Detailed Test Planning
Overview
"You've got to be careful if you don't know where you're going 'cause you might not get there!"
— Yogi Berra
To be most effective, test planning must start at the beginning and proceed in parallel with software development. General project information is used to develop the master test plan, while more specific software information is used to develop the detailed test plans, as illustrated in Figure 4-1. This approach will target testing to the most effective areas, while supporting and enhancing your development process. When fully implemented, test planning will provide a mechanism to identify improvements in all aspects of the system and development process.
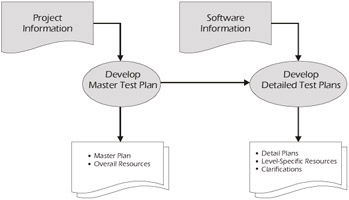
Figure 4-1: Planning Phase Process
A level of test is defined by a particular environment, which is a collection of people, hardware, software, interfaces, data, and even the viewpoints of the testers. Table 4-1 lists some sample environmental variables. This list may vary significantly between projects and companies. Some companies, for example, may have only one level of test, while others may have ten or more.
|
Attribute |
Level |
|||
|---|---|---|---|---|
|
Unit |
Integration |
System |
Acceptance |
|
|
People |
Developers |
Developers & Testers |
Testers |
Testers & Users |
|
Hardware O/S |
Programmers' Workbench |
Programmers' Workbench |
System Test Machine or Region |
Mirror of Production |
|
Cohabiting Software |
None |
None |
None/Actual |
Actual |
|
Interfaces |
None |
Internal |
Simulated & Real |
Simulated & Real |
|
Source of Test Data |
Manually Created |
Manually Created |
Production & Manually Created |
Production |
|
Volume of Test Data |
Small |
Small |
Large |
Large |
|
Strategy |
Unit |
Groups of Units/Builds |
Entire System |
Simulated Production |
What determines the number of levels required? Typically this decision is made based on complexity of the system, number of unique users, politics, budget, staffing, organizational structure and so forth. It's very important that the test manager help define what the levels are and ensure that there aren't too many or too few levels. We can hardly afford to have overlapping levels and, conversely, we don't want to take the risk of having big gaps between levels.
| Key Point |
Cohabiting software is other applications that reside on the same platform. |
Creating a test plan for a specific level requires a clear understanding of the unique considerations associated with that level. Product risk issues, resource constraints, staffing and training requirements, schedules, testing strategy, and other factors must all be considered. Level-specific or detailed test plans are created using the same template that we used for the Master Test Plan (refer to Chapter 3 - Master Test Planning), but the amount of detail is greater for a level-specific plan.
Figure 4-2 shows the relationship of the Master Test Plan (MTP) to the Project Plan and the Detailed Test Plans.
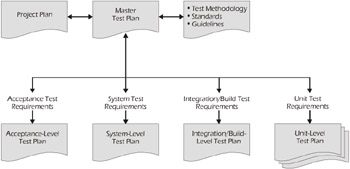
Figure 4-2: Master versus Detailed Test Plans
There are many names for the levels employed by different groups and companies. Here are only a few that we've encountered recently: unit, component, code, developer, build, string, thread, integration, system, system integration, acceptance, user acceptance, customer acceptance, interoperability, alpha, beta; Verification, Validation, and Testing (VV&T), and others. You see, there are many different names, and you may very well have some that we didn't list here. In the long run, what you name your levels is relatively unimportant. What's important is to define the scope of the level and what that level is supposed to accomplish; then, create a plan to ensure that it happens.
| Key Point |
It's important to define the scope of the level and what that level is supposed to accomplish; then, create a plan to ensure that it happens. |
Throughout this book, we use the level names defined by the IEEE: Acceptance, System, Integration and Unit. While these names are no better or worse than any others, they are convenient, as they provide a basis for discussion. This chapter will focus on the highest levels first and then progressively move to the lower levels of test. This is done because the level-specific plans should usually be written in reverse order of execution. That is to say, even though the acceptance test is normally the last one to be executed, it should be the first test to be planned. Why? Simply because the acceptance test plan is built on the artifacts that are available first - the requirements - and this group of tests is used to model what the system will look like when it's complete. The "V" model of testing in Figure 4-3 shows that the system test should be planned next based on the high-level design (and requirements); integration testing should be planned using the detailed design (and the high-level design and requirements); and unit testing should be planned based on the coding (and the detailed design, high-level design, and requirements).
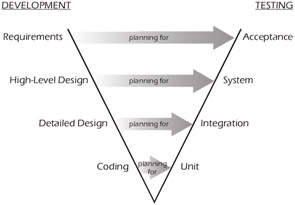
Figure 4-3: The "V" Model of Software Testing
| Key Point |
The level-specific plans should usually be written in reverse order of execution. |
Without a doubt, some readers may be more concerned with one level of test than the others. However, we encourage you to read about all of the levels of test in this chapter even if you're not directly involved, because it's important to understand all of the types of testing that may be occurring in your company. Also, as a matter of style in writing this book, we sometimes discuss issues in one level of test that are applicable at other levels and may not necessarily be repeated in the other sections of this chapter.
Acceptance Testing
Acceptance testing is a level of test that is based largely on users' requirements and demonstrates that those requirements have been satisfied. As illustrated in Figure 4-4, acceptance testing is the first level to be planned because it's built based on the system requirements. Since this group of tests is used to model what the system will look like when it's complete, acceptance testing is most effective when performed by the users or their representatives in the most realistic environment possible.
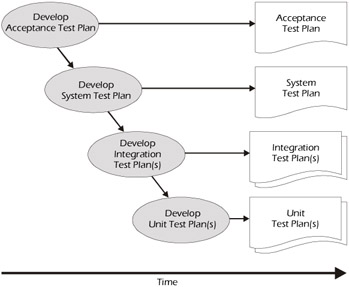
Figure 4-4: Sequence of Planning Activities
Audience Analysis
Obviously the users or customers are part of the audience for the acceptance test plan. Whoever is conducting the system testing is also part of the audience, since their exit criteria must consider the entrance criteria into acceptance testing. The developers will also be anxious to see the acceptance test plan, since it will specify exactly what constitutes success for their development effort. Therefore, the audience for the acceptance test plan may include technical people such as developers, as well as business users who may or may not be very technically adept. In order to accommodate such a diverse audience, the language of this plan should be non-technical.
