Domain Name System
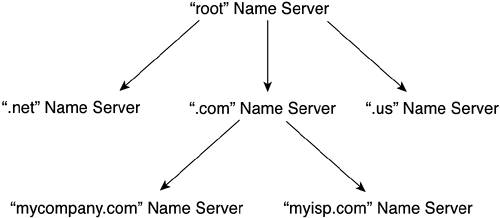
| The Internet's addressing system is what makes its destinations accessible and usable. Without IP addressing, you couldn't use the Internet or any other IP-based network. Despite this, it's a rare geek who actually uses IP addresses directly. It can be done, but it would take a better brain than I have to remember all the numeric addresses of the hosts I need to access. Another subtle benefit of mnemonics is that they greatly increase your chances of discovering new hosts. Although there are many tools for finding desired destinations, including search engines and hyperlinks, guessing at a domain name remains a very useful and expedient technique. Such a heuristic approach to finding content is much more productive than trying to guess the IP addresses of Internet sites you think you'd like to visit. Mnemonic names are absolutely essential to making the Internet, and all IP-based networks, usable and useful. Chapter 8, "Internet Names," traced the emergence of names as an informal and local-use mechanism, through its standardization across ARPANET (the Internet's predecessor), and its maturation into a standardized and hierarchical system that can reliably translate user-friendly names into numeric addresses. We stopped just shy of showing how DNS fits into the larger context of an IP-based communications session. We'll begin our exploration of the hierarchical nature of DNS by looking at how servers are distributed throughout the Internet to support name-to-number translations. As you might expect in a global network, the DNS is deployed in a highly distributed manner. Unlike some other network functions that must be built and supported for each network, DNS can work across networks. As a result, many end-user organizations choose not to build their own DNS. Instead, they use their service provider's DNS. Distributed ArchitectureThe distributed nature of DNS is a function of the Internet's namespace architecture. Thus, exploring the namespace architecture is a great way to understand DNS. The Internet's namespace is subdivided into mnemonic domains known as top-level domains (TLDs). Although the original mnemonic intent of the TLDs has become greatly diluted through misuse, the resulting hierarchy of TLDs still provides a marvelous mechanism for subdividing name resolution across the Internet. The Internet has only one root (the proverbial "dot" discussed in Chapter 8), and all the TLDs are subordinate to that root. In practice, the Internet has become so large and heavily used that it is not feasible or desirable to use just one name server for this root. More than a dozen servers back each other up and function as the place to start when you're seeking to resolve a name. For now, let's regard this root name service as a single, logical entity. Under the root are the TLDs. Each TLD has its own name server. These servers are TLD-specific; they cannot resolve names that lie in the others' domains. For example, the .com name server cannot resolve example.net. Nor does the root name server expect it to do so. Consequently, the root name server only refers queries about names within the .net TLD to the .net name server. In industry parlance, the .net name server is authoritative for the .net TLD. Figure 10-5 shows the distributed nature of name servers within the Internet on a very limited scale. Figure 10-5. The Distributed Architecture of Name Servers Within the Internet
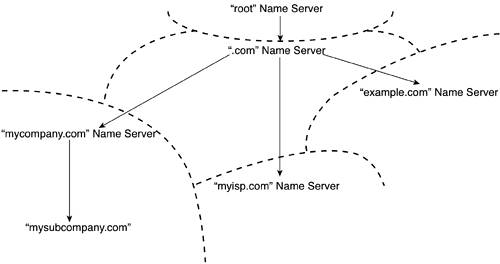
NOTE Consider the example shown in Figure 10-5 as illustrative only. In reality, the .net and .com namespaces share a single authoritative name server. Individual companies, including end-user organizations and service providers, may operate their own name servers. These servers also fit into the hierarchy. They are authoritative only for the domains run by that company. The operational implication of this distributed architecture is that you can minimize the burden of each name server in the Internet's myriad networks. A name server doesn't have to know every name defined across the Internet; it just has to know the name and address of a name server that does. To borrow a sporting colloquialism, DNS plays zone defense. The namespace is carved into zones. Responsibility for these zones is clearly defined among the various DNS servers that track Internet names and answer queries within their assigned