5.7 Obtaining Input Parameters
| The representativeness and accuracy of a performance model depends directly on the quality of its input parameters. Two practical questions naturally arise when seeking to obtain the parameters needed for the system model:
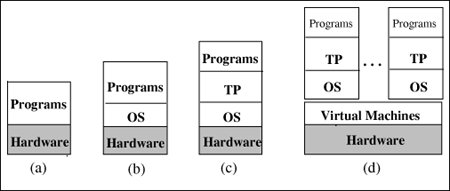
The most reliable and primary source of information is the performance measurements collected from direct observation of the system. Further information can be obtained from secondary sources such as product specifications provided by manufacturers. However, typical measurement data do not coincide directly with the input parameters required by performance models. For modeling purposes, typical measurement data need to be analyzed and transformed to become useful. Typical input parameters required by performance models are service demands, arrival rates, think times, levels of multiprogramming, and the number of active terminals. Therefore, the basic question addressed in the remaining sections of this chapter is: How is typical measurement data obtained by performance monitors transformed into the input parameters required for performance models? 5.7.1 Measuring CPU UtilizationThe services provided by the various software layers of a computer system may be abstracted and represented by the service demand parameters in an associated system model. Figure 5.7 exhibits various execution environments for application programs, ranging from the least complex environment, the bare machine, to sophisticated environments with multiple operating systems. From the definition of service demand, Di = Ui/X0. The system throughput, X0, is the number of transactions processed by the system within the measurement interval and is a relatively easy parameter to obtain. However, the utilization of a device, Ui, is subject to different interpretations, according to the specific environment. The meaning of Ui is key to understanding the concept of service demand in different execution environments. Let Uit denote the total utilization of device i measured by a system monitor and Ui,r represent the utilization of device i by class r. Bare machine. The most basic environment in which to execute an application program is for the application program to run directly on top of the hardware resources. In this case, the program has complete control over the machine with no intervening operating system service, as shown in Fig 5.7 (a). Consider the CPU. The total utilization Equation 5.7.11 where Ucpu, prog refers to the fraction of actual CPU time consumed by application programs. In a bare machine, it is reasonable to assume that only one program is executing at a time. In other words, a single program of class r monopolizes the CPU, which means that Equation 5.7.12 From the definition of service demand and from Eqs. (5.7.11) and (5.7.12), the CPU demand of the single class r program is given by Equation 5.7.13 In the case of a bare machine, Eq. (5.7.13) indicates that the CPU demand includes only the actual time a program spends executing at the CPU. Figure 5.7. Execution environments for application programs. Example 5.1.Consider an early computer system with no operating system. The system executes one job at a time. During an observation period of 1,800 sec, a hardware monitor measures a utilization of 40% for the CPU and 100 batch job completions are recorded. Using Eq. (5.7.13), the average CPU demand for these jobs is computed as 0.4/(100/1800) = 7.2 seconds per job. Operating system. Now consider an operating system that executes on top of the hardware resources and provides services (e.g., scheduling, I/O handling) to higher level applications. Application programs run on top of the operating system as illustrated in Fig. 5.7(b). The total CPU utilization in this environment is composed of two parts: Equation 5.7.14 where Ucpu, os corresponds to system overhead, (e.g., handling I/O operations, paging, and swapping). Consider a system with R workload classes. The device utilization due to each class of the workload is a fraction of the total device utilization. Thus, Equation 5.7.15 where fcpu,r is the relative fraction of the total utilization by class r. In the case of a single-class model (R = 1), fcpu,1 = 1. Various ways of calculating fcpu,r are discussed later in this chapter. From Eqs. (5.7.14) and (5.7.15) it follows that the CPU demand is given by Equation 5.7.16 Eq. (5.7.16) indicates that the effects of the OS on the performance is incorporated into the model implicitly through the way the service demand is calculated. For instance, the larger the overhead represented by Ucpu,os, the larger the CPU demand. Example 5.2.Consider a computer system running batch programs and interactive commands. Suppose the system is monitored for 1,800 sec and a software monitor indicates a total CPU utilization of 60%. For the same period of time, the accounting log of the operating system records the CPU time for batch jobs and interactive commands separately. From the accounting data, the analyst obtains the CPU utilization by class: batch = 40% and interactive = 12%. The number of interactive commands is also observed to be 1,200. Note that since the accounting data do not capture the OS usage of the CPU, the two utilizations, 40% and 12%, do not add up to the total CPU utilization, 60%. The 8% difference is due to the OS. Using these measurement data, the CPU demand for the interactive class is given by