Activity Timing
The acceptance test planning process should begin as soon as the high-level requirements are known. It's essential that this occur early in the lifecycle because one of the key purposes of the acceptance test plan is to develop the criteria for what constitutes a completed project. In other words, the exit criteria from the acceptance testing provide a basis for acceptance of the product. The acceptance test plan, and later the acceptance test cases, should fairly accurately describe what the finished product will look like. In some of the most progressive companies that we've visited, the acceptance test plan and test cases are actually delivered with the requirements document. In the case of outsourced development, the acceptance test plan and test cases may even be made part of the contract.
| Note |
When should the test plan be written? |
| Note |
Who should write the test plan? |
The acceptance test plan would ideally be written by the end-user. This is frequently not possible for a variety of reasons. If, for example, your product is commercial shrink-wrap software or a Web application, you may have thousands or even millions of very different and unknown users. In that situation, it's important to find a group of people that represent the final end-users. In many organizations, the acceptance testers are called business associates or some similar name. These people are testers that typically come from the user community. Other organizations employ the users from a particular site or company as testers. Whoever is chosen, they need to have the most complete understanding of the business application as possible.
Figure 4-5 illustrates how the realism of the test environment increases at higher levels of test.
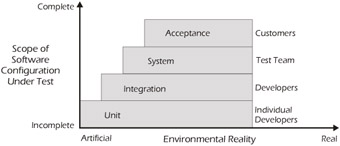
Figure 4-5: Typical Test Levels
As we pointed out earlier, the acceptance test is not intended to be comprehensive and, therefore, doesn't last as long as the system test. Sometimes, the acceptance test on extremely large systems may take only a few days or weeks. If your acceptance testing today is going on for weeks and weeks, you may be doing "good" work, but you also may be doing more than what we call acceptance testing. In fact, you may be doing some of what we call system testing. That's fine, though, because you've just defined your levels differently than we have. The point is that a comprehensive test is not necessary in order to demonstrate that the requirements work.
| Note |
How long should acceptance testing last and how comprehensive should it be? |
Of course, anything is possible. Rick used to have a colleague (okay, not a colleague, but his boss) who felt that most acceptance tests were a waste of time (probably because they were often ad hoc) and should be done away with. We believe, though, that the acceptance test is a very valuable way to prove the validity of the requirements and to support buy-in from the users.
| Note |
Can acceptance testing be combined with system testing? |
Still, with tight time crunches and shortage of personnel, does it make sense to combine system and acceptance testing? Remember that the levels are what define the environment, and each environment can be associated with a level of test. The environment includes the hardware, software, documentation, data, and people. One of the most common differences between the system test environment and the acceptance test environment is who is doing the testing. Therefore, there are two situations where it might make sense to combine the two levels if necessitated by resource or time constraints:
- When the users have a very active role in systems test. It's always desirable to have the users involved in the system test (and throughout the lifecycle). If they're an integral part of the systems test effort and the rest of the test environment is as realistic as possible, then it might make sense to combine acceptance testing with system testing.
- When the users have no involvement in testing whatsoever. If the most frequent difference in the system and acceptance test environments is who is conducting the test and if the test group is conducting both tests in similar environments, then why not combine the two? We've seen situations where organizations had historically conducted both system and acceptance testing and continued to do so even though both tests were virtually identical. In one case, the acceptance test set was a subset of the system test set and was rerun in exactly the same environment by the same people.
Should the execution of one level begin before the execution of the previous level is complete? In order to cut the elapsed time (schedule) from inception to delivery, many organizations overlap various testing levels. The penalty for overlapping the levels, however, is extra effort. Even though the lifecycle is shortened, it will typically take more effort because the higher level of test may find bugs that may have already been found (and sometimes fixed) by the lower level of test. Sometimes, both levels of test may be finding some of the same bugs at the same time and reporting them in slightly different words. This can add overhead to defect and configuration management.
| Note |
Can acceptance testing begin before the system testing is done? |
Another issue may be one of first impressions. The first time the users see a nearly complete product is often during the acceptance test. If users receive a product that has not yet completed system testing, it will potentially contain more (possibly many more) bugs, which may cause them to get the feeling that the system is unsound. Hopefully, this attitude doesn't exist in your company, because, ideally, we would like to have the users involved throughout the lifecycle.
In some instances, system testing can be combined with integration testing. Our clients who successfully use this strategy have excellent configuration management, a relatively high level of test automation, and a good working relationship between the developers and testers. The basic strategy is that the integration tests are developed around each build - usually by the test group. That is, each progressively larger build is tested as part of the integration effort. The final build contains the entire system and becomes, in fact, the system test. This technique is not for everyone and depends on a lot of the factors that we explained above. One of the downsides of combining system and integration testing is that it removes part of the developer's responsibility for developing and delivering a finished product and passes that responsibility to the test team.
| Note |
Can the system testing be combined with integration testing? |
Sources of Information
The key documents needed to write the acceptance test plan include the project plan, the master test plan and the requirements documentation. Other documents, such as user manuals, are also useful if they're available. The project plan lays out the entire strategy and schedule for the development project, and the acceptance test plan must relate to that document. However, the master test plan is typically based upon the project plan and gets into more detail on specifically how the system will be tested. Therefore, level-specific test planners can typically rely on the master test plan more than the project plan for general guidance. For example, an overall testing schedule is published in the master test plan. Another feature of the master test plan is the characterization of broad goals for each level including the entrance and exit criteria. The acceptance test plan (and all subsequent level-specific test plans) should follow this grand scheme. If significant changes are identified in the course of the detailed test planning, they must be rolled up into the master test plan.
| Key Point |
If changes are identified in the course of the detailed test planning, they must be rolled up into the master test plan. |
Ideally, the acceptance test cases should be based upon the requirement specification. Unfortunately, many projects do not have a requirements document per se. In those instances, other methods or documents must be used to identify the key features and components to test. This is the subject of Chapter 5 - Analysis and Design. For acceptance testing in particular, user documentation can be very useful when planning a new release of an existing system. At all levels of test, enhancement requests and defect reports should be treated as requirements documents.
