| In this section, we focus on looking at specific system activity; by this I mean monitoring processes . This involves a discussion on the life cycle of a process and the states through which a process can go during its lifetime. This includes a discussion on process threads, their relationship to processes, and why we have them. This leads to a discussion on what we can do to affect how quickly a process gets through the tasks it needs to. Ultimately, this section discusses some common bottlenecks that a system can experience in trying to perform the tasks it was designed for. At that point, we make some suggestions to try to alleviate some of these common bottlenecks. As with any performance tuning techniques, whether a particular solution is applicable in a given situation depends entirely on the situation. There is no black box of magic tricks that makes every system go faster. It depends on what you are asking your system to do. Is it running an RDBMS application performing lots of small queries on a customer database? Is it a system providing online video feeds to customers, where streaming large amounts of sequential data is the norm (you normally watch a video from start to finish, don't you?). In previous sections, we have discussed techniques relating to disks, volumes , and filesystems as well as other technologies. In those discussions, we discovered different techniques that were applicable to different situations, e.g., striping might be good for performance, but there is an impact if high availability is a concern. With all these discussions, there is always an " it depends " part to the equation. Only you will know what workload your system is asked to perform. The characteristics of that workload determines on which techniques you employ to make your system run optimally . Only you know how and what optimal means it depends . 11.1.1 Tools to monitor processes There are numerous tools available to monitor specific system activity. It depends on what we want to monitor. It also depends on what level of detail we are trying to monitor. In other words, are we looking for per-process information, or are we looking for a more general idea of what resource activity looks like? These commands are over and above the commands we have looked at elsewhere in this book to monitor things like disk space utilization, kernel parameters, swap space, and so on. Some suggestions are listed in Tables 11-1 and 11-2. Table 11-1. Generic UNIX Monitoring Tools | Command | Global system data | Per-process data | | ps | NO | YES | | sar | YES | NO | | iostat | YES | NO | | vmstat | YES | NO | | time | NO | YES | | timex | YES | YES | | uptime | YES | YES | | acctcom | YES | YES | | netstat | YES | NO | | ping | YES | NO | | nfsstat | YES | NO | | ipcs | YES | YES |
Table 11-2. HP-Specific Monitoring Tools | Command | Global system data | Per-process data | | glance | YES | YES | | gpm | YES | YES | | MeasureWare | YES | YES | | PRM | YES | YES | | cxperf | NO | YES | | puma | YES | YES |
We won't be going through laborious examples of all of these commands because I suspect that you know how to run the ps command. If you want that level of detail, you should consult the appropriate manual or, even better, attend the appropriate customer education courses. We are here to focus on particular attributes logged by one or more of these utilities. Where we think we may have a bottleneck, we focus on the specific attributes that would hint at a particular bottleneck being evident. Before we get into looking at individual bottlenecks, we need to be able to distinguish between a process and a thread. The utilities we have will manage the process as a whole. How this affects individual threads is dependent on how the process, or should I say the application, was written. 11.1.2 Processes and threads When we are managing a system and particular user activity, our focus is commonly a process. It is at the process level that we normally monitor user activity. However, the operating system doesn't schedule processes to run anymore. The operating system schedules threads to run. The difference for some people is too subtle to care about; for others the difference is earth-shatteringly different. From a programmer's perspective, the idea of a threaded application is mind-bogglingly different from our traditional view of how applications run. Traditionally, an application will have a startup process that creates a series of individual processes to manage the various tasks that the application will undertake. Individual processes have some knowledge of the overall resources of the application only if the startup process opened all necessary files and allocated all the necessary shared memory segments and any other shared resources. Individual processes communicate between each other using some form of inter-process communication (IPC) mechanism, e.g., shared-memory , semaphores, or message-queues. Each process has its own address space, its own scheduling priority, its own little universe . The problem with this idea is that creating a process in its own little universe is an expensive series of routines for the operating system to undertake. There's a whole new address space to create and manage; there's a whole new set of memory- related structures to create and manage. We then need to locate and execute the code that constitutes this unique, individual program. All the information relating to the shared objects set up by the startup process needs to be copied to each individual process when it was created. As you can see, there's lots of work to do in order to create new processes. Then we consider why an application creates multiple processes in the first place. An application is made up of multiple processes because an application has several individual tasks to accomplish in order to get the job done ; there's reading and writing to the database, synchronizing checkpoint files, updating the GUI, and a myriad of stuff to do in order to get the job done . At this point, we ask ourselves a question. Do all these component tasks interface with similar objects, e.g., open files, chunks of data stored in memory, and so on? The answer commonly is YES! Wouldn't it be helpful if we could create some form of pseudo-process whereby the operating system doesn't have as much work to do in order to carve out an entire new process? And whereby the operating system could create a distinct entity that performed an individual task but was in some way linked to all the other related tasks? An