Forward-Only Access
Forward-only access to XML is amazingly fast. If you can live with the restriction that you can process the XML data only in a forward-only method, then this is the way to go. The base abstract classes for implementing this method of access are named, intuitively enough, XmlReader and XmlWriter.
The .NET Framework class library's implementation of forward-only access, when you first look at it, seems a lot like the Simple API for XML (SAX), but actually they are fundamentally different. Whereas SAX uses a more complex push model, the class library uses a simple pull model. This means that a developer requests or pulls data one record at a time instead of having to capture the data using event handlers.
Coding using the .NET Framework class library's implementation of forward-only access seems, to me, more intuitive because you can handle the processing of an XML document as you would a simple file, using a good old-fashioned while loop. There is no need to learn about event handlers or SAX's complex state machine.
Reading From an XML File
To implement forward-only reading of an XML file, you need to use the XmlTextReader class. The XmlTextReader class inherits from the abstract XmlReader class and is made up of a number of properties and methods. Some of the more common XmlReader properties you will probably encounter are as follows:
-
AttributeCount is an Int32 that specifies the number of attributes in the current Element, DocumentType, or XmlDeclaration node. Other node types don't have attributes.
-
Depth is an Int32 that specifies the depth of the current node in the tree.
-
EOF is a Boolean that's true if the reader is at the end of the file; otherwise, it's false.
-
HasAttributes is a Boolean that's true if the current node has attributes; otherwise, it's false.
-
HasValue is a Boolean that's true if the current node has a value; otherwise, it's false.
-
IsEmptyElement is a Boolean that's true if the current node is an empty element, or in other words, the element ends in />.
-
Item is the String value of an attribute specified by index or name within the current node.
-
NodeType is an XmlNodeType enum that represents the node type (see Table 13-2) of the current node.
Table 13-2: Common XML Node Types NODE TYPE
DESCRIPTION
Attribute
An element attribute
Comment
A comment
Document
The root of a document tree providing access to the entire XML document
DocumentFragment
A subtree of a document
DocumentType
A document type declaration
Element
A start element tag
EndElement
An end element tag
EndEntity
The end of an entity declaration
Entity
The start of an entity declaration
EntityReference
A reference to an entity
None
The value placed in NodeType before any Read() method is called
SignificantWhitespace
White space between markups in a mixed content model or white space within the xml:space="preserve" scope
Text
The text content
Whitespace
White space between markups
XmlDeclaration
An XML declaration
-
Value is the String value for the current node.
Here are a few of the more common XmlTextReader methods:
-
Close() changes the state of the reader to Closed.
-
GetAttribute() gets the String value of the attribute.
-
IsStartElement() returns the Boolean true if the current node is a start element tag.
-
MoveToAttribute() moves to a specified attribute.
-
MoveToContent() moves to the next node containing content.
-
MoveToElement() moves to the element containing the current attribute.
-
MoveToFirstAttribute() moves to the first attribute.
-
MoveToNextAttribute() moves to the next attribute.
-
Read() reads the next node.
-
ReadAttributeValue() reads an attribute containing entities.
-
ReadBase64() decodes Base64 and returns the binary bytes.
-
ReadBinHex() decodes BaseHex and returns the binary bytes.
-
ReadChars() reads character content into a buffer. It's designed to handle a large stream of embedded text.
-
ReadElementString() is a helper method for reading simple text elements.
-
ReadEndElement() verifies that the current node is an end element tag and then reads the next node.
-
ReadStartElement() verifies that the current node is a start element tag and then reads the next node.
-
ReadString() reads the contents of an element or text node as a String.
-
Skip() skips the children of the current node.
The XmlTextReader class processes an XML document by tokenizing a text stream of XML data. Each token (or node, as it is known in XML) is then made available by the Read() method and can be handled as the application sees fit. A number of different nodes are available, as you can see in Table 13-2.
The basic logic of implementing the XmlTextReader class is very similar to that of a file:
-
Open the XML document.
-
Read the XML element.
-
Process the element.
-
Repeat steps 2 and 3 until the end of file (EOF) is reached.
-
Close the XML document.
The example in Listing 13-2 shows how to process the previous XML monster file. The output is a list box containing a breakdown of the nodes that make up the XML file. It is assumed that you know how to build the list box on your own. The code displays only the code relevant to the XML processing of the XML monster file. If you need a refresher on how to add a list box to a Windows Form, you might want to review Chapter 9.
