
Working with Data in PostgreSQL
- Working with Data in PostgreSQL
- NULL Values
- Character Values
- Numeric Values
- Date/Time Values
- Boolean (Logical) Values
- Geometric Data Types
- Object IDs (OID)
- BLOBs
- Network Address Data Types
- Sequences
- Arrays
- Column Constraints
- Expression Evaluation and Type Conversion
- Creating Your Own Data Types
- Summary
PostgreSQL SQL Syntax and Use
- PostgreSQL SQL Syntax and Use
- PostgreSQL Naming Rules
- Creating, Destroying, and Viewing Databases
- Creating New Tables
- Adding Indexes to a Table
- Getting Information About Databases and Tables
- Transaction Processing
- Summary
Performance
- Performance
- How PostgreSQL Organizes Data
- Gathering Performance Information
- Understanding How PostgreSQL Executes a Query
- Execution Plans Generated by the Planner
- The ARC Buffer Manager
- Table Statistics
- Performance Tips
Part II: Programming with PostgreSQL
Introduction to PostgreSQL Programming
- Introduction to PostgreSQL Programming
- Server-Side Programming
- Client-Side APIs
- General Structure of Client Applications
- Choosing an Application Environment
- Summary
Extending PostgreSQL
- Extending PostgreSQL
- Extending the PostgreSQL Server with Custom Functions
- Returning Multiple Values from an Extension Function
- The PostgreSQL SRF Interface
- Returning Complete Rows from an Extension Function
- Extending the PostgreSQL Server with Custom Data Types
- Internal and External Forms
- Defining a Simple Data Type in PostgreSQL
- Defining the Data Type in C
- Defining the Input and Output Functions in C
- Defining the Input and Output Functions in PostgreSQL
- Defining the Data Type in PostgreSQL
- Indexing Custom Data Types
- Summary
PL/pgSQL
- PL/pgSQL
- Installing PL/pgSQL
- Language Structure
- Function Body
- Cursors
- Triggers
- Polymorphic Functions
- PL/pgSQL and Security
- Summary
The PostgreSQL C APIlibpq
- The PostgreSQL C APIlibpq
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Simple ProcessingPQexec() and PQprint()
- Client 4An Interactive Query Processor
- Summary
A Simpler C APIlibpgeasy
- A Simpler C APIlibpgeasy
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
The New PostgreSQL C++ APIlibpqxx
- The New PostgreSQL C++ APIlibpqxx
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4Working with transactors
- Summary
Embedding SQL Commands in C Programsecpg
- Embedding SQL Commands in C Programsecpg
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing SQL Commands
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL from an ODBC Client Application
- Using PostgreSQL from an ODBC Client Application
- ODBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
- Resources
Using PostgreSQL from a Java Client Application
- Using PostgreSQL from a Java Client Application
- JDBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with Perl
- Using PostgreSQL with Perl
- DBI Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with PHP
- Using PostgreSQL with PHP
- PHP Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Query Processor
- Other Features
- Summary
Using PostgreSQL with Tcl and Tcl/Tk
- Using PostgreSQL with Tcl and Tcl/Tk
- Prerequisites
- Client 1Connecting to the Server
- Client 2Query Processing
- Client 3An Interactive Query Processor
- The libpgtcl Large-Object API
- Summary
Using PostgreSQL with Python
- Using PostgreSQL with Python
- Python/PostgreSQL Interface Architecture
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Command Processor
- Summary
Npgsql: The .NET Data Provider
- Npgsql: The .NET Data Provider
- Prerequisites
- Preparing Visual Studio
- Understanding the ADO.NET Class Hierarchy
- Creating an Npgsql-enabled VB Project
- Client 1Connecting to the Server
- Client 2An Interactive Query Processor
- Client 3Updating the Database with a DataSet
- Client 4A More Robust Query Processor
- Client 5Using a Typed DataSet
- Summary
Other Useful Programming Tools
- Other Useful Programming Tools
- PL/JavaWriting Stored Procedures in Java
- pgcurlWeb-enabling Your PostgreSQL Server
- pgbashWriting PostgreSQL-enabled Shell Scripts
Part III: PostgreSQL Administration
Introduction to PostgreSQL Administration
- Introduction to PostgreSQL Administration
- Security
- User Accounts
- Backup and Restore
- Server Startup and Shutdown
- Running PostgreSQL on a Windows Host
- Tuning
- Installing Updates
- Localization
- Summary
PostgreSQL Administration
- PostgreSQL Administration
- Roadmap (Wheres All My Stuff?)
- Installing PostgreSQL
- Managing Databases
- The PostgreSQL BGWRITER process
- Managing User Accounts
- Configuring Your PostgreSQL Runtime Environment
- Arranging for PostgreSQL Startup and Shutdown
- Backing Up and Copying Databases
- Point-in-time Recovery
- Summary
Internationalization and Localization
Security
- Security
- Securing the PostgreSQL Data Files
- Securing Network Access
- Securing Tables
- Securing Functions
- Summary
Replicating PostgreSQL Data with Slony
- Replicating PostgreSQL Data with Slony
- Overview
- Requirements
- Creating a Replication Cluster
- Starting the Replication Daemons
- Creating a Replication Set
- Subscribing to a Replication Set
- Changing the Cluster Topology (Re-mastering and Failover)
- Summary
Contributed Modules
Index
EAN: N/A
Pages: 261
