MLS Overview
| Multilayer switching (MLS) is a technology that implements both Layer 3 and Layer 2 switching in hardware application-specific integrated circuits (ASICs). To provide for Layer 3 speeds, the hardware ASICs handle the process-intensive switching that's normally done by a central processor. Because ASICs are less expensive than CPUs, MLS switches provide a decided cost advantage over the traditional CPU-based router. Given the advantage of price and performance, you might wonder why anyone would still purchase a traditional router. Unfortunately, ASICs can do only a small number of tasks, but they do those tasks very efficiently. Cisco currently supports IP and IPX Layer 3 switching in its Catalyst switches. Therefore, for a multiprotocol campus that includes protocols such as AppleTalk, DECNet, or others, a Layer 3 switch would not be a good solution. When it comes to support for almost every flavor of media type such as serial, fiber-distributed data interface (FDDI), token ring, ATM, and others the traditional router is still the platform of choice. Please note that some Cisco router platforms support advanced switching technologies, which are discussed in this chapter. Switching ArchitecturesSwitching refers to the movement of traffic from one interface to another. This process can occur at Layer 2 or Layer 3. At Layer 2, switches look at the destination MAC address to make switching decisions. At Layer 3, RPs look at the destination network address, such as an IP address, to make switching decisions. A handful of switching architectures are used in today's switching and routing equipment: processor, ASIC, route caching (NetFlow-based switching), centralized, distributed, and topology based. The following sections discuss each of these in more depth. Processor and ASIC SwitchingTwo types of hardware devices can perform switching: processors and ASICs. Processors are general types of chips that can handle many functions, but are not capable of executing all those functions equally well. A good example of a processor is the CPU found in your PC. That general-purpose processor can handle all of your operating system's tasks, execute applications, and manipulate files, but it won't provide the most optimized and efficient process for doing so. ASICs are specialized processors that perform only one or a few functions very fast. One limitation of ASICs is that they aren't plug-and-play you can't use just any ASIC for a certain task. However, because ASICs perform only a small number of tasks, their cost is much less than a processor and their speed is much faster. As an example, if you were to use a processor to switch frames between interfaces, you would get forwarding rates in the high thousands or low millions of packets per second (pps). Whereas with a specially designed ASIC, you could get forwarding rates in the tens or hundreds of millions of pps. It is not uncommon to see both types of hardware devices in the same chassis. ASICs are typically used for switching traffic, whereas either an ASIC or a processor will be used for general-purpose functions, such as running STP or handling a routing protocol such as OSPF. By separating your data (switching traffic) and control (management functions) components, you can optimize your device to obtain high levels of forwarding rates at a lower cost.
Route Caching and NetFlow-Based SwitchingWith route caching, the first time a destination is seen by the router, the CPU processes the packet and forwards the packet to the destination. During this process, the router places the routing information for this destination in a high-speed cache. The second time that the router needs to forward traffic to the destination, it will consult its high-speed cache before using the CPU to process the packet. There are many different types of route caching, including flow-based switching and demand-based switching. NetFlow switching is a Cisco-proprietary form of route caching. Route caching is a process normally used on low-level routers to enhance performance. With NetFlow switching, the RP and ASICs work hand-in-hand. Like route caching, the first packet is handled by the main processor or ASIC. If the destination MAC address matches the RP's (the Layer 3 address doesn't have to match), the processor programs its interface ASICs to process further traffic for this connection at wire speeds. The main processor will update the interface's cache with the appropriate connection information: source and destination MAC addresses, IP addresses, and IP protocol information. This is done for each direction of a connection; in other words, the table is unidirectional. So, for two devices sharing data with each other, two connections would be listed in this table. The interface ASIC would use this information to forward traffic without having to interrupt the CPU.
Centralized SwitchingIn a centralized switching architecture, all switching decisions are handled by a central, single forwarding table. A centralized switching device can contain both Layer 2 and Layer 3 functionality. In other words, this table can contain both Layer 2 and Layer 3 addressing and protocol information as well as access control list (ACL) and quality of service (QoS) information. The main concern with centralized switching is that the MLS switch must handle a lot of traffic, including Layer 3 processing. Therefore, performance is a concern. A central forwarding engine (a special type of ASIC) is typically used to handle processing of this table at very high speeds.