Listing 13-2: Splitting the XML Monster File into Nodes
void BuildListBox() { XmlTextReader *reader; try { reader = new XmlTextReader(S"Monsters.xml"); while (reader->Read()) { switch (reader->NodeType) { case XmlNodeType::Comment: Output->Items->Add( String::Format(S"{0}Comment node: Value='{1}'", indent(reader->Depth), reader->Value)); break; case XmlNodeType::Element: Output->Items->Add( String::Format(S"{0}Element node: Name='{1}"', indent(reader->Depth), reader->Name)); if (reader->HasAttributes) { while (reader->MoveToNextAttribute()) { Output->Items->Add(String::Format( S"{0}Attribute node: Name='{1}' Value='{2}"', indent(reader->Depth),reader->Name,reader->Value)); } reader->MoveToElement(); } if (reader->IsEmptyElement) { Output->Items->Add( String::Format(S"{0}End Element node: Name='{1}"', indent(reader->Depth), reader->Name)); } break; case XmlNodeType::EndElement: Output->Items->Add( String::Format(S"{0}End Element node: Name='{1}"', indent(reader->Depth), reader->Name)); break; case XmlNodeType::Text: Output->Items->Add( String::Format(S"{0}Text node: Value='{1}'", indent(reader->Depth), reader->Value)); break; case XmlNodeType::XmlDeclaration: Output->Items->Add( String: :Format(S"Xml Declaration node: Name='{1}'"> indent(reader->Depth), reader->Name)); if (reader->HasAttributes) { while (reader->MoveToNextAttribute()) { Output->Items->Add(String::Format( S"{0}Attribute node: Name='{1}' Value='{2}'", indent(reader->Depth),reader->Name,reader->Value)); } } reader->MoveToElement(); Output->Items->Add( String::Format(S"End Xml Declaration node: Name='{1}'", indent(reader->Depth), reader->Name)); break; case XmlNodeType::Whitespace: // Ignore white space break; default: Output->Items->Add( String::Format(S"***UKNOWN*** node: Name='{1}' Value='{2}'", indent(reader->Depth), reader->Name, reader->Value)); } } } catch (Exception *e) { MessageBox::Show(e->Message, S"Building ListBox Aborted"); } __finally { if (reader->ReadState != ReadState::Closed) { reader->Close(); } } } String *indent(Int32 depth) { String *ind = ""; return ind->PadLeft(depth*3, ' '); } The preceding code, though longwinded, is repetitively straightforward and, as pointed out, resembles the processing of a file in many ways.
You process all XML within an exception try block because every XML method in the .NET Framework class library can throw an exception.
You start by opening the XML file. Then you read the file, and finally you close the file. You place the Close() method in a __finally clause to ensure that the file gets closed even on an exception. Before you close the file, you verify that the file had in fact been opened in the first place. It is possible for the constructor of the XmlTextReader class to throw an exception and never open the XML file:
XmlTextReader *reader; try { reader = new XmlTextReader(S"Monsters.xml"); while (reader->Read()) { //...Process each node. } } catch (Exception *e) { MessageBox::Show(e->Message, S"Building ListBox Aborted"); } __finally { if (reader->ReadState != ReadState::Closed) { reader->Close(); } } The processing of each of the nodes is done using a simple case statement on the node type of the current node:
switch (reader->NodeType) { case XmlNodeType::Comment: //...Process a comment break; case XmlNodeType::Element: //...Process an element break; //...etc. } The processing of most of the node types in the preceding example involves simply adding either the name or the value to the ListBox. One exception is the Element tag. It starts off like the other node types by adding its name to the ListBox, but then it continues on to check if it has attributes. If it does, it moves through each of the attributes and adds them to the ListBox as well. When it has finished processing the attributes, it moves the element back as the current node using the MoveToElement() method. You might think you have just broken the forward-only property, but in reality, attributes are only part of an element, so therefore the element is still the current node.
It is possible for an element to be empty using the syntax <tag/>, so you have to then check to see if the element is empty. If it is, you add the element's end tag to the ListBox:
case XmlNodeType::Element: Output->Items->Add(String::Format(S"{0}Element node: Name='{1}'", indent(reader->Depth), reader->Name)); if (reader->HasAttributes) { while (reader->MoveToNextAttribute()) { Output->Items->Add(String::Format( S"{0}Attribute node: Name='{1}' Value='{2}"', indent(reader->Depth),reader->Name,reader->Value)); } reader->MoveToElement(); } if (reader->IsEmptyElement) { Output->Items->Add(String::Format(S"{0}End Element node: Name='{1}'", indent(reader->Depth), reader->Name)); } break; Figure 13-1 shows the results of ReadXML.exe. It's hard to believe so much information is contained within such a small XML file.