User Responsibilities
The users or their representatives play an important part in the acceptance testing process. Some of their responsibilities may include:
- Defining the requirements
- Identifying the business risks
- Creating, updating, and/or reviewing the Acceptance Test Plan
- Defining realistic scenario-based tests
- Providing realistic test data
- Executing the tests
- Reviewing the documentation
- Reviewing the test output
- Providing acceptance criteria
Usability Testing
| Note |
What if there are many users and they're not always right? |
In many organizations, customers (users) conduct the acceptance testing on a nearly complete product in a near-production environment. Many organizations are proud of their stance that "the user is always right," but one of the problems associated with this is defining who is the user. Companies that develop and sell commercial software spend lots of thought and money on just this issue. All users are just not the same and have different needs. Some users want to be able to have a powerful system devoid of annoying prompts such as "Do you really want to delete this file?" Other users are a little more timid and after deleting their newly written doctoral thesis would welcome the child-like but annoying question that required a second thought. Sometimes user 'A' wants a feature that is a direct detriment to what user 'B' wants. Who is right and who decides? Maybe you should pay for two systems to satisfy both users? But then what happens if you have a hundred users instead of just two?
Another problem is that the users often don't know what they want. That's not pointing the finger at the users. It's simply a challenging task because the software developers also often don't have a clear view of what the system requirements are. Anyone who has ever participated in the creation of a requirements document (which, by the way, is often done by the users) knows just how difficult that task is.
The solution to these problems lies within the entire software engineering process (including requirements formulation and acceptance testing) and the communications between the users, developers, and testers. Fostering clear and concise communications between developers, tester, and users near the beginning of the software development lifecycle can help reduce the problem of "who's right."
Usability testing is one of the hardest kinds of testing to accomplish. Part of the difficulty is that the usability requirements are hard to describe and are often done poorly - and poor requirements can lead to poor testing. For example, a common usability requirement is that the system must be "user-friendly," but what does that mean? An accomplished user might consider a powerful system with shortcuts to other features to be user-friendly, while other users may require extensive menus to drag them from one part of the system to another. This entire problem is compounded because there may be many users with different needs and/or the users may be unknown.
| Key Point |
Usability requirements are hard to describe and are often done poorly - and poor requirements can lead to poor testing. |
Another problem with usability testing is that it can be difficult to conduct until very late in the lifecycle (i.e., acceptance test execution). Even if problems are discovered at this late juncture, it may be too late or too expensive to correct them (at least in this release). One approach used by some companies to overcome this problem is to use prototypes to "mock up" the system and let the users see what the finished product will look like earlier in the lifecycle. Sometimes, these prototypes may merely be paper mock-ups of reports or screens. Other companies have more sophisticated tools at their disposal such as usability laboratories, where a cut-down version of the actual system is created to allow the users to interact with it early to get a feel for it.
Usability Labs
A usability lab (Ulab) is a special environment created to evaluate the usability of a prototype product (application). Prospective users are asked to "use" the prototype being evaluated with only the assistance of the normal product documentation. The goal is to discover usability problems before the actual system is built, effectively saving the cost of building the "wrong" system.
| Key Point |
The goal of a usability lab is to discover usability problems before the actual system is built ffectively, this saves the cost of building the "wrong" system. |
The key actors in any type of usability testing are the user, the observer, and a recording mechanism or method. In the usability lab in Figure 4-6, the user sits in an observation room where he or she uses the prototype product. Video cameras record the user activities, facial expressions, body positions, and other factors that may be indications of the usability of the software under test. On the other side of a one-way mirror, the observers are watching the user in his or her attempts to use the system. Occasionally, a user may be asked why he or she did something or be told how to resolve a difficult situation, but overall, communications between the observers and the user are kept to a minimum. Observers may include usability laboratory staff members, developers, and/or testers. The video cameras serve as the principal recording mechanism.
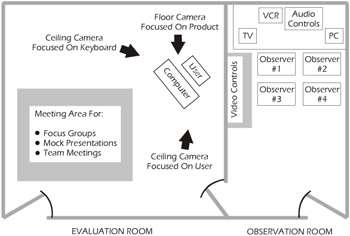
Figure 4-6: Usability Lab Design by Dr. Michael J. Prasse, Director of OCLC Usability Lab
| Key Point |
One danger of using a prototype is that the users may want to immediately install and use it. Unfortunately, a prototype is not a complete system and it's not ready to be used in a production environment. |
The Ulab staff members record notes as the user works, and these notes will later be reviewed with the videotape. Additionally, the users may be interviewed and/or fill out a questionnaire designed to learn their perception of the usability of the product. The results of the Ulab session (i.e., notes, video, interviews, and questionnaires) are used to identify and correct usability deficiencies.
Both usability testing and Ulab sessions are designed to discover usability problems that may require correction. The major difference is in when they are conducted. Because most usability testing is conducted at the end of the development lifecycle (i.e., system or acceptance testing), usability problems that are discovered are difficult and expensive to correct. Since the Ulab is conducted before the final product is built, usability problems can be addressed early when it's relatively inexpensive to rectify them.
Case Study 4-1 describes an incident that often occurs in usability labs.
Case Study 4-1: Are the users really "stupid" or is the user interface difficult to understand?
Round #1: In the Usability Lab
Perhaps one of the most interesting events to watch is the reaction of the developers to a user's initial attempt to use a prototype in the usability lab. When a user unsuccessfully attempts to use a function, the developer on the other side of the one-way mirror can often be seen fuming at the "stupid" user for not understanding how to handle the problem. When the function doesn't work the way the user thinks it should work, he or she almost always tries the same thing again or pounds the Enter key several times. About that time, the developer starts to see the discrepancies between what he or she has created and what the user is trying to do. The key here, though, is that this usability discrepancy was discovered in the prototype and not in the final product. This means that the development team will have more time and therefore a better shot at fixing the problem.
