3.2 The Internet Name Space
|
| < Day Day Up > |
|
Domain names are higher-level identifiers used by computers on the Internet. They consist of hierarchically organized character strings separated by dots, such as mail.users.yahoo.com. Domain names are not used by routers to move packets; thus, the Internet could make do without them altogether. Why give names to computers at all, then? There are two reasons.
3.2.1 Naming Computers
The first reason for naming computers is simply mnemonics. As long as there is a direct interface between human beings and the devices attached to a network, devices will be given names that are recognizable to humans. The presence of some semantic content in identifiers makes them easier to type in, easier to distinguish, and easier to remember. It also facilitates the use of naming conventions, which can make the administration of a network more orderly. Names can, for example, reflect categories or hierarchies based on geographic regions ( europe.company.com), functions ( router2.company.com), or organizational units ( accounting.company. com).
The second reason for naming computers is to provide a single, more stable identifier. The IP addresses assigned to groups of computers are determined by the topology and routing practices of a network. Both tend to change relatively frequently as networks grow, shrink, or are reorganized. If a company's network outgrows its IP address block or changes its ISPs, its hosts will have to be totally renumbered. A change in the identifier of a computer connected to a network could wreak havoc on connectivity if thousands of internal and external users have stored the old address in their routers or browsers or email address books. If domain names are used instead of IP addresses, however, the network only needs to change the mapping from the name to a new address. The change can be implemented seamlessly without disrupting users, without even requiring their participation. Also, some computers, known as multihomed hosts, have more than one IP address. Naming allows multiple addresses to be encompassed by a single identifier.
The second rationale for naming does not require that the names have any meaning. But as long as human beings are the ones defining and using the names, there is no reason not to take advantage of semantic features.
3.2.2 Names, Assignment, and Resolution
A price must be paid for the advantages of names. Their use creates the need for another assignment process; someone (or some process) must coordinate the names used on the network to ensure that each one is unique. Also, packets still have to use IP addresses, not names, to find their way across the Internet. So once names are superimposed over a device's real address, some process must match the names to addresses. In essence, one needs the equivalent of an automatic telephone directory that will look up the number for any given name. The process of mapping names to addresses is called resolving names, or resolution.
In the earliest days of the Internet, all applications for names went to a single, central authority known as the Network Information Center (NIC). The NIC accepted applications for names, weeded out duplications to ensure uniqueness, and put the names into a list called hosts.txt. The hosts.txt file served as a global directory for mapping names to IP addresses. All networks downloaded their own copy and used it to resolve names locally. But the Internet only connected a few hundred computers at that time, and its simple, flat name space could not scale up as the Internet grew. Each name of each machine had to be approved individually by a remote central organization. Every change in a name-to-address mapping in any part of the network had to be communicated to the central authority, entered into hosts.txt, and then downloaded by every other computer on the network. The larger the network became, the greater the likelihood that users would apply for the same name and hence the harder it became to assign unique names. The list itself became larger and larger, and the process of creating and distributing it consumed more and more resources. The list itself represented a single point of failure.
3.2.3 The Domain Name System
DNS was developed as a way to break out of the bottleneck created by hosts.txt and to prepare the way for unlimited increases in the scale of name assignment and resolution. Although its implementation is complex, the concept behind it is simple. The name space was divided up into a hierarchy. The responsibility for assigning unique names, and for maintaining databases capable of mapping the names to specific IP addresses, was distributed down the levels of the hierarchy. The DNS is a just a database-a protocol for storing and retrieving information that has been formatted in a specific way. The complex and interesting thing about the DNS database, however, is that it is highly distributed. Responsibility for entering, updating, and serving up data on request is assumed by tens of thousands of independently operated computers. Yet, through client-server interactions, any computer on the Internet can find the information it needs to map any name to its correct IP address. Robustness and performance improvements are achieved by replication and caching of the information (Albitz and Liu 2001, 4).
As a distributed database protocol, DNS consists of four basic elements: a hierarchical name space, name servers, resolvers, and resource records. DNS partitions the name space into a hierarchy or tree structure (figure 3.2). When the domain name is written out, the top of the hierarchy is at the right and each segment of the naming hierarchy is separated by dots.
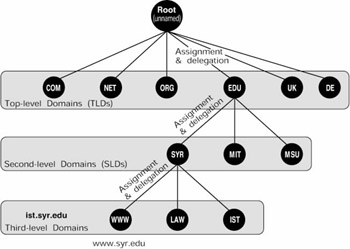
Figure 3.2: A hierarchical name space
At the top of the hierarchy there is an unnamed root. The authority in charge of the root assigns unique top-level domain names such as .com or .uk to an organization. That organization gains the exclusive authority to coordinate the assignment of second-level domain names under that toplevel domain. The registrant of a second-level domain (such as aol.com) in turn has the exclusive authority to assign unique third-level domain names ( users.aol.com) to users, organizations, or hosts under that second-level domain. And so on down the hierarchy. The protocol places certain limits on what characters can be used as names, and on the size of the character strings. [7 ]
The DNS name space provides a virtually inexhaustible supply of unique addresses. A domain name label (the string of text identifying a specific level of the hierarchy) can be up to 63 characters long. With 37 different characters available to use, the number of possible names is close to 3763- an inconceivably large number. [8 ]Multiply that times the 127 levels of hierarchy possible under DNS and the vastness of the name space is evident.