entity that shared the same address space as all other subtasks , allowing it access to all the same data structures as the main get-the-job-done task. An entity that could be scheduled independently of other tasks (we can refresh the GUI while a write to the database is happening), as long as it didn't need any other resources. An entity that allows an application to have parallel, independent tasks running concurrently. If we could create such an entity, surely the overall throughput of the application would be improved? The answer is that with careful programming such an entity does exist, and that entity is a thread . Multithreaded applications are more natural than distinct, separate processes that are individual, standalone, and need to use expensive means of communication in order to synchronize their activities. The application can be considered the overall task of getting the job done , with individual threads being considered as individual subtasks. Multithreaded applications gain concurrency among independent threads by subdividing the overall task into smaller manageable jobs that can be performed independently of each other. A single-threaded application must do one task and then wait for some external event to occur before proceeding with the same or the next task in a sequence. Multithreaded applications offer parallelism if we can segregate individual tasks to work on separate parts of the problem, and all while sharing the same underlying address space created by the initial process. Sharing an address space gives access to all the data structures created by the initial process without having to copy all the structural information as we have to between individual processes. If we are utilizing a 64-bit address space, it is highly unlikely that an individual thread will run out of space to create its own independent data structures, should it need them. It sounds like it was remarkable that we survived without threads. I wouldn't go so far as to say it's remarkable that we survived, but it can be remarkable the improvements in overall throughput when a single-threaded application is transformed into a multi-threaded application. This in itself is a non-trivial task. Large portions of the application will need to be rewritten and possibly redesigned in order to transform the program logic from a single thread of execution into distinct and separate branches of execution. Do we have distinct and separate tasks within the application that can be running concurrently with other independent tasks? Do these tasks ever update the same data items? A consequence of multiple threads sharing the same address space is that it makes synchronizing activities between individual threads a crucial activity. There is a possibility that individual threads are working on the same block of process private data making changes independent of each other. This is not possible where individual processes have their own independent private data segments. Multithreaded applications need to exhibit a property known as thread safe. This idea is where functions within an application can be run concurrently and any updates to shared data objects are synchronized . One common technique that threads use to synchronize their activities is a form of simple locking. When one thread is going to update a data item, it needs exclusive access to that data item. The locking strategy is known as locking a mutex . Mutex stands for MUTual EXclusion. A mutex is a simple binary lock. Being binary, the lock is either open or closed . If it is open, this means the data item can be locked and then updated by the thread. If another thread comes along to update the data item, it will find the mutex closed ( locked ). The thread will need to wait until the mutex is unlocked ( open ), whereby it knows it now has exclusive access to the data item. As you can see, even this simple explanation is getting quite involved. Rewriting a single-threaded application to be multi-threaded needs lots of experience and detailed knowledge of the pitfalls of multithreaded programming. If you are interested in taking this further, I strongly suggest that you get your hands on the excellent book Threadtime: The Multithreaded Programming Guide by Scott J. Norton and Mark D. Dipasquale. One useful thing about having a multithreaded kernel is that you don't need to use this feature if you don't want to. You can simply take your existing single-threaded applications and run them directly on a multi-threaded kernel. Each process will simply consist of a single thread. It might not be making the best use of the parallel features of the underlying architecture, but at least you don't need to hire a team of mutex-wielding programmers. The application may consist of a single process, which is the visible face of the application. As administrators, we can still manage the visible application. Internally, the single process will create a new thread for each individual task that it needs to perform. Because of the thread model used since HP-UX 11.0 (10.30 had this as well), each user-level thread corresponds to a kernel thread; because the kernel can see these individual threads, the kernel can schedule these individual tasks independently of each other (a thread visible to the kernel is known as a bound thread). This offers internal concurrency in the application with individual tasks doing their own thing as quickly as they can, being scheduled by the kernel as often as they want to run. Tasks that are interrelated need to synchronize themselves using some form of primitive inter-task locking strategy such as mutexes mentioned above. This is the job of application programmers, not administrators. The application programmer needs to understand the importance of the use of signals; we send signals to processes. Does that signal get sent to all threads? The answer is " it depends. " A common solution used by application programmers is to create a signal-handling thread. This thread receives the signal while all other threads mask signals. The signal-handling thread can then coordinate sending signals to individual threads (using system calls such as pthread_kill ). This is all internal to the process and of little direct concern to us. As far as administering this application, we manage the process; we can send a process signals, we can increase its priority, we can STOP it we can kill it. We are managing the whole set of tasks through the process, while internally each individual thread of execution is being scheduled