Alpha and Beta Testing
At best, the terms "alpha testing" and "beta testing" are highly ambiguous or at least mean very different things to different people. We'll try to offer the most common definitions of both. Alpha testing is an acceptance test that occurs at the development site as opposed to a customer site. Hopefully, alpha testing still involves the users and is performed in a realistic environment.
| Key Point |
Some organizations merely refer to alpha testing as testing that is conducted on an early, unstable version of the software, while beta testing is conducted on a later, more stable version. |
Beta testing is an acceptance test conducted at a customer site. Since beta testing is still a test, it should include test cases, expected results, etc. Many companies give the software to their customers to let them "play with it" and call this the beta test. While allowing your customers to play with your software may be a valuable thing to do, it's probably not adequate for a beta test. On the other hand, if a more formal acceptance test has been conducted and you just want some additional assurance that the customers will be happy, it's fine to let the users have a go.
Frequently, though, the users will not conduct a very broad test if they are allowed to proceed in a purely ad hoc fashion without the benefit of a test strategy and test cases.
Requirements Traceability
Requirements traceability is an important concept in testing, especially at the acceptance level. In a nutshell, requirements traceability is the process of ensuring that one or more test cases address each requirement. These are normally presented in a matrix as illustrated in Table 4-2 or done in a spreadsheet, database, or using a commercially available tool.
|
Requirement |
TC-1 |
TC-2 |
TC-3 |
TC-4 |
|---|---|---|---|---|
|
RQ-1 |
ü |
ü |
ü |
ü |
|
RQ-2 |
ü |
ü |
||
|
RQ-3 |
ü |
ü |
||
|
RQ-4 |
ü |
|||
|
RQ-5 |
ü |
|||
|
RQ-6 |
ü |
ü |
||
|
RQ-7 |
ü |
ü |
ü |
Requirements traceability is a high-level measure of coverage, which in turn is one way that test managers can measure the effectiveness of their testing. The requirements traceability matrix can and normally should be used in concert with the software risk analysis described in Chapter 2 - Risk Analysis.
The entire thrust of acceptance testing is to ensure that every requirement is addressed. It may or may not be clear to you that it's possible to test every requirement and still not have tested the "entire" system. Remember, the requirements traceability matrix doesn't show that every requirement is tested completely, only that each requirement has been addressed. Additionally, design characteristics are not specifically addressed during acceptance testing and, therefore, other issues may be left untested. In other words, acceptance testing is not a comprehensive test, nor was it intended to be. Rather, in the perfect world, the acceptance test would demonstrate to (or, even better, by) the user or their representative that the requirements have been met.
Configuration Management
| Key Point |
During acceptance testing, configuration management of the software under test (SUT) should be as formal as it is in the production environment. |
| Key Point |
Configuration management is covered in more detail later in this chapter under the topic System Testing. |
During acceptance testing, configuration management of the software under test (SUT) should be as formal as it is in the production environment. Because the execution of the acceptance test plan (and test cases) is conducted shortly before the scheduled implementation date, finding major defects is a problem because there is little time to fix and test them. Ideally, we want the acceptance test to be largely a demo and hope to find all of the major problems in earlier levels of test. Unfortunately, if the users were not involved throughout the lifecycle in requirements formulation, walkthroughs, and earlier levels of test, prototypes, and so forth, acceptance testing may be their first encounter with the "system" or at least their first time since the requirements were created. Users are almost certain to find things that are incorrect or don't meet their vision. In fact, users may not have a clear vision of what they expected, only that the system doesn't meet their expectations. Hence, the users typically request major requirements changes. The worst thing that can (and frequently does) happen is to discover a major requirements flaw just before shipping and try to make the change on the fly without providing adequate time for analysis, design, implementation, and regression testing. There is a good chance that the change was rushed and may go out without being tested or, at least, tested inadequately. Almost all companies ship their products with known bugs (and unknown bugs) but there's something about "that last bug" that makes many developers feel that they must correct it before shipping. So, developers fix that last bug and if there is inadequate time to test, then untested software is shipped.
Implementing major requirements changes at the end of the lifecycle can turn a project into chaos. That's why it's so important for the Change Control Board (CCB), or its equivalent, to review each major change and determine the impact on the system and the project. Each change must be prioritized and in many cases, the correct choice is to delay certain fixes to a future release. If the change must be done in this release, then the planning risks discussed in Chapter 2 must be revisited. That is, we may have to slip the schedule, not ship a particular feature, add resources, or reduce testing of some relatively low-risk features.
| Key Point |
It's important for the Change Control Board (CCB), or its equivalent, to review each major change and determine the impact on the system and the project. |
Exit Criteria
The categories of metrics for release criteria are pretty much the same for each level of test, but the actual values will be different. The exit criteria for acceptance testing are especially key, since they're also the exit (or release) criteria for the entire system. These exit criteria were originally laid out in general terms in the master test plan and republished in greater detail in the level-specific plans. Case Study 4-2 provides an example of one company's exit criteria for their acceptance testing.
Case Study 4-2: Some exit criteria may be standard across the organization, while others may be unique to each project.
Example Exit Criteria for an Acceptance Test
- There can be no Medium or High severity bugs.
- There can be no more than 2 bugs in any one feature or 50 bugs total.
- At least one test case must pass for every requirement.
- Test cases 23, 25, and 38-52 must all pass.
- 8 out of 10 experienced bank clerks must be able to process a loan document in 1 hour or less using only the on-line help system.
- The system must be able to process 1,000 loan applications/hour.
- The system must be able to provide an average response time of under 1 second per screen shift with up to 100 users on the system.
- The users must sign off on the results.
Release Strategies
When acceptance testing has successfully concluded, the system is typically rolled out to the users. One strategy is to ship and install the entire system at every client site simultaneously. This introduces a significant risk if major problems are encountered in the installation or functionality of the system. In order to reduce this risk, organizations commonly use other rollout strategies such as: pilots, gradual implementation, phased implementation, and parallel implementation.
Pilots
| Key Point |
The difference between a beta site and a pilot is that the users at the pilot site are actually using the product to do real work, while the beta testers are executing tests. |
Pilots are often confused with beta tests. You will remember that a beta test is an acceptance test at a client site where test cases are executed in a very realistic (test) environment. A pilot is a production system executed at a single or limited number of sites, as shown in Figure 4-7. The difference between a beta site and a pilot is that the users at the pilot site are actually using the product to do real work. Failures can immediately affect their business.