zone. Zones Versus DomainsThe Internet's DNS uses decentralization to maintain acceptable levels of performance for name resolution. One such approach to decentralization is to carve the namespace into zones based on domain names. The result is that a given name server may be authoritative for a specific domain but not for the entire top-level domain. That probably sounded a bit vague, so let's look at a figure that helps reinforce that point. Chapter 8 showed how TLDs are carved into second-level domains (SLDs) and subdomains. There's no need to rehash things completely, so let's just focus on a TLD carved into a couple of domains. Figure 10-6 shows an example. Superimposed over the domain levels are dotted lines that show the zones of authority. Figure 10-6. Zones of Authority Relative to Domains and Subdomains
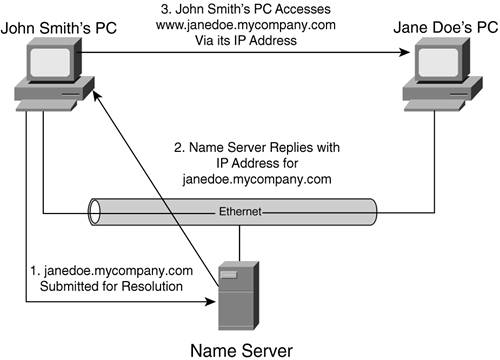
Figure 10-6 shows how zones can be created within a namespace. A separate name server can be deployed for each zone. Each name server can answer questions about names and numbers for servers defined within its domain or subdomain. The only subdomain in evidence is mysubcompany.com, which is a subsidiary of mycompany.com. The subdomain mysubcompany.com does not have its own name server. It relies on the mycompany.com name server. In other words, the name server is authoritative for that subdomain. For names that are outside its zone, the name server can figure out whether the query is of a higher or lower level relative to itself in the hierarchy. Based on that determination, the name server knows which other name server either has the right information to answer the query or is the next server in the hierarchy that gets the query closer to resolution. Resolving a NameThe preceding two sections looked at how the hierarchy of the Internet's namespace influenced the distributed nature of DNS. We touched on the concept of name servers but skipped the process of translating mnemonic names into numeric IP addresses. Translating a name into a numeric address breaks down into two distinct functions. We've already looked at the name server. The other service is known as the resolver. We'll cover both the name server and the resolver in more detail in the next two sections. By way of exploring the functions of these two servers, you can also see more precisely how name resolution fits into the context of an IP communications session. Name ServersYou've seen a bit of how the name servers are arranged hierarchically and are given authority over a specific zone. What you haven't seen is how that hierarchy of authority actually works. The name server keeps a table of all names defined in the Internet's various domains. When queried, the name server replies. The distributed nature of DNS means that you can configure certain name servers to be authoritative for their zone. When queried, the name server responds with the appropriate IP address for the mnemonic being queried if it resides within the name server's authoritative zone. If the mnemonic lies outside the name server's authority, the name server is obligated to respond with the IP address of the next name server in the hierarchy that it believes is the next step closest to the host name being queried. In this manner, a name server might not be able to answer your questions, but it gets you closer to the answer. ResolversA resolver is a computer that receives requests from applications, which might reside on different computers, such as end-user workstations. The resolver then polls its list of name servers to retrieve the needed information. After receiving that information, it interprets it to see if it looks valid or erroneous. If the information is valid, the resolver responds to the requesting application. Some versions of resolver software are more sophisticated and can build a cache of names that have been resolved. This has the significant benefit of reducing the amount of time and resources required to resolve names. You still have to go through the process of contacting name servers to get an answer the first time, but subsequent queries can be satisfied by checking the cached table of names and addresses. It is important to note that having resolvers doesn't necessarily displace the burden of resolution. Indeed, the name servers are still ultimately responsible for resolving a name into an IP address. The role of the resolver does, however, mitigate the workload