Transaction processing monitor. A transaction processing system (TP) (e.g., IBM's CICS or BEA's Tuxedo) is an on-line real-time multiuser system that receives transaction requests, processes them, and returns responses to these requests [9]. The processing of a transaction request usually involves accessing a database. A key component of a transaction system is a TP monitor, which has the responsibility of managing and coordinating the flow of transactions through the system. The TP monitor provides a collection of services, such as communications control, terminal management, presentation services, program management, and authorization. Thus, a TP monitor provides a transaction execution environment on top of a conventional operating system, as illustrated in Fig. 5.7 (c). The total CPU utilization is viewed as a combination of three different components: Equation 5.7.17 where Ucpu,tp indicates the CPU utilization by the TP monitor. Consider now a system where multiple workload classes are executing on top of the transaction monitor. A portion of the total CPU utilization is allocated to the TP monitor. Of this allocation, a certain percentage is further allocated to the individual workload classes. Thus, the CPU utilization of a class r transaction running on top of the TP monitor is Equation 5.7.18 where Equation 5.7.19 where Equation 5.7.20 where Equation 5.7.21 The terms Ucpu,os and Ucpu,tp of Eq. (5.7.21) indicate that OS and TP overheads are included as a part of the CPU demand of class r. Example 5.3.Consider a mainframe that processes three classes of workload: batch (B), interactive (I), and transactions (T). Classes B and I run directly on top of the operating system, whereas user transactions, T, execute within the TP monitor. There are two distinct classes of T transactions: query and update. The performance analyst wants to know the CPU demand of the update transactions. Measurements collected by a system monitor for 1800 sec indicate a total CPU utilization of 72%. The accounting facility records CPU utilization on a per-class basis, giving the following: [Note: If the total 140 sec of CPU time spent by the update transactions is divided by the number of such transactions executed (i.e., 400), an average of 0.35 sec per transaction results, representing half of the true service demand as computed above. This simplistic computation does not take into account the operating system overhead, which must be included.] Virtual machine: multiple operating systems. The ability to run multiple operating systems on a single processor has provided convenience and flexibility to users. By using processor scheduling and virtual memory mechanisms, an operating system is able to create the illusion of virtual machines, each executing on its own processor and own memory. Several virtual machines share an underlying common hardware (i.e., bare machine). The usual mode of sharing within a virtual machine is multiplexing, which involves allocating time slices of the physical processor to several virtual machines that contend for processor cycles. Virtual machines enable the creation of various different execution environments all using a single processor. However, there is a price to pay for this additional flexibility: degraded performance. The larger the number of virtual machines, the higher the performance degradation. VM is IBM's implementation of virtual machines on its mainframes. VM provides both interactive processing facilities and the capability to run guest operating systems. For instance, on a single mainframe, it is possible to have a situation where several versions of different guest operating systems (e.g., MVS and VSE) run simultaneously with interactive users (e.g., CMS) on top of a VM system. Fig. 5.7 (d) illustrates the existence of various execution environments on top of virtual machines that all share a common hardware complex. The point here is to answer the following question: How does the service demand reflect the existence of various virtual machines executing on top of a single real processor? In a virtual machine environment, we view the CPU is shared by different layers of software, which can be expressed by the following: Equation 5.7.22 where Ucpu,vm represents the CPU utilization by the host operating system responsible for implementing virtual machines and supporting different guest operating systems. Thus, J different guest operating systems may coexist. On top of each of them, K different classes of workload may exist, some of them may run on top of a TP. Additionally, it is possible to have R different classes of transactions within the TP monitor. The CPU utilization by class r transactions running on top of a guest operating system can be written in a general form as Equation 5.7.23 Equation (5.7.23) can be viewed as a product of the total CPU utilization by three factors, each representing the fraction of CPU time received by each layer (i.e., VM, TP, and individual workload class) that makes up the execution environment. The total CPU utilization allocated to an individual guest operating, os, is represented by the fraction: Equation 5.7.24 where Equation 5.7.25 where Example 5.4.Consider a virtual machine (VM) scheme that supports an execution environment with three guest operating systems: one for production (e.g., MVS1), one for development activities (e.g., MVS2), and one to handle a number of interactive users (e.g., CMS). The VM environment runs on top of a mainframe with a single processor. The production OS processes two workload classes: batch (B) and transaction (TP). The TP monitor supports the execution of two classes of transactions: query and update. The goal of this example is to calculate the average CPU demand for update transactions. A system monitor observes the behavior of the mainframe for 1800 seconds. During this time it records a CPU utilization of 97%. For the same period, a software monitor of the VM system measures the following utilizations for the guest operating system: A similar calculation estimates the CPU demand for the batch jobs that run on the production system. Suppose that 80 production batch jobs complete during the observation period. Adapting Eq. (5.7.25) to this situation (i.e., considering only the CPU allocation to the production OS and the corresponding suballocation to the batch class), it follows that
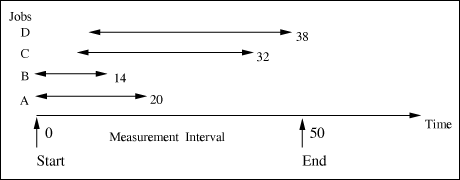