Distributed SwitchingIn a distributed switching architecture, switching decisions are decentralized. As a simple example, a 6500 switch has each port (or module) make its own switching decision for inbound frames while a main processor or ASIC handles routing functions and ensures that each port has the most up-to-date switching table. With the centralized approach, the central switching device has a single switching table containing all Layer 2 and Layer 3 switching information. One advantage of the distributed implementation approach is that by having each port or module make its own switching decision, you're placing less of a burden on your main CPU or forwarding ASIC you're distributing the processing across multiple ASICs. In this case, a separate forwarding engine (ASIC) is used for each port and each port has its own small switching table. With this approach, you can achieve much greater speeds than a switch that uses central forwarding for switching rates of more than 100 mpps. The main downside of distributed switching is maintaining the information in each port's switching table. To handle this function, a primary forwarding engine is used. When topology changes occur, the forwarding engine makes sure that the appropriate port tables are updated.
Topology-Based SwitchingTopology-based switching uses a forward information base (FIB) to assist in Layer 3 switching. This type of switching pre-populates the cache by using the information in the RP's routing table. If there is a topology change and the routing table is updated, the RP will mirror the change in the FIB. Basically, the FIB contains a list of routes with next-hop addresses to reach those routes. The advantage of topology-based switching over route caching or NetFlow switching is that because the information is pre-populated, the cache table doesn't have to be built, which speeds up access. However, one problem with topology-based switching is the efficiency of the search algorithm to find a match for the destination. The slower the search, the worse the bottleneck that is created. ASICs are sometimes used to speed up this process. To overcome this, the FIBs can be distributed to individual interfaces or modules to decentralize the switching process. Cisco has developed a proprietary topology-based switching FIB called Cisco Express Forwarding (CEF). CEF also includes a second table, called an adjacency table. This table contains a list of networking devices directly adjacent (within one hop) to the RP. CEF uses this table to prepend Layer 2 addressing information when rewriting Ethernet frames during MLS.
MLS ImplementationBefore I begin explaining how an MLS device performs its switching, let's take a quick overview of how a normal Layer 2 switch performs its switching function. When a Layer 2 switch receives an inbound frame on a port, the first thing the switch does is look up the destination MAC address in the CAM table. The switch then compares the inbound frame with any ACL applied to the interface. Assuming that the frame is permitted by the ACL, the switch then checks its inbound QoS policy to see how to process the frame. After this, the switch checks to see whether the outbound port has an outbound ACL. If so, the switch checks to see whether the frame is permitted to exit the outbound port. If the frame is permitted, the switch examines its QoS policies to see what type of queuing is required for this frame. The frame is then queued up and eventually forwarded out of the interface. Multilayer switching is more complicated. When dealing with Layer 3 information encapsulated in a frame, there are two ways a multilayer switch can handle this information. If the Layer 3 source and destination are in the same VLAN, the process I described in the previous section for Layer 2 switches is applied. If the inbound frame contains an encapsulated packet where the source and destination addresses are in different VLANs, the process involves more steps. In this case, the following steps are performed:
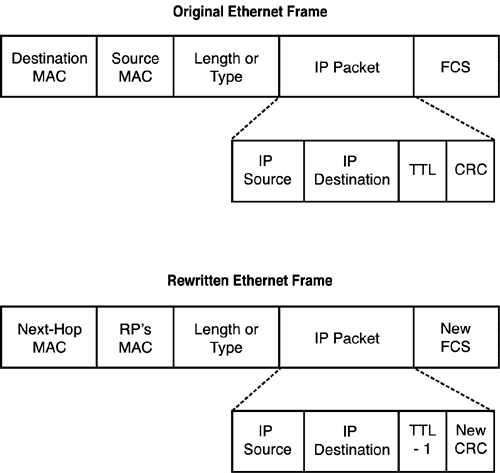
Rewriting Frame and Packet ContentsOne of the interesting things that occurs in MLS is performed in step 6. With a traditional router, when a Layer 2 frame comes in, the frame is processed, the frame's header and trailer are stripped off, and the encapsulated Layer 3 packet is then processed by the Layer 3 function of the router. An outbound interface is chosen and the Layer 3 packet is encapsulated in the appropriate Layer 2 frame. In other words, traditional routers use an encapsulation and de-encapsulation process to move data between interfaces. MLS uses a rewrite process. The fields rewritten in hardware are shown in Figure 6.2. As you can see, five fields are changed. In the encapsulated IP packet, the TTL field in the header is decremented (indicating that the packet traveled through an RP) and the CRC is recalculated. In the Ethernet frame, the source and destination MAC addresses are rewritten. The source MAC address is the RP's address in the next-hop VLAN and the destination MAC address is the next-hop device's address (which could be another RP or the final destination). Because the packet contents and MAC header addresses changed, the CRC for the frame is recalculated. To handle this in a real-time fashion, ASICs are used to provide wire-speed processing of the rewrites. Figure 6.2. MLS rewrite process.