placed on name servers by intercepting requests and by chasing down the correct answer to the query. The next section shows the interaction between an end user, the resolver, and the hierarchy of name servers. Walking Through the ProcessUnless the resolver knows that the name being queried is within its domain, or already has it cached, the resolver starts at the top of the appropriate domain name tree and follows the hierarchy of authority. If we go back to the example of John Smith accessing a website on Jane Doe's desktop, we can walk through the process. Assuming that both people (and, more saliently, their computers) reside within the same domain and share a common name server that is authoritative for that domain, the example is relatively straightforward. John Smith attempts to establish an HTTP session with Jane Doe's computer by feeding his browser the address www.janedoe.mycompany.com. Although that address might satisfy the requirements of the application software, it doesn't fly as far as TCP/IP is concerned. That protocol suite must seek a translation of janedoe.mycompany.com into an IP address before it can do anything else. In this example, we've conveniently located a DNS name server on the same LAN as both John's and Jane's computers. The IP address of that name server is statically configured on each computer in that network, so they all know where to go to get a good name-to-number translation. Figure 10-7 shows the steps required for that translation. Figure 10-7. Resolving a Name Within the Same Domain and Zone of Authority
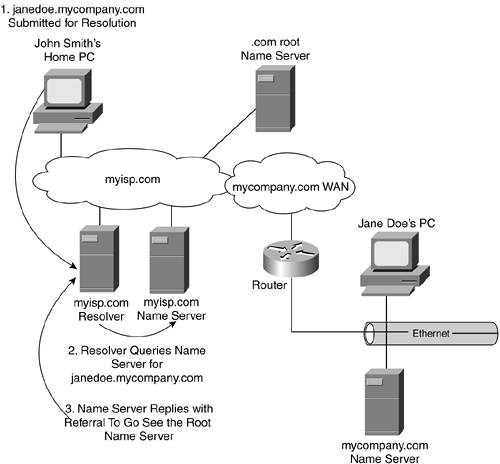
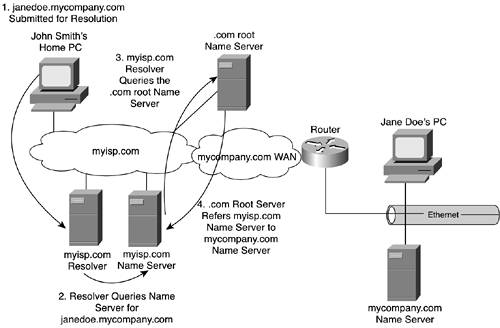
John Smith's computer sends a request to the name server. Because this is a small environment, the load on the server isn't great. Thus, the decision was made to not purchase and install a separate machine to specialize as a resolver. The name server can step up to the extra work. The name server recognizes that the host name lies within the mycompany.com domain and that it is authoritative for that domain. As a result, no referrals or recursive queries are needed. The name server simply looks up janedoe in its table and replies to John Smith's computer with the IP address that corresponds to janedoe. Now John Smith's computer knows how to get the website hosted by that computer. This example is almost too simple. Yet it shows how things work locally. Let's stretch the example and assume that John Smith is at home and connects to his colleague's desktop website from a different domain. Suspend your belief in proper network security for the sake of this example, and just assume ubiquitous connectivity without the complexity of firewalls, demilitarized zones, or other defenses against unwanted access to a private network. That doesn't make for the most realistic of examples, but it makes the mechanics of the basic process easier to follow. Given this example, there are two approaches for resolving names: iterative and recursive. They differ only in their mechanics and where the burden of processing lies rather than in their results. We'll look at both using the example. Iterative QueriesAn iterative query is one that is completed in stages or iterations. In other words, the machine you query might not have the answer to your query, but it knows where to look for the answer. It chases down your query, getting ever closer to the answer, until it finds it. Figure 10-8 shows John Smith accessing Jane Doe's website via his local ISP. As a result, the two computers lie within the same TLD (.com) but different SLDs (mycompany.com versus myisp.com). Figure 10-8. The Iterative Process of Resolving a Name Via a Resolver That Proxies the Request to Name Servers
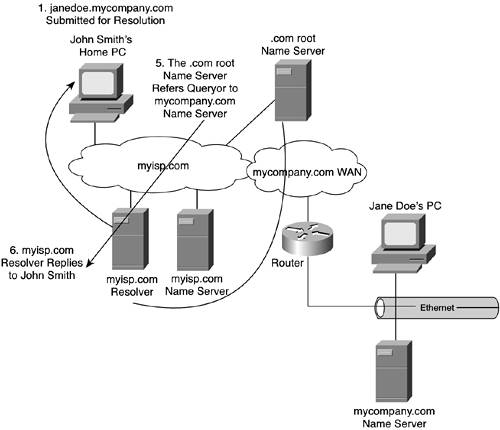
The first big difference from Figure 10-7 is that the ISP has configured a resolver. That machine becomes John Smith's first stop in trying to resolve www.janedoe.com into an IP address. The resolver accepts his query and, in turn, queries the myisp.com name server. That name server is not authoritative for the SLD being queried. Consequently, it can't provide an answer to the query. Because the resolver issued an iterative query as opposed to a recursive query, the name server simply refers the resolver to the next-closest machine to the zone of authority in which it believes the jane.doe machine resides. In this case, it refers the myisp.com resolver to one of