5.7.2 Overhead RepresentationOverhead consists of resource usage by the operating system. Overhead has two components: a constant component and a variable component. The former corresponds to those activities performed by an OS that do not depend on the level of system load, such as the CPU time required to handle an I/O interrupt. The variable component of overhead corresponds to these activities that are dependent on the system load. For instance, as the number of jobs in memory increases, the work required by memory management routines also increases. There are two approaches for representing overhead in performance models. One approach uses a special workload class of the model (i.e., an "overhead" class) for representing the overhead of the OS activities performed on behalf of application programs. There are problems associated with this approach. Because of its variable nature, the service demands of the special class must be made load-dependent. Thus, whenever the intensity parameters (e.g., multiprogramming level and arrival rate) of the application classes change, the service demands of the overhead class also have to be modified. The interdependency between overhead parameters and multiprogramming mix may make this approach difficult and error prone. For this reason, unless the operating system load is itself the subject of the performance analysis, representing overhead as an independent class of the model is typically avoided. The second approach to representing overhead in performance models is to distribute overhead among the classes of application programs. That is, the overhead incurred on behalf of a class is incorporated within the class itself. This is the usual method for modeling overhead. As will be seen in the next section, the problem with this approach is the calculation of breakdown ratios for distributing overhead among the classes in correct proportions. 5.7.3 Arrival RateFor relatively long measurement intervals, the arrival rate can be approximated by the throughput of the system. In other words, assuming that the system experiences an operational equilibrium (i.e., steady state); the difference between the number of arrivals and the number of completions is relatively small. Thus, the arrival rate, lr, of class r can be estimated by Equation 5.7.26 where T is the length of the measurement interval and C0,r denotes the number of class r transactions (or programs) completed during T. Counts of completed transactions are usually provided by software monitors and program analyzers. Example 5.5.A total of 5,140 order-entry transactions are processed by a system during the monitoring period of one hour. According to Eq. (5.7.26), the estimated arrival rate is 5, 140/3, 600 = 1.428 tps. The measurement interval should be long enough to minimize initial effects and end effects, which are represented by those transactions that are executed partially within and partially outside the measurement interval. In most cases it is impractical to avoid initial and end effects. Also, the impact of such effects on overall performance is typically minimal, especially when the number of observed transaction is large. Because the number of transactions processed is proportional to the length of the interval, initial and end effects for long intervals are less significant than those for short intervals. 5.7.4 Concurrency LevelThe average number of jobs/requests being executed concurrently is an important parameter when modeling closed classes (e.g., batch jobs). The concurrency level is also called multiprogramming level in the context of multiprogrammed computer systems. There are several different methods for obtaining the multiprogramming level of a particular customer class. For instance, software monitors are able to measure and report the time-averaged number of jobs actually in execution in memory during a measurement interval [1]. If the elapsed times (i.e., memory residence times) of the n jobs executed during the measurement interval are available from the accounting logs, the average concurrency level, Equation 5.7.27 where ei,r is the elapsed time of job i of class r. Example 5.6.Consider the example of Fig. 5.8, which shows a timing diagram of the execution of four jobs (A, B, C, and D) and their respective elapsed times.Using Eq. (5.7.27), the average degree of multiprogramming is (20 + 14 + 32 + 38)/50 = 2.08. Figure 5.8. Average multiprogramming level.
[Note: Initial and end effects also impact the calculation of Alternatively, if the average response time, Rr, for class r jobs and the arrival rate, lr, of class r are available, Little's Law can be used to calculate the average degree of multiprogramming as follows: Equation 5.7.28 5.7.5 Number of Active Terminals and Think TimePossible approaches to estimate the average number of active terminals (
Equation 5.7.29 where si,r is the measured length of terminal session i of class r users. To use Eq. (5.7.29), available records of all sessions performed during the monitoring period are required. The average think time (Zr) for users of class r can be obtained either from software monitors or from measurement data. The Interactive Response Time Law Equation 5.7.30 can also be used when the average number of active terminals ( Example 5.7.Suppose that a time-sharing system supports the program development activities of 40 concurrently active programmers. The workload consists of commands entered by the programmers. During a monitoring period of 1 hour when the 40 programmers are logged on, the system executes 4,900 commands with an average measured response time of 2.5 sec. Applying Eq. (5.7.30), the average think time for this interactive workload is 40 x 3600/4900 2.5 = 26.9 sec. When using data from software monitors, special caution is required to assure that what is being reported is actually think time. There are different views for this parameter. Here, think time is defined as the time interval that elapses from the beginning of the previous command's response from the system until the next command by the user is submitted to the system. 5.7.6 CPU Service DemandAs seen in the example in Section 5.3, the basic formula for deriving the average CPU demand of class r is Equation 5.7.31 Equation (5.7.31) requires the CPU utilization on a per-class basis (i.e, Ucpu,r). In general, system monitors obtain total device utilizations but do not collect these statistics by class. Partial device utilizations by workload class are typically derived from accounting data. Since most accounting systems are intended primarily for billing purposes, they do not include any unaccountable system overhead. Consequently, it is usual to have the following relation: Equation 5.7.32 where The CPU utilization by each class can be written as Equation 5.7.33 where fcpu,r is the relative fraction of the total CPU time used by class r. The apportionment factor fcpu,r may be estimated in different ways, depending on the assumptions about the workload and the execution environment (hardware and operating system) [4].