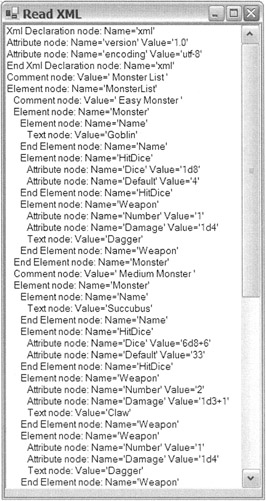
Figure 13-1: A list box dump of the XML monster file
Validating an XML File
The XmlTextReader class verifies that an XML file is well-formed—in other words, that it follows all the syntax rules of an XML file. The class doesn't verify, though, that the XML file is valid.
A valid XML file needs the nodes to be in a specific order, number, and type. You can use the following three standards for checking validity:
-
Document type definition (DTD)
-
Microsoft XML-Data Reduced (XDR) schema
-
World Wide Web Consortium (W3C) schema
Validating an XML file requires a DTD or one of the schema files. Monsters.dtd (see Listing 13-3) is an example of a DTD for the Monsters.xml file. DTD is the easiest of the three file types to work with, so you will use it.
Listing 13-3: The Monsters.dtd File
<!ELEMENT MonsterList (Monster)+ > <!ELEMENT Monster (Name, HitDice, Weapon+) > <!ELEMENT Name (#PCDATA) > <!ELEMENT HitDice EMPTY > <!ATTLIST HitDice Dice CDATA #IMPLIED Default CDATA #IMPLIED > <!ELEMENT Weapon (#PCDATA) > <!ATTLIST Weapon Number CDATA #IMPLIED Damage CDATA #IMPLIED >
You will also need to make this minor change to the XML file so that it knows where to find the DTD file:
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE MonsterList SYSTEM "Monsters.dtd"> <!-- Monster List -->
The two schema definitions, Microsoft XDR and W3C, are very different from the DTD. They are also much longer and, I think, a little less easy to read. They are, however, far more powerful. On the other hand, the application code is virtually the same for all three standards, so you won't go into the details of the schema definitions. But just to give you an idea of what a schema definition looks like, Listing 13-4 is the Microsoft XDR equivalent to Listing 13-3, which incidentally was autogenerated by right-clicking in the XML file while in Visual Studio .NET and selecting the Create Schema menu item.
Listing 13-4: The Monsters.xsd File
<?xml version="1.0"?> <xs:schema targetNamespace="http://tempuri.org/Monsters.xsd" xmlns:mstns="http://tempuri.org/Monsters.xsd" xmlns="http://tempuri.org/Monsters.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" attributeFormDefault="qualified" elementFormDefault="qualified"> <xs:element name="MonsterList" msdata:IsDataSet="true" msdata:EnforceConstraints="False"> <xs:complexType> <xs:choice maxOccurs="unbounded"> <xs:element name="Monster"> <xs:complexType> <xs:sequence> <xs:element name="Name" type="xs:string" minOccurs="0" /> <xs:element name="Weapon" nillable="true" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:simpleContent msdata:ColumnName="Weapon_Text" msdata:Ordinal="2"> <xs:extension base="xs:string"> <xs:attribute name="Number" form="unqualified" type="xs:string" /> <xs:attribute name="Damage" form="unqualified" type="xs:string" /> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <xs:element name="HitDice" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:attribute name="Dice" form="unqualified" type="xs:string" /> <xs:attribute name="Default" form="unqualified" type="xs:string" /> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
To verify an XML file, you need to implement the XmlValidatingReader class instead of the XmlTextReader class. There really isn't much difference between the two classes. The XmlValidatingReader class basically extends the functionality of the XmlTextReader class by adding verification logic.
The XmlValidatingReader class provides a few additional properties and methods beyond what is provided by XmlTextReader class to support validation:
-
Reader is the XmlReader used to create the XmlValidatingReader.
-
ReadTypedValue() is a method that returns an Object representing the CLR type for the specified XSD type.
-
Schemas is an XmlSchemaCollection containing the collection of schemas used for validation. This enables you to validate without having to reload schemas every time.
-
SchemaType is an Object that represents the schema type of the current node. The Object will be XmlSchemaDataType, XmlSchemaSimpleType, or XmlSchemaComplexType.
