Lesson 2: Microsoft SQL Server OLAP Services
In this lesson, you will cover the features, architecture, and system requirements of SQL Server OLAP Services. You will also be introduced to the Component Object Model (COM)-based Decision Support Objects programming model that makes OLAP Services an open platform for developing customized data warehousing applications.
After this lesson, you will be able to:
- Describe the features of Microsoft SQL Server OLAP Services
- Describe architecture used in OLAP Services
- Describe the programming model of Decision Support Objects
Estimated lesson time: 30 minutes
OLAP Services Features
OLAP Services has a number of powerful tools that make it the best solution for designing OLAP systems.
Ease of Use
OLAP Services has an intuitive user interface for creating, querying, and managing OLAP databases. Wizards make it easy to build complex cube structures and create dimensions.
Flexible Data Model
As we discussed briefly in Chapter 5, OLAP Services allows cubes to be stored in a true multidimensional format, relational tables, a combination of multidimensional format and relational tables, or more than one format. This flexibility allows for the best balance between storage size and performance, based on the needs of each application.
Handling Data Explosion
As you add aggregations to a cube, the size of the cube grows. For example, if a sales organization has the world divided into regions, the regions into territories, and the territories into markets, with individual stores in markets, the levels of aggregation would be at each of these points, for each product, for each product category, and for products as a whole.
OLAP Services has the ability to determine which aggregations could be quickly calculated based on other aggregations. Rather than creating aggregations at each of these levels, you can simply create the aggregations at the lowest level and have the higher-level figures calculated dynamically when needed by a query. This still allows for quick access while dramatically cutting down the disk space that is required to store all of the aggregations. We will discuss this concept in more detail later in this chapter.
Usage-Based Optimization
OLAP Services can track the queries that are run against the cubes. OLAP Services then recommends the aggregations that need to be built and the ones that need to be dropped in order to maximize performance based on the storage constraints that you set. This allows you to design the optimal balance between response time for users and the associated space requirements.
Scalability
You can handle scalability for cubes using partitions. Partitions allow you to spread a cube over multiple servers, which allows for parallel retrieval of the data. Cubes can also process just the new data rather than rebuilding the entire cube. Rebuilding an entire cube greatly increases build time.
Client/Server Cooperative Caching
On the server, queries, metadata, and data are stored in the OLAP Services cache. This means that other queries can be based on data in memory rather than having to access data on the disk.
On the client, the PivotTable Service receives both data and metadata. This allows the PivotTable Service to cache information on the client and calculate the answers to subsequent queries based on the local data. This keeps the query from actually being sent to the server, lessening network traffic and server load as well as speeding response time for the queries.
Building Cubes
There are two ways to build cubes: using the Cube wizard or the Cube Editor. The Cube wizard guides you step by step through the process of building cubes. The Cube Editor gives you total control over the creation and editing of your cube. However, it does not guide you step by step through the process and requires that you design measures.
Viewing Data
The creation of a multidimensional cube occurs in two steps. The first step is building the cube, which creates the structure, specifying the data source(s), storage options, and aggregations. The second step to cube creation is processing the cube, which populates it with the current data. SQL Server OLAP Services provides a simple Cube Browser for viewing data while you are building your cubes. The Cube Browser is available directly in the OLAP Manager and as part of the Cube Editor.
The Cube Browser is an ActiveX control that you will learn how to use in your own applications in Chapter 12, "MDX Statements and ADO MD Objects." The Cube Browser allows you to view cube data in a standard grid format. Dimensions can be chosen from a series of combo boxes at the top of the form, then dropped onto the grid and moved around. This is similar to a Microsoft Excel pivot table. The Cube Browser also allows you to drill down to the data being viewed.
In the Cube Editor, you can browse sample data in the Cube Browser even if the cube has not yet been processed. The editor will generate some artificial sample data that allows you to see how the data will look when the cube is processed. This will help you catch errors in the format of the cube.
NOTE
The Cube Browser is a straightforward tool, the primary purpose of which is to allow you to see the results of your cube design efforts. In most cases, end users will want to use a more feature-rich analysis tool such as Excel 2000 or perhaps a third-party analysis tool. See http://www.microsoft.com/sql/70/solutionsfor a list of vendors that supply cube analysis tools.
Server Architecture
OLAP Services contains both server and client components, as show in Figure 9.3.
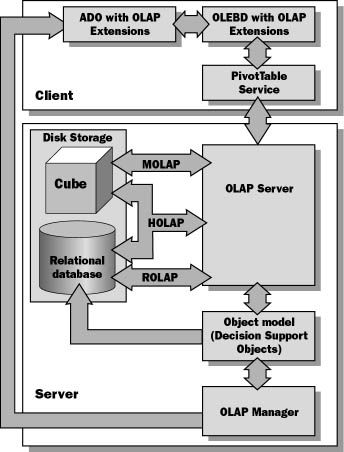
Figure 9.3 OLAP Services architecture
OLAP Services allows for the creation, management, and providing of OLAP data. The server provides the following functionality:
- The ability to create and manage OLAP cubes
- Services to retrieve the data and make it accessible to client applications
The cubes can be stored in various formats, and the metadata for cubes is stored in the OLAP Services Repository.
Client Architecture
The client provides the following functionality:
- The PivotTable Service is a client application that communicates with the OLAP Server.
- The PivotTable Service can create local cubes that are subsets of cubes residing on the server.
Client applications use the PivotTable Service to retrieve data from the OLAP database.
