Index Key Terms and Concepts
| < Day Day Up > |
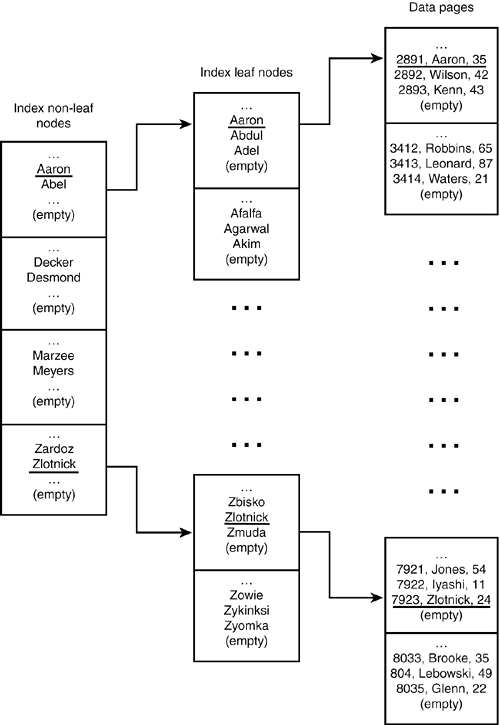
| Before proceeding into a discussion of optimal indexing, this section quickly discusses several crucial key terms and structures. To make the illustrations as clear as possible, you can first create, populate, and index a very simple table: CREATE TABLE sample_names ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, last_name CHAR(30) NOT NULL, age SMALLINT NOT NULL, INDEX (last_name) ); Now, Figure 7.1 looks at proceedinga simplified diagram showing the structure of the last_name index. Figure 7.1. Structure of the B-tree index on the last_name column.
Figure 7.1 represents a B-tree index, which is the index format MySQL uses for all of its data types (including those that may be used in FULLTEXT indexes) and storage engines, with two exceptions:
You can gain several very important insights by examining Figure 7.1:
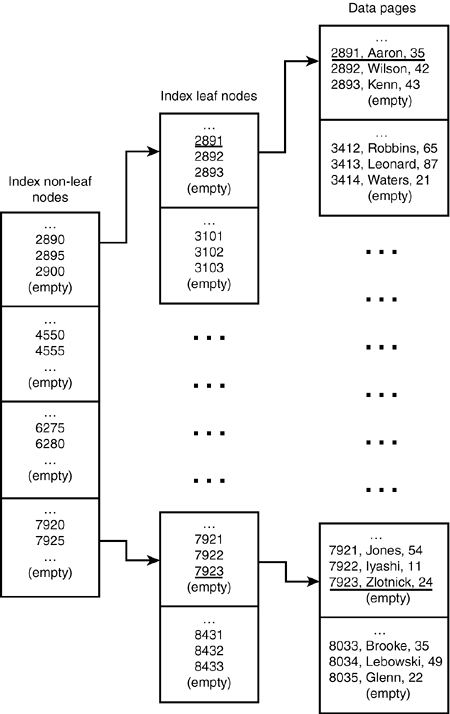
In the previous examples, the data is not stored in the order of the last_name index. However, it is stored in primary key order, so take a look at Figure 7.3, a diagram of the index on id. Figure 7.3. A B-tree index with data stored in key order.
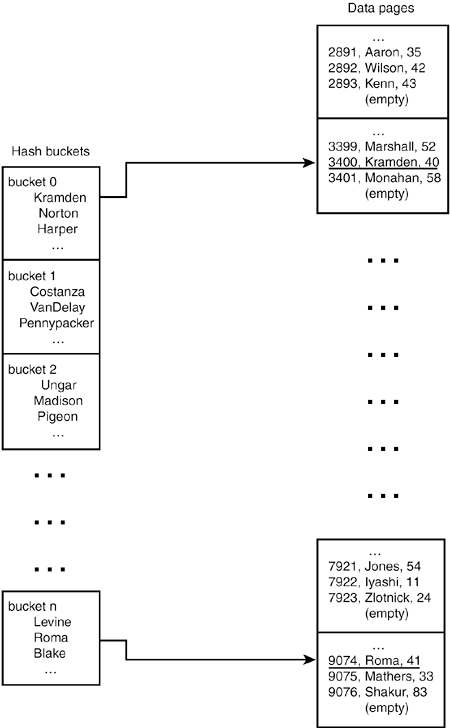
As you can see, the actual data is stored in id order. That is, each page contains a group of rows that have nothing in common other than each row's id number is one less than the one that preceded it. The pages themselves are sequenced by the values of their rows' id field. A little later, you'll see how you can change the physical order of your data. Next, suppose that you used the MEMORY storage engine for this table and requested a hash index: CREATE TABLE sample_names ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, last_name CHAR(30) NOT NULL, age SMALLINT NOT NULL, INDEX USING HASH (last_name) ) ENGINE = MEMORY; Hash indexes provide very fast access to information but are a little harder to visualize (see Figure 7.4). Figure 7.4. Hash index structure.
Without going into deep technical detail on the algorithms used to build these structures, understand that when you generate the index or insert a new row into the table, MySQL maps the index key into a hash bucket (which is a memory structure, not a container for breakfast or recreational drugs). The hash bucket then contains pointers to the data itself. Depending on the amount of available memory and other factors, MySQL generates a number of these hash buckets. Internal algorithms then determine which entries are then placed into the buckets. Generally, these algorithms have little to do with the data itself, but are instead focused on implementing a round-robin or other distribution strategy so that no particular bucket gets overloaded. Notice how the data itself is stored in the order of the primary key (id), just as it would have been for a B-tree. When it comes time to find the row (during a query or other operation), MySQL takes the lookup criteria, runs it through the hashing function, locates the correct hash bucket, finds the entry, and then retrieves the row. For added speed and flexibility, MySQL uses dynamic hashing. However, as you can see from the diagram, there is no correlation between the order of entries in the hash index and their physical location on disk. This means that a hash index can't increase the performance of an ORDER BY. |
| < Day Day Up > |
EAN: 2147483647
Pages: 131