Because of the uncertainties surrounding fcpu,r, the selected approximation is a design decision based on the particular problem and the particular workload. After solving the model, the results obtained can be used to validate the approximation selected. If the model does not match observed behavior, an alternative definition of fcpu,r may be selected. 5.7.7 I/O Service DemandsThe most commonly used approximation for deriving disk i service demands (Di,r) for class r requests is Equation 5.7.37 where Single-class disk. When the requests to a disk are all statistically similar, the disk can be modeled using a single class. In this case, disk i is dedicated to a single class r and there is no need to breakdown its total utilization. Thus, Equation 5.7.38 User disk. When a disk contains only user data and is shared by several workload classes, the fraction apportioned to each class is approximately proportional to the number of I/O operations performed by each class. Thus, Equation 5.7.39 At this point, it is appropriate to consider the assumptions behind this estimate. To understand the I/O characteristics of an application, a distinction is made between two types of operations. Logical I/O operations refer to the requests made by application programs to access file records. Physical I/O operations correspond to actions performed by the I/O subsystem to access data blocks on specific I/O devices. There is rarely a one-to-one correspondence between logical and physical operations. At one extreme, when the data required by a logical operation are already in memory (e.g., I/O buffers), no physical I/O operations result. At the other extreme, operations such as a file open or a keyed access may require several physical operations to complete a single logical operation. In general, accounting systems record logical operations, whereas system monitors count physical operations. Because systems monitors do not collect statistics by class, the number of logical I/O operations reported by accounting systems is assumed in Eq. (5.7.39). Consequently, the proportion of physical I/O operations on disk i is assumed to equal the proportion of logical operations. Swap disk. Swapping is a memory management mechanism that moves entire processes from main memory and from the swapping disk. In most operating systems, the majority of swapping is due to interactive users. To represent swapping in performance models, the service demand at each disk used for swapping purposes should be specified for each class. Swapping activity is measured by the number of swap I/O operations, which include swap-ins and swap-outs. The former refers to processes moved from disk to memory, whereas the latter corresponds to processes moved from memory to disk. The swapping requests can be apportioned among the classes proportionally to the number of swap operations attributed to each class. Thus, Equation 5.7.40 where the number of swap I/O operations is obtained from accounting data. Paging disk. Paging moves individual pages of processes from main memory to and from the paging disk. Paging activity generates significant I/O traffic and should be included in performance models of systems that have virtual memory. This activity is represented by the service demand of each class at the paging disks. The intensity of paging activities is measured by page-ins (i.e., pages moved from disk to memory) and and page-outs (i.e., pages moved from memory to disk). Page-ins cause delays to a program's progress, since the program has to wait until the page transfer completes. Thus, I/O operations due to page-ins should be considered as part of a program's demand for I/O service. Page-outs, on the other hand, cause no direct delay on a program's execution since page-outs occur when the program is either idle or when the program is concurrently executing elsewhere. Thus, page-outs are usually modeled as part of the system overhead [11, 12]. When disk i is used for paging, the fraction fi,r is approximately proportional to the number of page-ins generated by workload class r, as follows: Equation 5.7.41 |
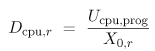


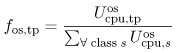
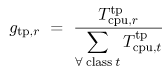
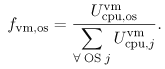
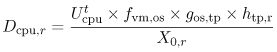
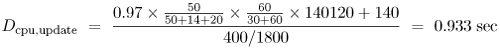
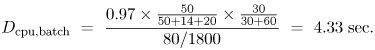
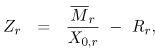
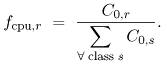
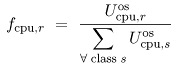
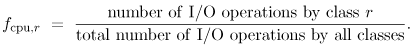
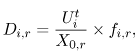
EAN: 2147483647
Pages: 166