Currently, there are 257 top-level domain (TLD) names listed in the root directory. Of these, 243 are two-letter country codes drawn from an international standard. [9 ]There are also seven three-letter suffixes originally defined to serve as a rough taxonomy of the types of users (.com, .net, .org, .mil, .edu, .int, and .gov). Both types of TLD were defined in an Internet standards document in 1984. Seven new generic top-level names were created by ICANN in 2001 (see chapter 9). The limits on the number and type of top-level domain names, however, are social, not technical. The top level is just another level of the DNS hierarchy and in principle could contain as many names as any other level.
Each organization that is assigned a domain name must provide name servers to support the domain. Name servers are computers that store lists of domain names and associated IP addresses (and other pertinent data) about a subset of the name space. Those subsets are called zones (figure 3.3). Every name server below the root must know the IP address of at least one root server, and it contacts a root server when it is first turned on. At least ninety percent of name servers run an open-source software called BIND to implement their name service. [10 ]
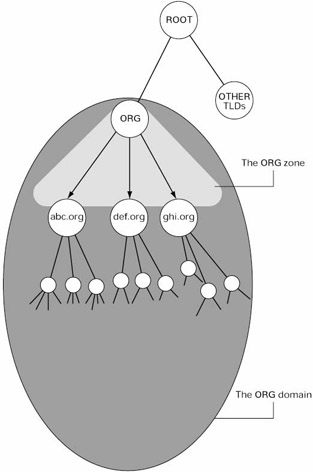
Figure 3.3: A DNS zone
Resolvers are software programs that generate queries that extract information from a name server. They reside in the end user's computer and act as the client side of the client-server interaction. The software forms a domain name query that contains the name to be resolved and the type of answer desired. It then sends the query to a name server for resolution. A resolver must know how to contact at least one name server.
Resource records (figure 3.4) are the data or content stored in name servers. Zone files are the complete and authoritative resource records for a domain. The most commonly used resource record is the A (address) record, which matches domain names to IP addresses. There are several other resource record types, however, allowing DNS queries to return additional information. Resource records contain information about who is the authoritative source of information for a domain, how current is the copy of a zone file being used, and other important administrative information. As Steve Atkins put it, 'DNS can do a lot of things besides name to address mapping if you ask it nicely.' Figure 3.5 is a diagram of the domain name resolution process.

Figure 3.4: A resource record
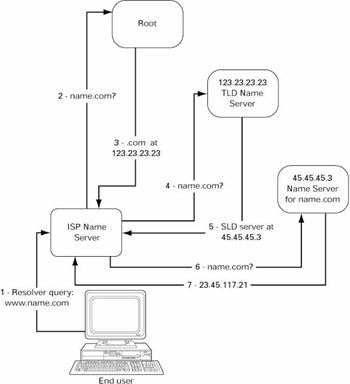
Figure 3.5: Domain name resolution process
3.2.4 Names into Numbers: Inverse Resolution
The DNS intersects with the registration of IP addresses in the in-addr.arpa domain. Every time someone is assigned an IP address, it also receives a matching domain name delegation under in-addr.arpa. For example, if an organization received the IP address 2.3.4.5, it would also register the domain 5.4.3.2.in-addr.arpa (the order of the numbers is reversed because the DNS hierarchy goes from right to left). The purpose of this rather odd practice is inverse resolution-instead of starting with a domain name and mapping it to an IP address, it allows one to use DNS to get the domain name of a machine when one knows the IP address.
Many sites, especially ftp servers and mail handlers, will check the source address on a connection to see whether it is coming from some address that properly reverse-resolves. If it doesn't, the connection will be rejected. The purpose of this practice is to act as a kind of certification that a communication is legitimate. If a name doesn't reverse-resolve properly it may be spam or some other kind of attempt to cover up the source of the message. in-addr.arpa is significant to Internet governance because it is really the only place where administration of DNS and administration of IP addresses directly touch each other. The assignment and routing of addresses is otherwise completely independent of the assignment and resolution of domain names. The need to support inverse resolution means that whoever delegates IP addresses needs to have a special domain within the DNS where IP numbers can be registered as a domain. For all practical purposes, that means we are stuck with the in-addr.arpa domain for some time, because it is embedded in software implementations and changing it would cause a lot of trouble.
[7 ]Currently, only the letters A-Z, numerals 0-9, and the hyphen character (-) can be used in a domain name, and the hyphen cannot be used as the first or last character in a domain name. Efforts are underway to internationalize domain names so that they can utilize non-Roman characters such as Chinese characters or various European alphabets. Domain names can be a maximum of 67 characters long, including the top-level domain.
[8 ]Of course, not all of them are meaningful, and as was noted in chapter 2, the value attributed by users to different names will vary greatly.
[9 ]ISO-3166-1. Maintained by DIN in Germany.
[10 ]BIND stands for Berkeley Internet Name Domain. It is a software implementation of DNS protocols that includes a DNS server, a DNS library resolver, and tools for verifying the proper operation of the DNS server. BIND is currently maintained and distributed by the Internet Software Consortium, <http://www.isc.org/ >.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 110