3.1.1 Routers and IP Addresses
|
| < Day Day Up > |
|
Unlike telephone numbers or postal addresses, IP addresses are completely independent of geography. The address structure itself tells you nothing about where the addressed host is actually located, nor does it tell a packet how to find its destination from its starting point. Internetworking requires additional protocols capable of telling packets how to get from point A to point B. There must, in other words, be some way to use the software address to find a specific physical network in a specific location.
That task is performed by routers. Routers are specialized computers connected to two or more physical networks and programmed to make decisions about how to forward data packets to their destinations. Packets work their way across the Internet by jumping from router to router- what networkers call 'hops.' To choose a path for data packets, routers refer to tables that correlate the network prefix of the packet's destination with the IP address of the next hop, the next router along the path to that destination. These routing tables can be described as a road map of cyberspace from the point of view of a particular router (figure 3.1). Every network prefix known to a router is associated with pathways through which it can be reached and the number of hops from router to router it takes to get there. The two-part structure of IP addresses is intended to make the routing of packets more efficient. Routing tables only need to contain network prefixes; they can make decisions about how to forward packets without the full address. Routers need to know the full IP address only of hosts on their own local network and of a few neighboring routers.
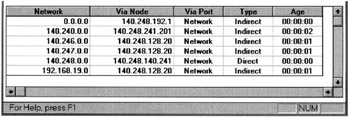
Figure 3.1: A routing table
Every time a new network address is added to the Internet, the potential size of the routing tables increases. Furthermore, routers must constantly communicate with each other to update their routing tables as new networks are added and communication links or networks go down, return to service, or are renumbered. If routing tables become too long and complex, the performance of the Internet as a whole will deteriorate. By now it should be evident that the assignment of IP addresses is constrained not only by the limits on the number of addresses available but by the capacity of routers as well. Two important conclusions follow from this.
First, the primary users of IP addresses are routers, not people. The only people who see them are the technicians working for Internet service providers (ISPs) and enterprise networks who must divide the address blocks into subnets, assign unique addresses to individual computers, and configure local hosts and routing tables. Because the addresses are invisible to people, no one imputes any economic value to the specific numbers. All they care about is whether their address block is of sufficient size to give unique identifiers to all hosts on their network, and whether the routing tables make their network visible to the rest of the global Internet.
Second, while the specific number itself is a matter of indifference, the place of an address in routing tables matters a lot. An IP address has no value unless its network prefix appears somewhere in the routing tables. A network prefix that appears in the core of the Internet-directly in the tables of the backbone routers-is more valuable than one that appears in the periphery. The reason is the speed of connection. Networks listed in the core will have better performance because packets make fewer hops to find them. Access to and placement within the routing tables is a resource every bit as valuable as the IP addresses themselves.
3.1.2 Registration
If assignments of IP addresses (actually, network prefixes) are to be exclusive, someone must keep track of which address blocks are assigned and which are unoccupied. This implies a registration process and the maintenance of a database that keeps authoritative, current records about which blocks have been doled out to which organization and which are free for assignment. That function is performed by Internet address registries (IRs). The basic structure and policies of IRs are described in RFC 2050 (November 1996). In this chapter, I set aside discussion of organizational and governance arrangements and concentrate on describing the functions of IRs.
Internet address registries are responsible for assigning address space. They stand at the second level of a hierarchy of address delegation that begins with ICANN and goes down through major ISPs and end users. IRs run publicly accessible databases that document to whom address blocks have been assigned. They also define policies for distributing addresses. The policies are designed to conserve the address space and control the size of the routing tables. Address registrations can help in the process of solving operational problems, and in fact that was their original intent. If a failure or problem traceable to a specific host or network occurs, contact information about the organization using the addresses can be helpful. As addresses in the original IPv4 address space become scarcer, however, Internet registries have increasingly used the leverage of the registration record to facilitate rationing and policy enforcement. When a company applies for additional addresses, registration authorities can check to see how many addresses have been allocated to it already and can verify whether the current allocation has been fully utilized. Furthermore, registration serves as an important check on the ability to trade or arbitrage address allocations. Companies with excess address space could auction off their surplus to those with a shortage. This practice, for better or worse, is strongly discouraged by the Internet addressing authorities. The only real leverage they have to enforce an antitransfer policy, however, is that the transferred addresses will still show up in the records of the address registries as being assigned to the original owner. Many Internet service providers will not insert address blocks into their routing tables unless the organization listed in the address registry record corresponds to the organization they are routing to. So the address registration, coupled with the router bottleneck, becomes a policy enforcement mechanism.
3.1.3 Adjustments in IP Addressing
The classical IP addressing and routing structure described in the previous section has gone through major changes since it was formally specified in 1981 (RFC 790). It is easy to forget that the address space architecture emerged from the era of mainframes and predated the personal computer. The Internet's designers never expected the Internet to grow as large as it did. By 1991 it became evident that if something didn't change, the 32-bit IPv4 address space would be used up and the growth of the Internet would come to a screeching halt. There were two fundamental problems. Classbased addressing had created structural inefficiencies by restricting assignments to address chunks of three predetermined sizes. [2 ]Only 3 percent of assigned addresses were actually being used, yet projections suggested that the rate of address assignments would exhaust the unassigned number space by 1996 or so. The growth of routing tables was also setting off alarms. Studies done in 1993 indicated that the size of Internet backbone routing tables was growing at 1.5 times the improvement rate in memory technology. The projected size of the routing tables would have exceeded the capacity of router technology by 1994 (RFC 1752).