-
ValidationType is a ValidationType enum that represents the validation type to perform on the XML file.
Listing 13-5 shows in a minimal fashion how to validate an XML file.
Listing 13-5: Validating the Monsters.xml File
using namespace System; using namespace System::Xml; using namespace System::Xml::Schema; __gc class ValidateXML { public: ValidateXML(String *filename) { XmlValidatingReader *vreader; try { vreader = new XmlValidatingReader(new XmlTextReader(filename)); vreader->ValidationType = ValidationType::DTD; while(vreader->Read()) { //...Process nodes just like XmlTextReader() } Console::WriteLine(S"Finished Processing"); } catch (Exception *e) { Console: :WriteLine(e->Message); } __finally { if (vreader->ReadState != ReadState::Closed) { vreader->Close(); } } } }; Int32 main(void) { new ValidateXML(S"Monsters.xml"); return 0; } As you can see, there isn't much difference between implementing XmlTextReader and XmlValidatingReader. In fact, the only difference is that the XmlValidatingReader class is being used and you are setting the ValidateType property to DTD.
When you run this on the Monsters.xml file listed previously, "Finished Processing" displays on the console. To test that validation is happening, change the Easy Monster to have its HitDice element placed after the Weapons, as shown in Listing 13-6.
Listing 13-6: Invalid Monsters.xml File
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE MonsterList SYSTEM "Monsters.dtd"> <!-- Monster List --> <MonsterList> <!-- Easy Monster --> <Monster> <Name>Goblin</Name> <Weapon Number="1" Damage="1d4">Dagger</Weapon> <HitDice Dice="1d8" Default="4" /> </Monster> <!-- The rest of the document --> </MonsterList>
Now the program ValidateXML.exe will abort as shown in Figure 13-2.
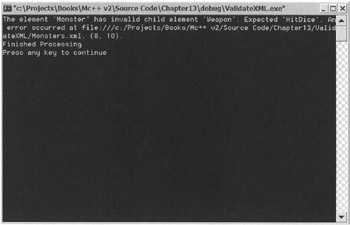
Figure 13-2: Aborting the Monsters.xml file
What happens if you want to handle the problems in the invalid XML file yourself, instead of just throwing the exception? You can override this exception being thrown by providing a handler to ValidationEventHandler. Within this handler, you can do whatever processing is necessary for the validation error.
ValidationEventHandler is triggered whenever a validation error occurs. The code for the handler is similar to all the other event handlers you've seen previously in the book. It takes two parameters, a pointer to an Object (which in this case you ignore), and a pointer to ValidationEventArgs. ValidationEventArgs provides in its properties information to tell you what caused the validation event to trigger.
Notice that you also need to import the System::Xml::Schema namespace:
using namespace System::Xml::Schema; __gc class ValidateXML { public: void ValidationHandler (Object *sender, ValidationEventArgs *vea) { Console::WriteLine(vea->Message); } //...the rest of class }; Delegating the event handler follows the same process you've seen before:
vreader = new XmlValidatingReader(new XmlTextReader(S"Monsters.xml")); vreader->ValidationType = ValidationType::DTD; vreader->ValidationEventHandler += new ValidationEventHandler(this, ValidationHandler);
Now when you execute the application, you get the same message displayed to the console, as that is the logic I placed in the handler, but the program continues on to the end of the file without an exception being thrown.
Writing a New XML Stream
There will come a time when you'll need to generate some XML to be sent to some other application or stored off for later use by the current application. The easiest way of doing this is through the XmlTextWriter class.
The XmlTextWriter class is implemented as a forward-only XML stream writer and it inherits from the abstract XmlWriter class. There aren't many commonly used properties when it comes to the XmlTextWriter class:
-
BaseStream is a Stream to which the class is writing.
-
Formatting is a Formatting enum that represents whether the XML written out is Indented or not. The default is None or no indenting.
-
Indentation is an Int32 that represents the number of characters to indent per depth level. The default is 2.
-
IndentChar is a Char that represents the character to use for indenting. The default is a space, but for an XML document to be valid, the character must be one of the following: 0x9, 0x10, 0x13, or 0x20.
Instead of properties, the XmlTextWriter class depends on a number of methods. Some of the more common methods are as follows:
-
Close() closes the streams associated with the XML writer.
-
Flush() flushes the write buffers.
-
WriteAttributes() writes all attributes at the current location.
-
WriteAttributeString() writes an attribute.