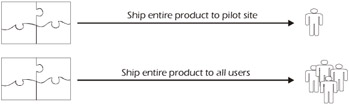
Figure 4-7: Release Using Pilot Site
Gradual Implementation
Figure 4-8 shows that gradual implementation or shipping the entire product to a few customers at a time is another possible option. This, of course, allows developers to get feedback from the earlier recipients of the product, which may allow them to make changes before the product is generally available. The downside of this technique is that it extends the time until all customers have the product in hand (i.e., general availability). It also means that the developers and testers must maintain more than one version simultaneously.
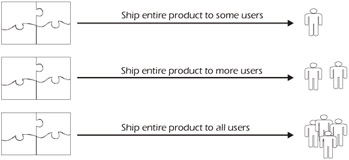
Figure 4-8: Complete Shipment to Some Users
Phased Implementation
Phased implementation is when the product is rolled out to all users incrementally. That is, each successive release contains additional functionality. As a system is being built, functionality is installed for immediate use at the client sites, as it becomes available, as illustrated in Figure 4-9. The beauty of this is that the customers get involved early, get something that they can (hopefully) use, and can provide useful feedback to the developers and testers. The downside is that the overall integration of the system may be more complicated and there will be significantly more regression testing conducted over the entire lifecycle of the product.
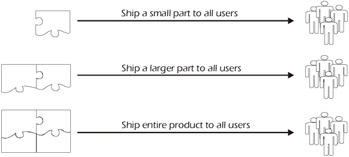
Figure 4-9: Incremental Shipments to All Users
Parallel Implementation
Parallel implementation is another technique used to reduce the risk of implementation. The existing application is run side by side (in production) with the new application. If there are any differences, the existing system is considered correct until proven otherwise. Parallel implementation may require extra hardware, software, and personnel resources.
All of the above implementation techniques (pilots, gradual implementation, phased implementation, and parallel implementation) are done in order to reduce the risk of shipping an entire system to all of your clients and having it fail spectacularly. There is one risk, though, that each of these techniques introduces - the elapsed time for all of the clients to receive the entire system is extended. Remember how sensitive management normally is about getting the product out the door? It seems that in some companies, once the pilot begins, the entire company lets go with a collective sigh of relief.
Test Environment
The environment for acceptance testing should be as realistic as possible. Any differences between the acceptance test environment and the real world are actually risks - things that have not been tested. For each level of testing (especially for acceptance and system), the testers should compare their environment to the real world and look for differences. If possible, the differences should be eliminated or reduced. If this is not possible, then the testers will have to look for other ways to deal with the risk of an unrealistic test environment. Case Study 4-3 compares one of our clients' test environment to their production environment.
Case Study 4-3: Example of a Test Environment
An Example Test Environment
Here is an example test environment from one of our clients. (Remember that the environment includes who is doing the testing, hardware, software, interfaces, data, cohabiting systems, etc.)
People:
Testers (formerly users)
Hardware:
"Exact" replica of the most common configuration
Software Under Test:
Same
Interfaces
Some missing, some simulated
Data
Subset of real production data, updated weekly
Cohabiting Software:
Unknown
This is not a bad test environment, but you can see that differences do exist between the test environment and the real word. Let's analyze each part of the environment to see if it introduces a significant risk. If it does, is there is a way to mitigate the risk?
People: This project had a good strategy of using former users as testers, which helped reduce the risk. As former users, the testers, for the most part, have some business knowledge, but as time goes by, the business changes and memories fade (sounds like a song) and they become testers rather than users. However, these testers will always retain their business viewpoint and empathy for the users. In the example above, the system being developed had many different users with different needs, some of which were not represented by the former user testers. If the team felt that a risk existed (and they did) they might have chosen to bring some users on board as temporary testers or possibly conduct a beta test at one or more customer sites (this client did both).
Hardware: This client/server system had consistent hardware and operating systems for the servers, but the clients were not as closely controlled. The test team addressed this issue by inventorying the hardware used by the customers and creating profiles of the most common client hardware configurations, operating systems, printers, etc.
Software Under Test: Same - no issues.
Interfaces: This was a problem. It was not possible to interface with the live systems, so simulators had to be created to replicate the interaction of the system under test and the other systems and databases it interacted with. The testing is only as good as the simulators were and, in this case, problems were experienced upon fielding the system. Fortunately, this project used a pilot site and the problems were limited to one (volunteer) customer.
Data: Copies of real data were used as much as possible. Some unique data had to be created by hand. Due to the constraints of the test environment, the volume of data used for testing was significantly less than production. This was offset somewhat by using some dynamic load testing tools and techniques. The data was not particularly "fragile," and the fact that some of the data was quite old did not adversely impact the test.
Cohabiting systems: This was another problem. Customers were not supposed to load their own software on the client machines, but of course they did. The testers did not test the impact of any other software, because the users were not supposed to load it. Actually, it turned out that another piece of software developed by the company caused the software under test to crash frequently if both were loaded and used at the same time.
System Testing
The system test is what most people think about when they think of testing. It is what Rick often calls "The Big Kahuna." The system test is where most of the testing resources normally go because the testing may go on for an extended period of time and is intended to be as comprehensive as the resources allow and the risk dictates. In addition to functional testing, it is typically during system test that load, performance, reliability, and other tests are performed if there is not a special effort or team for those activities. The system test set or a portion of it will normally comprise the bulk of the regression test suite for future releases of the product.
Audience Analysis
| Note |
Who should write the system test plan? |
If there is an independent test team, their focus is normally on system testing. The manager of this team or a senior test analyst would normally be the primary author of the system test plan. He or she would be responsible for coordinating with the developers and users to get their input on the areas that affect them. If there is no independent test team, the system test plan may be written by the development team or in some cases by the users.
