Compression
Compression algorithms work by detecting patterns in data and eliminating duplicates. Encryption renders plaintext into seemingly random ciphertext. The better the encryption algorithm, the more random the ciphertext will appear. Regardless of the algorithm, the effective randomness of the cipher text means that it cannot be compressed. Compressing encrypted data can even result in expansion!
As more people start using encryption at the network layer, they will soon realize that their link-layer compression (e.g., in PPP) is not only failing, but is actually a detriment to their bandwidth because it will most likely increase the amount of data being sent over PPP. Turning off link-layer compression will help make things better, in the sense that the encrypted data will not be expanded by the compression algorithm, but the user will still notice that his effective bandwidth is not what it was before he decided to encrypt his data.
When security becomes enough of a nuisance that its benefits are weighed against the benefits of not having security, some people will opt for no security, the path of least resistance. And that is A Bad Thing. Ideally, one should not have to notice security.
The IP Payload Compression Protocol (PCP) was designed to address this problem. PCP is a stateless protocol that provides network layer compression. The idea is to compress, then encrypt. That way, the benefits of both compression and encryption can be realized.
Histories are used by compression algorithms to keep track of past patterns by learning from the past history of the data, they are not condemned to repeat it, and in fact they eliminate it. But, PCP cannot take advantage of a compression algorithm's history because it must be stateless. This is because there is no guarantee that IP packets will even be delivered, much less delivered in order, and it is therefore impossible to maintain a proper compression history. The overhead of trying to maintain a history, and having to repeatedly flush it and start over when a packet is dropped or received out of order, is not worth the effort. Therefore, when a compression algorithm that utilizes histories is employed by PCP, it must flush its history buffer after each compression and decompression.
PCP, like AH and ESP, is an IP protocol. It has been assigned the number 108. An IP packet whose protocol field is 108, or an IPSec header whose next header field is 108, indicates that following is a PCP header and compressed data. Figure 12.1 shows an PCP header.
Figure 12.1. The PCP Header.
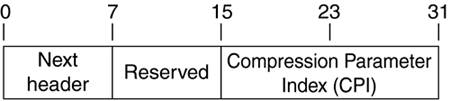
The next header field should be obvious at this point. It indicates what type of data was compressed. The PCP header contains a field much like the SPI field of an IPSec header a compression parameters index (CPI). This field, along with the destination address of the outer IP header, identifies a compression security association.
It was decided to make the CPI two bytes (instead of four like an SPI) for two reasons: alignment and a desire to keep the header as small as possible to not override the savings obtained by compressing. By making a two-byte CPI, the compressed data will begin on a 32-bit aligned boundary (keeping with IPSec) and the header is only 4 bytes long. This leaves a single byte, which is not used, and is therefore marked in the standard fashion as reserved.
The PCP security association is very minimal. Since there is really no state to retain (no key, no antireplay protection, and no history for instance), all that is needed is an algorithm identifier. In that way, a single entity can support multiple compressed sessions with various peers with different algorithms, if desired.
Like AH and ESP, PCP can be negotiated by IKE. The IPSec DOI contains a DOI-specific protocol value (which differs from its IP protocol) for PCP and also algorithm identifiers for the two-compression algorithms defined for use with PCP: LZS and Deflate. In theory, IKE could negotiate PCP in the absence of any accompanying IPSec protocol, but what's the point? The whole reason PCP was defined was to enable compression when encrypting at the IP layer or below. If encryption is not being negotiated there is no point in having IKE go through its two phases and public key operations, only to negotiate compression parameters. Also, since the performance of PCP is lessened because of its stateless requirement, if someone wanted to compress and not encrypt, they could realize much better results by compressing at a higher layer where a history can be utilized for instance, the session layer.
Processing of PCP differs from the IPSec protocols because compression is not always successful. Sometimes a PCP header will not be added to outbound packets and therefore a PCP header cannot be expected in each inbound packet, unlike IPSec processing where the header is always added and always expected.