-
WriteBase64() encodes the specified binary bytes as Base64 and then writes them out.
-
WriteBinHex() encodes the specified binary bytes as BinHex and then writes them out.
-
WriteCharEntity() writes out a char entity for the specified Unicode character. For example, a symbol would generate a char entity of ©.
-
WriteChars() writes out a text buffer at a time.
-
WriteComment() writes out a comment.
-
WriteDocType() writes out a DOCTYPE declaration.
-
WriteElementString() writes out an element.
-
WriteEndAttribute() writes out an end attribute, closing the previous WriteStartAttribute.
-
WriteEndDocument() writes out end attributes and elements for those that remain open and then closes the document.
-
WriteEndElement() writes out an empty element (if empty) or a full end element.
-
WriteEntityRef() writes out an entity reference.
-
WriteFullEndElement() writes out a full end element.
-
WriteName() writes out a valid XML name.
-
WriteNode() writes out everything out from the XmlReader to the XmlWriter and advances the XmlReader to the next sibling.
-
WriteStartAttribute() writes out the start of an attribute.
-
WriteStartDocument() writes out the start of a document.
-
WriteStartElement() writes out the start tag of an element.
-
WriteString() writes out the specified string.
-
WriteWhitespace() writes out specified white space.
As you can see from the preceding lists, there is a write method for every type of node that you want to add to your output file. Therefore, the basic idea of writing an XML file using the XmlTextWriter class is to open the file, write out all the nodes of your file, and then close the file.
The example in Listing 13-7 shows how to create an XML monster file containing only a Goblin.
Listing 13-7: Programmatically Creating a Goblin
using namespace System; using namespace System::Xml; Int32 main(void) { XmlTextWriter *writer; try { writer = new XmlTextWriter(S"Goblin.xml", 0); writer->Formatting = Formatting::Indented; writer->Indentation = 3; writer->WriteStartDocument(); writer->WriteStartElement(S"MonsterList"); writer->WriteComment(S"Program Generated Easy Monster"); writer->WriteStartElement(S"Monster"); writer->WriteStartElement(S"Name"); writer->WriteString(S"Goblin"); writer->WriteEndElement(); writer->WriteStartElement(S"HitDice"); writer->WriteAttributeString(S"Dice", S"1d8"); writer->WriteAttributeString(S"Default", S"4"); writer->WriteEndElement(); writer->WriteStartElement(S"Weapon"); writer->WriteAttributeString(S"Number", S"1"); writer->WriteAttributeString(S"Damage", S"1d4"); writer->WriteString(S"Dagger"); writer->WriteEndElement(); // The following not needed with WriteEndDocument // writer->WriteEndElement(); // writer->WriteEndElement(); writer->WriteEndDocument(); writer->Flush(); } catch (Exception *e) { Console::WriteLine(S"XML Writer Aborted - {0}", e->Message); } __finally { if (writer->WriteState != WriteState::Closed) { writer->Close(); } } return 0; } This may seem like a lot of work to create just one monster in an XML file, but remember that all monsters have basically the same structure; therefore, you could create almost any number of monsters by removing the hard-coding and placing Weapons in a loop, as opposed to the expanded version shown in the preceding code. You, of course, also need some way of getting the monsters placed in the XML file. (A random generator would be cool—tough to code, but cool.)
The XmlTextWriter class takes as a constructor a TextWriter, a stream, or a filename. I showed the constructor using a filename previously. When using the filename, the constructor will automatically create the file or, if the filename exists, the constructor truncates it. In either case, you are writing to an empty file.
XmlTextWriter *writer = new XmlTextWriter(S"Goblin.xml", 0);
If you plan on allowing someone to read the generated XML, you might want to consider setting the Formatting property to Indented. If not, the output is one long continuous stream of XML text. When Indented is set, XmlTextWriter defaults to two spaces per element depth, but you can change this by setting the Indentation property:
writer->Formatting = Formatting::Indented; writer->Indentation = 3;
Okay, now to actually write the XML, the first thing you need to do is start the document using the WriteStartDocument() method. This method adds the following standard XML header to the XML document:
<?xml version="1.0" encoding="utf-8"?>
Next, you simply write the XML document. You use the WriteStartElement(), WriteString(), and WriteEndElement() methods to add elements, and for attributes you use the WriteAttributeString() method. If you want to include comments, then you use the WriteComment() method. Once you've finished adding the XML document, you finish off with a WriteEndDocument() method. You might notice that the WriteEndDocument() method automatically ends any open elements.
