4.9 Mastering of resources
|
| < Day Day Up > |
|
With the introduction of the cache fusion technology and the use of cluster interconnect to communicate requests between instances, architectural changes that have evolved include resource mastering and remastering features.
Based on the demand for resources on a specific file, the resource is maintained on the node or instances that require its use the most in a multi-instance configuration. For example, suppose that instance RAC1 was reading from data file A1 and data from this file was being processed for an arbitrarily large number of user requests, and another instance, say instance RAC2, also required access to the file A1 for just a few users. Instance RAC1 would have more users accessing this file, making requests and would therefore require this resource the most. Hence, instance RAC1 would be allocated as the resource master for this file and the GRD for this file would be maintained on instance RAC1. Consequently, when instance RAC2 requires information from this file it must coordinate with the GCS and the GRD on instance RAC1 to retrieve/transfer data across the cluster interconnect. This includes all locking and managing of requests.
If users from instance RAC1 have subsequently completed their processing and the number of requests has significantly dropped to a level below what is requested by users on instance RAC2, the GCS and GES processes, in combination, would re-evaluate the situation and transfer the mastering of the resource via the interconnect to instance RAC2. This entire process of remastering of resources is called resource affinity—the use of dynamic resource remastering to move the location of the resource masters for a database file to the instance where block operations are most frequently occurring.
Resource affinity optimizes the system in situations where update transactions are being executed on one instance. When activity shifts to another instance the resource affinity will correspondingly move to the new instance. If activity is not localized, the resource ownership is distributed to the instances equitably.
While one instance manages all information regarding a specific resource, information regarding the specific resource is maintained on all nodes that need access to it. Mastering resources on the most required instance enables optimization of resources across the cluster and helps achieve load distribution and quicker startup time. While these are benefits, on a busy system, system performance could be affected if there is a constant change of load on the instances participating the cluster and the resource utilization changes frequently, causing frequent remastering of resources. However, as long as the resource is highly utilized on one single instance with minimal remastering, performance is optimized.
Remastering also happens when instances join and leave the clustered configuration. However, instead of remastering all locks/resources across all nodes, Oracle uses an algorithm called ''lazy remastering.'' Basically, this approach takes a lazy route to do a minimal amount of remastering when an instance departs from the cluster due to failures, when an instance is taken off the cluster, or when an instance joins the cluster.
Figure 4.8 is a two-node cluster with resources mastered on all of them for their respective resources. That is, instance RAC1, instance RAC2, instance RAC3, and instance RAC4 are mastering resources R1, R2, R3, R4, R5, R6, R7, and R8 respectively.
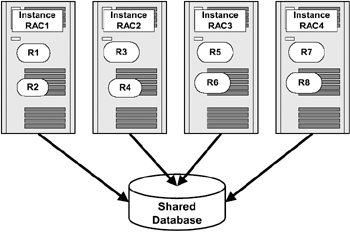
Figure 4.8: Resource mastering.
If instance RAC3 crashes, instance RAC1 and instance RAC2 will continue to master their resources, namely R1, R2, R3, and R4. The resources of the crashed instance need to be remastered among the available instances and Oracle uses the lazy mastering concept to remaster only the resources mastered from the failed instance. Consequently, R5 is inherited by instance RAC1, and R6 is inherited by instance RAC2; instance RAC4 is not affected.
Figure 4.9 illustrates the remastering of resources from instance RAC3 to instances RAC1 and RAC2 respectively. It should be noted that Oracle, instead of load balancing the resources by removing all resources and remastering them evenly across instances, only remasters the resources owned by the instance that crashed (in this case).
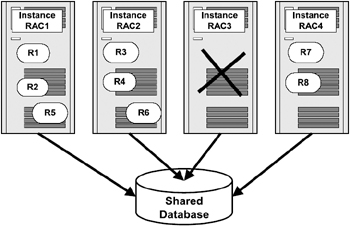
Figure 4.9: Resource remastering.
A similar type of operation happens when an instance joins the cluster. Basically, a resource is removed from each of the available instances and moved to the instance that joined the cluster.
| Oracle 9i | New Feature: Under the previous versions of Oracle (early OPS), when an instance leaves the cluster, lock remastering occurred by deleting all open global locks/resources on all instances across the cluster and redistributing these locks/resources (including the resources of the failed instance) evenly across surviving instances. During this period all instances went through a freeze period and caused performance concerns. This delay does not exist with dynamic fast remastering of resources under Oracle 9i. |
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174