The system test plan can normally be started as soon as the first draft of the requirements is fairly complete. The software design documentation will also have an impact on the system test plan, so the "completion" of the plan may be delayed until it is done.
| Note |
When should the system test plan be written? |
Sources of Information
As in the case of the acceptance test plan, the system test plan must be in agreement with the master test plan and seek to amplify those parts of the MTP that address system testing. The system test plan is built based on the requirements specifications, design documentation, and user documentation, if they exist. Other documents such as functional specifications, training materials, and so on are also useful. Chapter 5 - Analysis and Design explains the valuable of creating inventories of functions, states, interfaces, etc. to be used as a basis for the test design.
| Note |
A traceability matrix for system testing may include some or all of the following domains:
|
The requirements traceability matrix that is used for acceptance testing is a good starting point for the system testing traceability matrix, but is generally not comprehensive enough to support the system test design. Generally, the system test group will try to build a matrix that not only covers the requirements, but also includes an inventory of features, design characteristics, states, etc. Other domains that are addressed in systems testing might include capacity, concurrence, configuration, conversion, hardware, installation, interoperability, interfaces, localization, performance, recovery, reliability, resource usage, scalability, sensitivity, software configuration, and usability. However, not all of these domains are applicable for every application.
Software Configuration Management
Software configuration management is critical to the testing effort. It is so important that if the software configuration management is done poorly, the testing effort and indeed the entire project may fail. Normally, we think of software configuration management as a process that has two distinct but related functions, as illustrated in Figure 4-10.
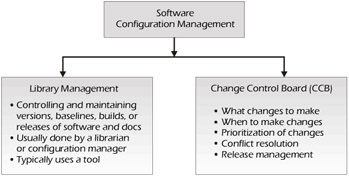
Figure 4-10: Functions of Configuration Management
The first of these is an administrative function that is itself sometimes called configuration management, although library management is probably a more accurate term. This is the function of creating the builds, managing changes to the software, and ensuring that the correct versions of the software and documentation are maintained and shipped. It's frequently done with the aid of commercially available or homegrown tools. The configuration manager may be organizationally independent, or the function may fall under the development organization, the QA team, or the testing team. Configuration management is a difficult and thankless job where you're hardly ever noticed until something goes wrong - kind of like testing.
| Key Point |
Change Control Board (CCB) members may include:
|
The other part of software configuration management is more of a management function. This is usually done with a group called the Change Control Board (CCB), Change Management Board (CMB), bug committee, the every-other-Tuesday meeting, or whatever you call it - really, the name is not that important. The purpose of the CCB is to determine how incidents, defects, and enhancements should be handled, as illustrated in Figure 4-11. Basically, the CCB determines what changes should be made and in what order (i.e., the priority).
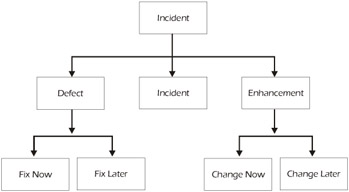
Figure 4-11: Defect Analysis Decision Tree
| Key Point |
After digesting dozens of books, we found that about half refer to the CCB as the Configuration Control Board, while the other half referred to CCB as the Change Control Board. We like Change Control Board. |
Ideally, the CCB would comprise a group of users, developers, testers, and anyone else with a vested interest in the final product. Normally, priorities are based upon the severity of the bug (users are useful), the effort to fix the bug (developers are useful), the impact on the schedule (managers are useful), and the effort to re-test (testers are useful).
| Key Point |
An incident is something that doesn't work as desired or expected. It may be caused by a defect (software or testing), it may be an enhancement, or it may be a one-time anomaly (i.e., incident). |
Most companies have some type of formal or informal CCB that looks at production bugs and enhancement requests. Many of these same companies do not have any special process to handle and prioritize bugs and enhancements that occur during the course of the software development lifecycle. This is not necessarily a big problem at the lower levels of test (e.g., unit), where the required degree of formality of configuration management is less, but becomes critical at system and acceptance test times. We're discussing configuration management in greater detail in the section on system testing because it seems that is where some of the biggest configuration management problems occur. Case Study 4-4 describes a configuration management problem that occurs all too often.
Case Study 4-4: If a developer fixes a bug really fast and creates a new build, did the bug really exist?
The Bug That "Never Existed"
See if this scenario sounds familiar… The systems test is being conducted and Heather, the tester, discovers a defect. She immediately documents the bug and sends it back to the developer for resolution. Bob, the developer, can't stand the thought that someone found a bug in his work, so he fixes it immediately and updates the version of the software under test. Out of sight, out of mind… Many developers feel that if they fix the bug fast enough, it's as if it never happened. But now, Heather and maybe some of her colleagues have to test the bug fix, possibly retest other parts of the system, or even re-run a significant part of the regression suite. If this is repeated over and over with different developers and testers, the testing gets out of control and it's unlikely that the testers will ever finish testing the entire system. At the very least, they will have spent way too much time and money.
On the other hand, testers are also a problem. You may have heard or even said yourself, "How do you expect me to ever get this tested if you keep changing it? Testing a spec is like walking on water, it helps if it is frozen." Well, obviously if the software is frozen prematurely, at some point the testing will become unrealistic. A bug found by tester 'A,' for example, would certainly change what tester 'B' was doing if the first bug had been fixed.
The solution to Case Study 4-4 is not to fix every bug immediately or to freeze the code prematurely, but to manage the changes to the system under test. Ideally, changes should be gathered together and re-implemented into the test environment in such a way as to reduce the required regression testing without causing a halt or slowdown to the test due to a blocking bug. The changes to the software under test should begin to slow down as the system test progresses and moves into the acceptance test execution phase. Case Study 4-5 describes an example of how one company's system test plan identifies a strategy for implementing changes to their software.
Case Study 4-5: How does your organization manage changes to the software under test?
An Example Strategy for Implementing Changes
- For the first two weeks of testing, all change requests and bug fixes will be implemented in a daily build to occur at 5:30 p.m.
- For the next two weeks, the test manager, development manager, user representative, and configuration manager will meet at 10:00 every Tuesday and Thursday to prioritize all outstanding or open change requests or bug fixes. They will also decide which completed fixes will be promoted into the System Test Environment.
- For the final two weeks of scheduled system test, only" show-stopper" bug fixes will be implemented into the test environment.
Many of our students and some of our clients ask about daily builds. Daily builds are not for everyone and not for the entire software development lifecycle. Early in the development phase, unit and integration testing, and even in the early stages of the system test execution phase, daily builds can be a useful tool. However, using daily builds until the very end assures most companies that they have spent too much time doing regression testing and/or shipping a product that isn't fully tested. If the regression test suite is automated, then it is possible to extend the daily builds well into the system test execution phase, but there still needs to be a code freeze (show-stoppers aside) during the later stages of system test and during acceptance testing.