writer->WriteComment(S"Add a weapon element"); writer->WriteStartElement(S"Weapon"); writer->WriteAttributeString(S"Number", S"1"); writer->WriteAttributeString(S"Damage", S"1d4"); writer->WriteString(S"Dagger"); writer->WriteEndElement();
Now that you have a new XML document, you must flush out any buffers and finally close the file so that some other process can access it. As you saw with the XmlTextReader class, you check the status of the file to make sure it even needs to be closed:
writer->Flush(); if (writer->WriteState != WriteState::Closed) { writer->Close(); } Figure 13-3 shows Goblin.xml, the output of WriteXML.exe, dumped to the Visual Studio .NET editor.
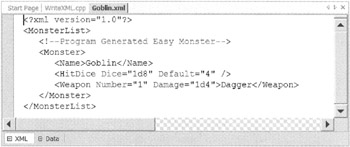
Figure 13-3: The generated Goblin.xml file
Updating an Existing XML File
You have many ways to update an XML file. Using a standard editor comes to mind. Another option, especially if you are working with a repetitive operation, is to read in the XML file using the XmlTextReader class, make your changes, and then write out the edited XML with XmlTextWriter.
A catch of using this method is that there is no backtracking with either the reader or the writer. Therefore, you must make all changes as the element or attribute becomes available or store them off temporarily.
There isn't anything new with this code. It simply isn't obvious how it's done. So here's an example of how to update an XML file in a forward-only manner. In Listing 13-8, you're adding the element <Encountered>False</Encountered> after the name of every monster.
Listing 13-8: Updating the XML Monster File
using namespace System; using namespace System::Xml; Int32 main(void) { XmlTextReader *reader; XmlTextWriter *writer; try { reader = new XmlTextReader(S"Monsters.xml"); writer = new XmlTextWriter(S"New_Monsters.xml", 0); writer->Formatting = Formatting::Indented; writer->Indentation = 3; while (reader->Read()) { switch (reader->NodeType) { case XmlNodeType::Comment: writer->WriteComment(reader->Value); break; case XmlNodeType::Element: writer->WriteStartElement(reader->Name); writer->WriteAttributes(reader, false); if (reader->IsEmptyElement) writer->WriteEndElement(); break; case XmlNodeType::EndElement: writer->WriteEndElement(); // *** Add new Monster Element if (reader->Name->Equals(S"Name")) { writer->WriteStartElement(S"Encountered"); writer->WriteString(S"False"); writer->WriteEndElement(); } break; case XmlNodeType::Text: writer->WriteString(reader->Value); break; case XmlNodeType::XmlDeclaration: writer->WriteStartDocument(); break; } } writer->Flush(); Console::WriteLine(S"Done"); } catch (Exception *e) { Console::WriteLine(S"XML Update Aborted - {0}", e->Message); } __finally { if (writer->WriteState != WriteState::Closed) { writer->Close(); } if (reader->ReadState != ReadState::Closed) { reader->Close(); } } return 0; } Notice that there is no "open for update" mode for either the reader or the writer, so you need to open up an input and an output file:
XmlTextReader *reader = new XmlTextReader(S"Monsters.xml"); XmlTextWriter *writer = new XmlTextWriter(S"New_Monsters.xml", 0);
After that, the code is standard XmlTextReader and XmlTextWriter logic. Basically, you read in each element, attribute, comment, and so on and then write them out again. When the end element of "Name" shows up, write it out and then dump out the new element:
while (reader->Read()) { switch (reader->NodeType) { //...Other cases. case XmlNodeType::EndElement: writer->WriteEndElement(); if (reader->Name->Equals(S"Name")) { writer->WriteStartElement(S"Encountered"); writer->WriteString(S"False"); writer->WriteEndElement(); } break; //...The remaining cases. Figure 13-4 shows New_Monster.xml, the output of UpdateXML.exe, dumped to the Visual Studio .NET editor.
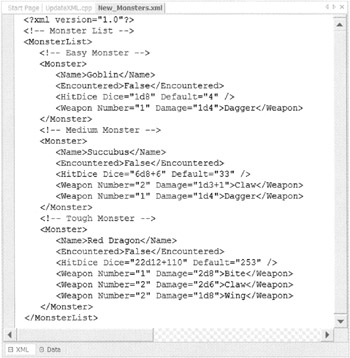
Figure 13-4: The generated New_Monster.xml file
EAN: 2147483647
Pages: 169