the Internet's root name servers. NOTE The concept of iterative querying assumes that the resolver is intelligent enough to process a referral. Not all resolvers have this capability. Some, referred to as stub resolvers, can only issue queries. The resolver must then query the root name server for an IP address for mycompany.com. The root name server, however, tracks only TLDs. mycompany.com is an SLD, not a TLD. Thus, the root name server, too, must provide a referral to the resolver instead of an answer to the query. It refers the resolver to the name server that is authoritative for the .com TLD. The resolver must then query the .com name server. Unfortunately, it also doesn't know the IP address for janedoe.mycompany.com, but it does know the IP address of the name server that is authoritative for mycompany.com. It provides the resolver with that address. Armed with this information, the myisp.com resolver finally can translate John's (remember him?) request into an IP address. Figure 10-9 shows the final steps in using the iterative process to resolve a name. Figure 10-9. The Final Steps in Iterating Toward Resolving a Name
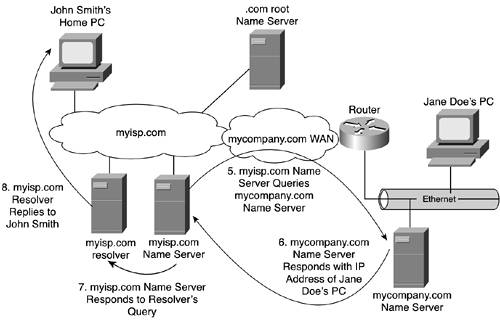
As long and painful as this process might sound, the hierarchical arrangement of zones results in a remarkably efficient distribution of workload. Provided that there are no congested areas of the Internet, or other problems, the total time to translation can be remarkably quick. I offer as proof the fact that everybody uses DNS, but few people complain about it (unless, of course, a name server is down or there are other network-affecting problems). Recursive QueriesThe recursive approach to resolving names is very similar to the iterative approach. It must be, due to the hierarchically distributed nature of DNS. Using the same example, let's look at the steps involved in a recursive query. John's computer queries the myisp.com resolver, looking for an IP address to janedoe.mycompany.com. That resolver begins by issuing a recursive query to the myisp.com name server. The fact that it is a recursive query obligates that name server to keep digging until it comes up with the answer. The resolver either does not or cannot accept referrals. That subtle difference in query type from the resolver to the name server determines where the burden of the search is placed. As you saw in the iterative query, the burden was placed on the resolver. In this case, the resolver places the burden on the name server. This is illustrated in Figure 10-10. Figure 10-10. The Recursive Process of Resolving a Name Via a Resolver That Proxies the Request to Name Servers
The myisp.com name server must go through the same sequence of events as previously described. If mycompany.com buys access and other services from myisp.com, the two name servers probably are linked hierarchically. If that's the case, the myisp.com name server can resolve John's request by querying the mycompany.com name server directly. Otherwise, the myisp.com name server knows that it isn't authoritative for the mycompany.com domain, so it issues a request to the root's name server. The root responds by referring the myisp.com name server to the .com name server. The myisp.com name server must then query the .com name server, which, in turn, recognizes that it is not authoritative for the domain being queried. But it refers the myisp.com name server to the mycompany.com name server. The myisp.com name server finally gets the answer that the myisp.com resolver is looking for when it queries the mycompany.com name server. The myisp.com resolver completes its mission by replying to John's computer with the IP address of Jane's desktop computer. John's browser can then retrieve the information it is waiting so patiently for. This is illustrated in Figure 10-11. Figure 10-11. The Last Steps in Using the Recursive Approach to Resolving a Name
It is important to realize that we skipped a step in the two iterative name-resolving scenarios we just examined. That step is converting IP addresses to physical or MAC addresses. Overlooking that little detail greatly simplified our scenarios and made it possible to focus on the role and mechanics of name servers and resolvers. The next section rounds out your appreciation of IP-to-MAC address translation by looking much more closely at the processes and mechanisms that enable that translation.
|
EAN: 2147483647
Pages: 118