EXTRACTION AND LOAD
| only for RuBoard - do not distribute or recompile |
EXTRACTION AND LOAD
Some of the problems associated with the extraction of data have already been described in this book. There are tools that might help with the extraction process, and the various types are described and discussed in Chapter 10.
There are two types of data load to be considered when designing a data warehouse:
-
Initial load
-
Incremental loads
Initial loading generally relates to circumstances rather than behavior. It includes the creation of customers, products, promotions, and geographic data such as branches and regions . The only time we need to consider the initial loading of behavior is in cases where there is some historical behavioral data to be loaded. Initial loading can be considered as a one-off exercise and does not have to be conducted as rigorously as the continuing incremental loads.
If the initial load does not work for any reason, it is a relatively simple matter to drop the whole lot and start over. We cannot take this approach with incremental loads, since dropping the previous data would then entail rebuilding the entire database.
Speed in loading data is a critical element in the management of a data warehouse. We are usually presented with a minimal time window within which to complete the process. This time window is invariably overnight. Also, we almost always have to obtain the data from the operational systems and this means waiting until their overnight batch processing has completed. In reality, this means that we can consider ourselves lucky if we have more than four hours in which to extract the data, carry out the VIM processing, and then load the data. Bear in mind that loading data into the warehouse might not be the only loading that has to be done. We often have to load data out of the warehouse into the applications that use it. We may also have to build summary tables to enhance the performance of some of the applications. All these things are resource intensive .
There are some things we can do about the speed:
Sorting. It is often a good idea to load the data in the same sequence as the primary key of the target table. This will significantly aid the ultimate performance of the system. It is usually 10 times quicker to sort the data outside the database using a high-performance sort utility.
Direct Loading. All RDBMS products have a utility that enables data to be bulk loaded, and it is always the fastest way to get data into the warehouse. The only issue is that they still tend to use SQL insert commands to load the data. Some RDBMS products allow for what is known as direct loading. This effectively bypasses SQL and allows the data to be dumped into the database files directly. Again, this can be an order of magnitude faster than standard inserts .
Index building. Best loading performance, on large volumes , is achieved without indexes. The indexes can be built after the data has been loaded. If we opt to use direct loading (above), then we can only do this with indexes switched off.
No recovery. This is another bulk-load performance enhancing feature. What this does is switch off the transaction logging function. Transaction logging is very important as an aid to restart and recovery in transaction processing systems. It is not really much use in bulk loading, and it is a significant overhead in performance terms.
Another serious issue about which there is little information is a subject known as backout. Usually, as far as transaction data is concerned , the data is passed to the warehouse from a source application system. As an example, let's assume this happens on a daily basis. The data will probably appear as an extracted file in a certain directory or other place within the system. The data warehouse data collection process will scoop up the file and copy it into the warehouse environment for further processing (e.g. VIM) and subsequent loading. Once loaded, the data will find its way into all areas of the CRM system, into summaries, the campaign management system, the derived segments, etc.
It is not unknown that, after one or two days have passed, sometimes more, someone notices that the data was, in some way, invalid. This could be that:
-
It was the previous day's data that had not been cleared down properly.
-
Someone allowed the wrong data into the operational system. This data filtered into the data warehouse.
-
Some important process or set of processes had not been applied to the data, or had been applied twice.
-
The wrong pricing tables had been used.
Any number of operational errors can occur that might not be detected before the data is loaded into the warehouse. The operational systems can often be corrected by restoring and rerunning. Whether this is possible in the data warehouse depends on scale and complexity. If we can't simply restore and rerun, then the data, in effect, needs to be unpicked from all the places in which it is stored. One way to do this is attach some kind of production run-number tag to each record at the lowest level of granularity within the system. This means that we can reach into the tables and simply delete all the rows with the offending production run-number tag. Summary tables are more of a problem. By definition, a single summary record contains data from many records of lower grain. For summaries, there are two main solutions:
-
Rebuild the summary. This should be possible so long as the summary table contains no more history than the detail. It is quite common in data warehousing to adopt a data strategy whereby we keep, say, six months of detail data and three- years of summary data. Clearly we cannot rebuild a three-year summary table in this example.
-
Reverse out the offending values. This involves the taking of the original file that was in error and reversing the values (i.e., changing the sign). This has to be done to all monetary values, quantities , and counts. Then the changed file is reapplied to the same summary level tables as before. So we are, in effect, subtracting the incorrect values out of the summaries.
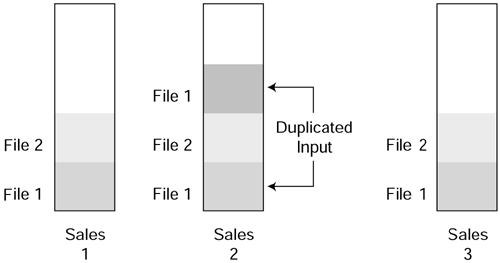
Incidentally, there is a quick way of removing duplicated rows from a table in a relational database. Have a look at the diagram of a sales table in Figure 7.11.
Figure 7.11 shows that a file of data (File 1) was inserted into the table Sales 1 and, subsequently, data from File 2 was also inserted. Then File 1 was erroneously inserted into the table again, as shown in Sales 2. In reality, several files may have been entered over several days, and simply dropping the table and rebuilding it might be an unattractive option. It is possible to write an SQL procedure with a fairly complex where exists clause, but the simplest approach is to make use of the fact that relational theory is closely related to set theory and use the power of the union.
Figure 7.11. Duplicated input.
Just create a temporary table (called Temp ) with the same structure as the original sales table and execute the following:
Insert into temp (Select * from Sales Union Select * from Sales)
This simple query will result in the removal of all duplicates as shown in Sales 3 in Figure 7.11.
For those readers who are very familiar with the capabilities of SQL, this might seem like a trivial example, but it has been used with great effect in solving real-life problems.
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 96