11.2 Download a File and Process It Using a Stream
Problem
You need to retrieve a file from a Web site, but you don't want to save it directly to the hard drive. Instead, you want to process the data in your application.
Solution
Use the WebRequest class to create your request, the WebResponse class to retrieve the response from the Web server, and some form of reader (typically a StreamReader for HTML or text data or a BinaryReader for a binary file) to parse the response data.
Discussion
Downloading a file from the Web takes the following four basic steps:
-
Use the static Create method of the System.Net.WebRequest class to specify the page you want. This method returns a WebRequest - derived object, depending on the type of Uniform Resource Identifier (URI) you use. For example, if you use an HTTP URI (with the scheme http://), it will create an HttpWebRequest instance. If you use a file system URI (with the scheme file://), it will create a FileWebRequest instance. You can set the timeout through the WebRequest.Timeout property.
-
Use the GetResponse method of the WebRequest object to return a WebResponse object for the page. If the request times out, a WebException will be thrown.
-
Create a StreamReader or a BinaryReader for the WebResponse stream.
-
Perform any steps you need to with the stream, such as writing it to a file, displaying it in your application, and so on.
The following code retrieves and displays a graphic and the HTML content of a Web page. It's shown in Figure 11.1.
using System; using System.Net; using System.IO; using System.Drawing; using System.Windows.Forms; public class DownloadForm : System.Windows.Forms.Form { private System.Windows.Forms.PictureBox picBox; private System.Windows.Forms.TextBox textBox; // (Designer code omitted.) private void DownloadForm_Load(object sender, System.EventArgs e) { string picUri = "http://www.microsoft.com/mspress/images/banner.gif"; string htmlUri = "http://www.microsoft.com/default.asp"; // Create the requests. WebRequest requestPic = WebRequest.Create(picUri); WebRequest requestHtml = WebRequest.Create(htmlUri); // Get the responses. // This takes the most significant amount of time, particularly // if the file is large, because the whole response is retrieved. WebResponse responsePic = requestPic.GetResponse(); WebResponse responseHtml = requestHtml.GetResponse(); // Read the response streams. Image downloadedImage = Image.FromStream(responsePic.GetResponseStream()); StreamReader r = new StreamReader(responseHtml.GetResponseStream()); string htmlContent = r.ReadToEnd(); r.Close(); // Display the image. picBox.Image = downloadedImage; // Show the text content. textBox.Text = htmlContent; } } 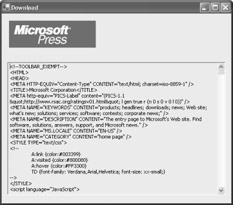
Figure 11.1: Downloading content from the Web.
To deal efficiently with large files that need to be downloaded from the Web, you might want to use asynchronous techniques, as described in Chapter 4. You can also use the WebRequest.BeginGetResponse , which doesn't block your code and calls a callback procedure when the response has been retrieved.
- The Four Keys to Lean Six Sigma
- Key #1: Delight Your Customers with Speed and Quality
- Key #3: Work Together for Maximum Gain
- Making Improvements That Last: An Illustrated Guide to DMAIC and the Lean Six Sigma Toolkit
- The Experience of Making Improvements: What Its Like to Work on Lean Six Sigma Projects