There are very few things that a test manager can do to improve the efficiency of the testing effort that will pay a dividend as much as managing how changes are re-implemented into the test environment. Some managers of testing groups have little or no control over how changes are promoted into the test environment. Other managers may not even have a clear view of what changes are introduced and when (i.e., the developer has total control of the software under test). If you fall into one of these two categories, getting control of how changes are promoted into your test environment should be one of your top priorities. Otherwise, you're not really managing the testing effort - you're only reacting to the changes to your environment.
| Key Point |
There are very few things that a test manager can do to improve the efficiency of the testing effort that will pay a dividend as much as managing how changes are re-implemented into the test environment. |
Exit Entrance Criteria
Exit and entrance criteria are important issues that should be addressed in the system test plan. If the system test execution is started prior to the conclusion of integration testing (in order to shorten the lifecycle), then many of the bugs that would have been contained during the developmental testing (e.g., unit and integration) may be discovered during system test, where the cost to find and fix them is much greater. For example, in Figure 4-12, the defect found at point 'A' might have been discovered during integration testing had integration testing concluded prior to the start of system testing.
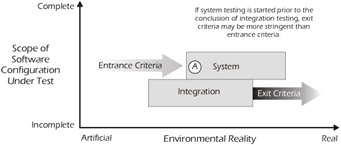
Figure 4-12: Consequences of Overlapping Test Levels
| Key Point |
Many organizations begin executing one level of test before the prior one completes, in order to field the system sooner. The downside of this strategy is that it typically requires more resources. |
If a developer discovers a bug in his or her code during unit or integration testing, he or she normally just fixes it without advertising the problem. If the same bug is discovered during system test, it has to be documented, prioritized, returned to the developer for correction, and ultimately reintroduced into the system test environment for re-testing and appropriate regression testing. During this time, the developer may have already moved on to something else. Debugging is often significantly more difficult for bugs found by the tester in the system as opposed to finding them in unit or integration testing.
Automation of regression test suites (or any other, for that matter) is difficult if the software and, consequently, the test cases have to change frequently. In fact, if the software is too unstable and changing too rapidly, some test automation techniques would probably prove to be counterproductive and it would be easier to test manually. To help solve these problems, it's useful to create exit criteria from the developer's test (unit or integration) and entrance criteria into system test. We would also need to consider exit criteria from system test and entrance criteria into acceptance test. Case Study 4-6 describes one company's exit criteria from their developmental tests.
Case Study 4-6: How does your organization define developmental tests? What are your exit criteria?
Example Exit Criteria from Developmental Tests
- All unit and integration tests and results are documented.
- There can be no High severity bugs.
- There must be 100% statement coverage.
- There must be 100% coverage of all programming specifications.
- The results of a code walkthrough are documented and acceptable.
The exit criteria that this company defined are somewhat of a wish list. Some test managers would be happy if the code just compiled cleanly. At a minimum, test cases and results should be documented, and if it is part of your culture (and we hope it is), the results of the code walkthroughs should also be documented.
| Key Point |
Developmental tests are those levels of test that are normally accomplished by the developer. In this book, those levels are Unit and Integration. |
The entrance criteria should include all or some of the exit criteria from the previous level, plus they may contain statements about the establishment of the test environment, gathering of data, procurement and installation of tools, and if necessary, the hiring or borrowing of testers. If you are having difficulty receiving a stable system, you might want to consider building a "smoke" test as part of the entrance criteria.
Smoke Test
A smoke test is a group of test cases that establish that the system is stable and all major functionality is present and works under "normal" conditions. The purpose of a smoke test is not to find bugs in the software, although you might, but rather to let the system test team know what their starting point is. It also provides a goal for the developers and lets them know when they have achieved a degree of stability.
| Key Point |
A smoke test is a group of test cases that establish that the system is stable and all major functionality is present and works under "normal" conditions. |
The smoke test cannot be created autonomously by the testing team, but should be done jointly or at least with the consent of the developers. Otherwise, the developers will feel like the testers are dictating to them how to do their job, and no buy-in will be achieved for the smoke test. Then, all you'll have is a smoke test that may or may not work, and the developer will say, "So what?" Remember that buy-in is the key to success.
The trick to establishing a good smoke test is to create a group of tests that are broad in scope, as opposed to depth. Remember that the purpose is to demonstrate stability, not to find every bug in the system. We like to take our smoke test cases from the regression test set, so the smoke test becomes a subset of the regression test set. We also like to target the smoke tests as the very first tests that we attempt to automate.
It doesn't really matter if the smoke test is run by the developers or testers, but it should be run in the system test environment. The developer may want to try it in his or her environment first, but you must remember that just because it works in the development environment doesn't mean it will work in the system test environment. The test manager might want to make the test environment available to the developers, so they can run the test and have some confidence that it works prior to promoting the code to the test team.
Integration Testing
Integration testing is the level of test done to ensure that the various components of a system interact and pass data correctly among one another and function cohesively. Integration testing can be accomplished at various levels. At the lowest level, integration testing is normally done by the development group to ensure that the units work properly together. Higher levels of integration or builds may also be done by the developer or by the test team. Integration testing is the process of examining how the pieces of a system work together, especially at the interfaces. Integration can occur at various levels, as illustrated in the car example in Figure 4-13.
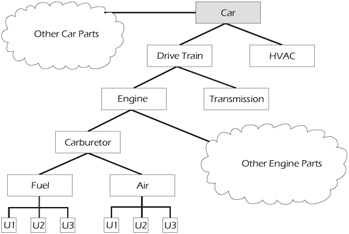
Figure 4-13: Levels of Integration in a Typical Car
| Key Point |
Integration testing is also known as string, thread, build, subsystem, and by a multitude of other names. |
Several units (e.g., U1, U2, U3) are used to make the fuel module, the fuel and the air module make the carburetor, the carburetor and other parts are used to make the engine, and so on. The levels of integration continue up the chain until the entire car is assembled. Different people might do different levels of integration testing. What you call "integration" is dependent on what you call a "system." Consider the example in Figure 4-13. If you define the system as the car, then everything below the car is integration that leads to the ultimate system. If the engine is seen as the system, then all of the parts leading to the engine are part of the integration testing. The process of testing the engine with the transmission becomes a systems integration task or a job of testing the interface between two systems. The decision of "what is a system" was described in the Introduction (Scope) section of the master test plan and may be affected by the structure of the organization, politics, staffing, and other factors.