Output Processing
In output processing, PCP is always done prior to either AH or ESP. If the compression algorithm defined in the PCP SA utilizes a compression history, that history must be flushed before the algorithm is used to compress data for PCP. The protected payload either an upper-layer protocol in the case of transport mode, or an entire IP datagram in the case of tunnel mode is then compressed by the algorithm defined in the PCP SA. If compression was successful, a PCP header is prepended to the compressed data and the resulting package is passed to IPSec for further processing and encapsulation. If compression is not successful, if the data did not actually get smaller, then the original uncompressed data is passed to IPSec processing without a PCP header. An outbound packet will only have a PCP header if the data was successfully compressed, which makes sense. This makes input processing a bit easier.
Input Processing
In input processing, the IPSec- and (possibly) PCP-protected packet is going to be sent to IPSec input processing because the protocol field of the IP header will be either AH or ESP. As the packet is decapsulated and the various IPSec headers are peeled off, the next header field of the IPSec headers must be checked. When that field indicates that a PCP header follows, we know that following that header will be compressed data. If the algorithm in the PCP SA identified by the CPI in the header, the protocol (PCP), and the destination address in the outer IP header utilizes a compression history, that history must be flushed prior to decompression. If the data cannot be successfully decompressed, the packet must be dropped, because it would be impossible to reconstruct the original data. If successful, the decompressed packet will be either an IP datagram if PCP was performed in tunnel mode or upper-layer protocol data if PCP was performed in transport mode. In the latter case, a new IP datagram must be constructed. The next header field in the PCP header becomes the protocol in the new IP datagram, the payload length is adjusted, and a new checksum is computed.
Since a PCP header will not always exist in an inbound packet, the lack of one must not be construed as an error condition in the way it is when an expected IPSec header is missing. If IKE negotiates ESP and PCP together, the packet may or may not have a PCP header, but it must always have an ESP header. Similarly, if IKE negotiates AH and ESP and PCP all together, the packet must always have an AH header and an ESP header but, depending on the data, may or may not contain a PCP header.
Taking the time and processing power to compress data only not to use the result can be a severe drag on performance. This can negate any benefit that compression would have. Some heuristics can be employed in PCP processing to maximize compression and minimize the number of times that compression is unsuccessful. Depending on the algorithm a lower-bound of data length can be fixed. Data less than, say 128 bytes, should not even be attempted to be compressed. The data is so small anyway, and any compression benefit would probably not be worth the effort; we'd be adding four bytes for the PCP header anyway. Also, by noting that successive packets will most likely not compress if the packet before did not, a good heuristic to employ is not to attempt compression on the next n packets upon unsuccessful compression of a packet. (Depending on the algorithm and the traffic, n can be 5 or 10 or maybe more.) A good example of this is when the traffic being protected is Web traffic. Any GIF image in a Web page would not compress because it's already compressed, but the text in the page would compress quite successfully. The packets that comprise the GIF will be successive, and when the first fails compression, the rest will too. By not attempting compression on the next n packets, this segment can be skipped over and processing power saved by not wasting time attempting to compress packets that will most likely not compress.
Just as there are different layers in the OSI networking model where encryption is possible, compression can be implemented at various layers as well. Compressing at a layer higher than IP will have the benefit of the resulting traffic being represented by fewer packets instead of the same number of smaller packets. Routing fewer packets is preferable to routing smaller packets. Also, when compression is done at a protocol layer higher than the network layer, a history may be utilized. Compression works much better with histories, so data will usually compress better at the session layer for example than at the network layer.
In spite of its drawbacks, PCP has been implemented by a number of vendors. It's not clear whether they all support PCP by itself or only in conjunction with an IPSec protocol, but PCP does exist and it is being used.
| Top
IPSec (2nd Edition) ISBN: 013046189X
EAN: 2147483647 Year: 2004
Pages: 76 Authors: Naganand Doraswamy, Dan Harkins
flylib.com © 2008-2017. If you may any questions please contact us: flylib@qtcs.net |