The response to the Internet addressing crisis took three forms:
-
Tightened assignment policies
-
Development of new protocols to make address utilization more efficient and to reduce the size of routing tables
-
Creation of a new, larger address space (IPv6)
3.1.3.1 More Restrictive Assignment Early assignment procedures were based entirely on the first-come/first-served principle. Allocations of gigantic class A address blocks were free, and given away on request rather than on the basis of any demonstrated need. As an address shortage loomed, the Internet community responded by implementing administrative rationing rules and later by imposing administrative fees.
Organizations requesting address space were required to document their needs. Between 1994 and 1996 there was even some discussion of implementing auctions or full-fledged markets for address blocks, although these proposals were never implemented (Huston 1994; Rekhter, Resnick, and Bellovin 1997). Later, the assignment authorities began to charge annual fees for address blocks of various sizes.
3.1.3.2 Route Aggregation and CIDR Even more significant than the tightened assignment practices was the development of new protocols to make more efficient use of the address space and to curb the growth of routing tables. These changes started as early as the mid-1980s with the introduction of subnetting, [3 ]but most took place between 1991 and 1996.
In 1993 a new routing standard called classless inter-domain routing (CIDR) was created to make more efficient use of the available IP address space. [4 ]CIDR eliminated class-based address assignments. Instead of three fixed sizes of address block assignments, CIDR allowed network prefixes to be anywhere from 13 to 27 bits. This allowed the assignment of address blocks to be more closely matched to an organization's real requirements. CIDR also supported hierarchical route aggregation. Route aggregation is the practice of forwarding all packets with the same network prefix to the same next hop, allowing a router to maintain just one entry in its table for a large number of routes. Hierarchical route aggregation applies this method recursively to create larger and larger address blocks out of shorter and shorter network prefixes.
CIDR implementation led to an important shift in the economic structure of IP address assignment. In order to promote route aggregation, the Internet technical community needed to align the assignment of address blocks with the connection topology. As Hofmann (1998) observed, this led to an interesting debate over how to define the Internet's geography- would it be based on political territories or on Internet service providers? The provider-based model won. Usually, a service provider's network will be a topologically cohesive entity, which means that a single routing table entry can be used for all hosts served by that provider. The push for route aggregation led to a more hierarchical approach to address assignment. The central Internet addressing authorities would assign large blocks of numbers to the larger commercial ISPs. The larger ISPs would then allow end users to use parts of the assignment, but the ISP retained control of the assignment. In other words, addresses were loaned, not assigned, to end users such as business networks, organizations, and smaller ISPs. IP addresses were no longer portable across Internet service providers. End users who changed their service provider would have to renumber their networks-a costly and labor-intensive process. The change raised other concerns. As one Internet veteran put it, 'Route aggregation tied to topology based allocation, although necessary . . . is leading us down a path in which today's arteries of packet flow are being hardened, deeply entrenching the current shape of the Internet.' [5 ]The practice had tremendous success, however, at reducing the growth of the routing tables to manageable proportions.
3.1.3.3 Creation of a Larger Address Space CIDR and related adjustments were originally perceived as stopgap measures to buy time for more fundamental changes. In 1992 the Internet Engineering Task Force (IETF) formed the Internet Protocol next generation (IPng) working group to develop a new Internet Protocol with an enlarged number space. The final specifications for IPv6, as IPng is now officially called, were adopted in mid-1995. Software implementations began in 1996. Portions of the IPv6 address space were delegated by IETF to address registries in 1999. IPv6 is designed to be an evolutionary step from the older Internet Protocol. It can be installed as a software upgrade in Internet devices and is compatible with the older version of IP.
The IPv6 address space is 128 bits, which allows for nearly 1039 unique numbers. That number is, as one writer put it, 'so big we don't really have a convenient name for it-call it a million quadrillion quadrillion. This is many more than the number of nanoseconds since the universe began (somewhere around 1026), or the number of inches to the farthest quasar (about 1027).'
[6 ]Ironically, however, the measures taken to preserve the older IP address space have been so successful that the transition to IPv6 is taking place more slowly than anticipated. Dynamic address assignment, which allows addresses to be shared, and network address translators (NATs), which allow entire organizations to hide behind a few addresses, are having a major impact. Some analysts insist that the widespread adoption and deployment of IPv6 is not a foregone conclusion.
To wrap up, between 1991 and 1996 the IETF developed a significant number of new standards that dramatically extended the life of the original IPv4 address space. It also developed an entirely new Internet Protocol with an enlarged address space. Most of this activity took place while the Internet was being commercialized and was exploding in size-a pretty remarkable record of achievement. The most interesting thing about these changes from the viewpoint of this book, however, is that they were defined and implemented entirely within the Internet technical community's established institutional framework. Major resource constraints, technological adjustments, and large shifts in the incidence of costs and benefits did not spark a visible political crisis of the sort that led to the White Paper and ICANN. The adjustments did bring with them some quiet evolution in the relevant institutions (mainly the formation of regional address registries), but it did not catalyze institutional innovations. This development will be explored in later chapters, when organizational and historical aspects of the story are considered.
[2 ]Class C networks, with room for only 256 hosts, were too small for most organizations, and few applications were received for them; The huge class A assignments were massively underutilized by those lucky enough to get them. Class B assignments began to run out rapidly.
[3 ]RFC 950 (1985). Subnetting allowed organizations with larger enterprise networks to turn the two-part IP address structure into a three-level hierarchy. This facilitated route aggregation at the organizational level.
[4 ]RFCs 1517, 1518, 1519, and 1520 (1993).
[5 ]Email to author from Karl Auerbach, May 18, 2000.
[6 ]Office of the Manager, National Communications System, 'Internet Protocol Next Generation (IPv6): A Tutorial for IT Managers.' Technical Information Bulletin 97-1, January 1997.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 110