Routable and Nonroutable TrafficAnother important item to point out is how an MLS switch handles routable and nonroutable traffic. An MLS switch can move traffic between interfaces by either using routing or fallback bridging. In either case, to maintain a high level of performance, all the switching (Layer 2 or Layer 3) is done in hardware. The MLS switch can handle routing on SVI and routed interfaces, assuming that Layer 3 addresses have been configured on these interfaces and appropriate entries are found in the MLS switch's routing table. Fallback bridging enables you to bridge either nonroutable traffic across routed interfaces, or routable traffic where a Layer 3 address was not configured on the SVI or routed interfaces. With fallback bridging, you allow traffic to be bridged between multiple VLANs in the same bridge group. A bridge group is a group of routed or SVI interfaces that are to be associated with each other. Fallback bridging is disabled by default and requires configuration on your part. By default, when routing is enabled on an MLS switch, the switch will attempt to route all traffic on a routed or an SVI interface. If you have nonrouted traffic on these interfaces and don't have fallback bridging enabled, this traffic is dropped by the router. If you have fallback bridging enabled, the router will bridge the traffic that you specify for the interfaces that belong to the bridge group or groups, but route the remaining traffic. Address TablesBy now, you should be very familiar with what a CAM table is and how a Layer 2 switch uses it to make switching decisions. However, depending on the architecture of your switch, it might contain only a CAM table, or a CAM table plus a ternary CAM (TCAM) table. As a refresher, a CAM table is a special form of high-speed memory where the switch's Layer 2 switching table is stored. This table contains a list of MAC addresses, which ports they are located off of, and which VLAN they belong to. With MLS switches, these tables can also include Layer 3 protocol and addressing information. To make a switching decision when a frame comes into a port, an efficient search algorithm is used to find the destination address in the CAM table. An exact match must be found in the CAM table in order to forward the frame intelligently. Matching is performed by comparing the binary value of the destination MAC address in the frame with the entries in the CAM table. If the destination address is not found in the CAM table, the frame is flooded out all remaining ports in the VLAN. The problem with a standard CAM table is that it must examine all entries in the table for a match and it always looks for an exact match. This can be problematic for very large CAM tables because searching these tables can be slow. Plus, there might be instances in which you want to match on some things in the CAM table, but not all things. For example, you might want to match on the first 24 bits of a MAC address and don't care about the last 24 bits. A TCAM table is a part of memory reserved for quick table lookups of information that need to be processed by an access control list (ACL). An ACL looks for matches on certain components, which sometimes fall in a range or are wildcarded. These components can include the protocol, source and destination addresses, and protocol information. TCAM tables have a small number of entries in them that are necessary for ACL processing. These entries, 32 to 128 bits in length, contain pattern values and mask values along with a matching result. Cisco calls these Value, Mask, and Result (VMR) entries. Values include IP addresses, IP protocols, and IP protocol information. Masks include wildcard masks that tell what components of the values are important. The result of a match can be a simple permit or deny, or a pointer to another entry in the TCAM table. When matching packet contents to TCAM entries, the MLS switch can base matches on three values, as compared to a CAM table's two values (0 or 1 in binary). With a TCAM match, the MLS switch can look for a 0 in a bit position, a 1, or either a 0 or a 1. One unique thing about TCAM tables is that when finding a match in the TCAM table, all TCAM entries are processed in parallel. Therefore, performance of a lookup is independent of the number of entries in the TCAM table. The length of the search is based on not how many entries exist in the TCAM table, but the number used. When performing a search, only those table entries that are required for processing are used. To assist in this process, a TCAM table is broken into three general types of regions, shown in Table 6.1. The following Cisco Catalyst switches use TCAM tables for Layer 3 switching: Catalyst 3550, 4000, and 6500.
|
EAN: 2147483647
Pages: 171