and managed by the kernel. A process is a " container " for a whole set of instructions that carry out the overall task of the program. A thread is an independently scheduled subtask within the program. It is an independent flow of control within the process with its own register context, program counter, and thread-local data but sharing the host process's address space, making access to related data structures simpler. An analogy I often use is a beehive. From the outside, it is a single entity whose purpose is to produce honey. The beehive is the application , and, hence, the beehive can be thought of as the process ; it has a job to do. Each individual bee has a unique and distinct role that needs to be performed. Individual bees are individual threads within the process/beehive . Some bees coordinate their activities with miraculous precision but completely independently to the external world. The end product is produced at amazing efficiency, more effective than if we subdivided the task of producing honey between independent hives. Imagine the situation: Every now and then, the individual hives would meet up to exchange information and make sure the project was still on-track, and then they would go back to doing their own little part of the job of making honey. Honey-by-committee wouldn't work. The beehive is the process, and the bees are the threads : amazing internal efficiencies when programmed correctly, but retaining important external simplicity. We as information-gatherers ( honey-monsters ) will interface with the application/process ( beehive ) in order to extract information ( honey ) from the system. There's no point in going to individual bees and trying to extract honey from them; it's the end product that we are interested in, not how we got there. 11.1.3 Managing threads Currently, we have few tools to manage individual threads. The HP tool glance is about the only tool we can use to monitor online, individual thread activity. Maybe in the future we will see a companion command to ps known as ts to view the status of individual threads. At the moment, the tasks we are involved with concerning threads include ensuring that the kernel is able to support enough threads for all our applications and processes. We need to talk with our application suppliers to establish whether our applications are multithreaded, and if so, whether there are any guidelines as to how many threads an individual process will create. There are two main kernel parameters that we need to be concerned about: Some people ask the question, " Is there any link between the kernel parameters nproc and nkthread? " The simple answer is yes. At installation time, HP-UX will use a formula to calculate nkthread based on nproc . This is purely a generalized approximation of how many threads a process might need. Individual applications may or may not create more. The solution is to ask your application supplier. 11.1.4 Viewing threads The proc structure that we all know and love is what we interface with when managing processes. Individual threads have their own user structure and an associated kernel kthread structure. The proc structure has a pointer to the head and tail of the kernel threads associated with the process threads. HP-UX has only a few tools to view individual threads. For program debuggers , there is a free tool called wdb that allows application developers to view threads within a program. Other application development tools may provide their own interface to view internal application threads. Beyond that, we would have to use either glance (the G command allows you to view threads, and S lets you select individual threads) or the q4 kernel debugger to view threads associated with a process. I will use some screenshots from the graphical version of glance : gpm . As we will see, the screenshots contain useful information in relation to these demonstrations . For example, think of the NFS daemon that responds to NFS requests over TCP ports. There is only one such daemon that will fork a thread for each new request from an NFS Client. From this ps listing, we can see that there is an nfsktcpd :
root@hpeos003[] ps -ef grep nfs root 4456 0 0 12:18:08 ? 0:00 nfsktcpd root 1301 0 0 09:45:50 ? 0:00 nfskd root 2201 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2220 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2200 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2209 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2208 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2196 1 0 10:04:25 ? 0:00 /usr/sbin/nfsd 16 root 2198 1 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2199 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2205 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2218 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2207 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2216 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2213 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2219 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2215 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2222 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root 2223 2198 0 10:04:26 ? 0:00 /usr/sbin/nfsd 16 root@hpeos003[]
The nfsktcpd with pid =4456 is the TCP-NFS daemon. Can we view individual threads with ps ? No, but do we really care? As long as this application gets the job done as efficiently as possible, do we really care how it does it? We can look at the threads for this process from within gpm ; from the Process List report, we highlight the process, and then under Reports , we select Process Thread List . You can see the output in Figure 11-1: Figure 11-1. Process Thread List using gpm. 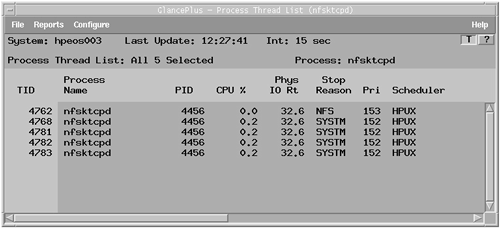
You can see that this process has five threads currently scheduled. Each thread will be dealing with its own inbound TCP requests and being scheduled independently by the kernel depending on whether the thread is being blocked on IO or whether it can run. As such, this process may be quite a busy process as far as utilities such as top and glance are concerned, with each thread accumulating CPU time on behalf of the process. Currently, only five threads are enough to deal with all current NFS-TCP requests. If we want to manage this application, we will manage the process not the individual threads. Let's move on and look at the life cycle of a process. This will also define the states a process can be in, everything from starting (TIDL) to a zombie process (TSZOMB). |