These applications connect to the PivotTable Service using OLE DB version 2.0 or higher (or Microsoft ActiveX Data Objects version 2.0 or higher), which returns the data to the client. The PivotTable Service communicates with OLAP Services through a proprietary protocol.
These local cubes can be used to increase performance and perform offline analysis.
PivotTable Service
The PivotTable Service is a cube storage, browsing, and analysis tool. PivotTable is an in-process OLAP Server with both online and offline analysis features that
- Provide online access to OLAP data as an OLAP Services client
- Include data analysis, cube building, and cache management features
- Allow local storage of cubes for offline analysis as well as connectivity to online OLAP Services data
OLAP Services COM Interface
Figure 9.4 shows how OLAP Services exposes its functionality through an open set of objects called Decision Support Objects (DSOs). This allows you to create custom applications that use the functionality of OLAP Services through programmatic manipulation of OLAP Services. Using DSO, you can programmatically create dimensions and cubes, process cubes, and query the multidimensional data from any environment that supports COM automation for example, Visual Basic for Applications in Excel or VBScript in Active Server Applications.
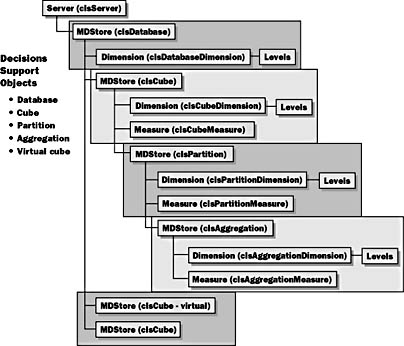
Figure 9.4 OLAP Services COM interface
Decision Support Objects
DSO provides developers with complete programmatic access to the functionality of OLAP Services, including the elements of a multidimensional data cube.
Database
A Database object contains several collections: Dimensions and their subordinate Levels collections, Datasources, Roles, and Commands. Databases also contain an MDStores collection of cubes and virtual cubes. Databases are contained in an MDStores collection under the Server object. We will define each of these collections in Chapter 12, "MDX Statements and ADO MD Objects."
Cube
A Cube object contains several collections: Dimensions and their subordinate Levels collections, Datasources, Roles, and Commands, and an MDStores collection containing one or more partitions.
Partition
A partition is one of the storage containers for cube data. Every cube has at least one Partition object, its default partition. Additional partitions can be defined, and each partition of a cube can be stored in a different physical location. A partition contains several collections: Dimensions and their subordinate Levels collection, Measures, Datasources, and an MDStores collection containing aggregations.
Aggregation
Aggregations contain several collections: Dimensions and their subordinate Levels collection, Measures, and Datasources. Aggregations are the actual data stored within the cube and are viewed in different ways, depending on what side of the cube is being accessed.
Virtual Cube
Virtual Cubes join cubes in a manner conceptually similar to the way that relational views join tables. Virtual cubes contain several collections: Dimensions and their subordinate Levels collection, Measures, Roles, Commands, and an MDStores collection. The MDStores collection of a virtual cube holds the cubes that contain information to be included in the virtual cube.
OLAP Services System Requirements
The Microsoft OLAP Server runs only on Windows NT (Server or Workstation), while the client tools can run on Windows NT or Windows 9x for offline cube storage.
Server Requirements
The following are the requirements for the server:
- Intel (Pentium 133 or higher) or DEC Alpha AXP computer
- 32MB of RAM minimum; 64MB or greater is highly recommended
- Microsoft Windows NT 4.0 Server or Workstation or higher
- Windows NT 4.0 Service Pack 4 or higher
- 50MB of hard disk space (85MB if installing common files and samples)
NOTE
Cubes built for OLAP can require substantial amounts of disk space. Even cubes that are initially small in size can grow quickly as they are reprocessed to add data.
Client Requirements
The client requires Microsoft Windows NT, Windows 95 (original or OSR2) with DCOM95, or Windows 98.

Exercise: Setting Up Your Database and Data Source
In this exercise, you will set up a database structure and connect to the database. This is necessary before you can begin building your cube.
- In the OLAP Manager console tree, expand OLAP Servers.
- Right-click your server, and click New Database.
- In the Database name text box, type Northwind_DSS.
- In the Description text box, type Northwind OLAP Services Database.
- Click OK. In the OLAP Manager console tree, expand your server, and then expand the Northwind_DSS database that you just created.
In this procedure, you will set up a connection to the sample data in the Northwind_Mart database. All your data will be coming from this source as you build your cube.
- In the OLAP Manager console tree, expand the Library folder in the Northwind_DSS database, right-click the Data Sources folder, and then click New Data Source.
- In the Data Link Properties dialog box, click the Provider tab, and then select Microsoft OLE DB Provider for SQL Server from the list.
- Click Next.
- Select or enter a server name (select your local SQL Server).
- In Enter the information to logon to the server, select Use Windows NT Integrated Security.
- In the Select the database on the server drop-down list, select Northwind_Mart.
- Click the Test Connection button to be sure that everything works. A message should appear in the Microsoft Data Link dialog box stating that your connection was successful. Click OK.
- Click OK to close the Data Link Properties dialog box.
Lesson Summary
This lesson described the main features of OLAP Services and illustrated how these features make OLAP analysis easy to use and manage. The architecture used in OLAP Services enables efficient querying of multidimensional structures and the ability to use local cubes. Decision Support Objects (DSOs) allow developers to access the features of OLAP Services from any environment that supports COM automation.
EAN: 2147483647
Pages: 114