Audience Analysis
In most organizations, the integration test plan is used primarily by developers as a "road map" to test how all the individual parts of a system fit together. The test group also uses this plan to make sure there's no overlap between what they're testing and what the developers or other test groups are testing.
Many companies that we've visited have never done integration testing per se and frequently deliver well-tested systems. In this case the integration testing is probably done as part of an extended unit testing effort or is accomplished as part of system testing. Integration testing can become very important, especially on larger, more complex systems, and in particular on new development. Some bugs that can be discovered as the units are integrated are impossible to find when testing isolated units. The interfaces between modules are the target of integration testing and are normally error-prone parts of the system.
Activity Timing
As always, we're anxious to start the test plan as soon as possible. Normally, this would mean that the integration test planning process could begin as soon as the design is beginning to stabilize.
| Note |
When should the Integration Test Plan be written? |
Developers play an important part in the development of the integration test plan because they'll eventually be required to participate in the testing. We have always felt that the developers are the most logical people to do the integration testing, since the development team really doesn't know if they have created a viable system without doing at least some integration testing. Having the developers do the integration testing also speeds the fixing of any bugs that are discovered.
| Note |
Who should write the Integration Test Plan and who should do the testing? |
Finally, in order to do integration testing, it is frequently necessary to create scaffolding code (stubs and drivers). The members of the test team may or may not have the skill set necessary to create this scaffolding code.
| Key Point |
According to Glenford Myers' The Art of Software Testing, scaffolding is code that simulates the function of non-existent components. Drivers are modules that simulate high-level components, while stubs are modules that simulate low-level components. |
One of the key issues in integration testing is determining which modules to create and integrate first. It's very desirable to integrate the riskiest components or those that are on the critical path (drivers) first, so that we can discover as early as possible if there are any major problems. There's nothing worse than discovering a fatal flaw in one of the most critical components late in the lifecycle. Another reason why the developers are often called upon to do the integration test is because the strategy of how to conduct the integration testing is controlled almost entirely by the strategy for integrating the system, which is done by the developer.
Since systems are frequently built by iteratively combining larger and larger pieces of code (and underlying functionality), there may be various levels of integration tests. The earliest levels are often used to just check the interaction of units. In many companies this is accomplished in a fairly informal fashion and is often seen as just an extension of unit testing. Integration testing is often done by individual developers working together to see how their code works. At some point, entire modules or subsystems need to be built. This is also often known as integration or build testing. Logically, build testing should be done by the developers or, in some cases, the test group.
| Note |
What do you mean by different levels of integration testing? |
Sources of Information
Typically, the integration tests are built based upon the detailed design specifications. Higher levels of integration testing may also use the high-level or architectural design specifications. Finally, even in integration testing, an effort should be made to match the software design and its corresponding test cases to the requirements.
Integration Test Planning Issues
Many strategic issues should be considered before deciding what type of integration testing to perform:
- What modules or objects should be assembled and tested as a group?
- What are the functional subassemblies?
- What are the critical features?
- How much testing is appropriate?
- Are there any implementation-based testing objectives?
- How much scaffolding code or test support code is required?
- How will problems be isolated?
- How is testing coordinated with system and unit testing?
Figure 4-14 illustrates a sample project containing a group of interacting builds. The shaded boxes represent critical-path components that must pass integration testing before the Make Reservation function can move to the system testing phase.
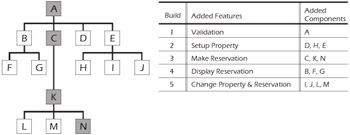
Figure 4-14: Sample Build Scheme
If any of the components A, C, K, or N are incomplete, the Make Reservation function cannot be executed without including stubs or drivers.
Configuration Management
At the earliest stages of integration testing, that is to say, as the first units are being integrated, configuration management is normally done in a fairly informal fashion with the developers and/or program leads handling most of the duty. As the builds get progressively larger, the configuration management should become more formal, as changes to the system can potentially affect the coding and testing of other developers and testers.
Test Environments
In most organizations, the integration test environment will be the development environment. Because the integration testing will commence prior to the total integration of the system, integration test cases often cannot be executed without creating stubs and/or drivers to stub out the missing pieces of code. The effectiveness of the integration testing will be directly affected by the validity of the scaffolding code.
| Key Point |
|
Often the data being used in integration testing will be made up of a subset of the production environment. Since integration testing is focused on testing the internal interfaces of the system, volume testing is not normally attempted and therefore large volumes of test data are not required.
Unit Testing
Over the course of the past several years, we have had the opportunity to present over 300 seminars on various aspects of software testing. During these seminars, one topic that receives more than its share of blank stares is "unit testing." Rick jokingly tells the audience that "there's an IEEE standard (IEEE Std. 1008-1987, Standard for Software Unit Testing) for unit testing, but so far only one copy has been sold and I own it!" Refer to Figure 4-15.
IEEE Std. 1008-1987 for Software Unit Testing
Contents
1.
Scope and References
1.1
Inside the Scope
1.2
Outside the Scope
1.3
References
2.
Definitions
3.
Unit Testing Activities
3.1
Plan the General Approach, Resources, and Schedule
3.2
Determine Features to Be Tested
3.3
Refine the General Plan
3.4
Design the Set of Tests
3.5
Implement the Refined Plan and Design
3.6
Execute the Test Procedures
3.7
Check for Termination
3.8
Evaluate the Test Effort and Unit
Figure 4-15: Rick's copy of the Unit Testing Standard
| Key Point |
A simplified template for a unit test plan is contained in Appendix E. |
This section will explore some of the reasons why unit testing is done poorly (or not at all), why unit testing is important, and some ideas for implementing formal unit testing within an organization.
Common Obstacles in Unit Testing
Most developers are quick to learn that their job is to create code. Management may talk about the importance of unit testing, but their actions contradict their words. Developers are measured and rewarded for producing code. It's true that developers may also be penalized for excessive bugs in their code, but the pressure to get the code out the door often outweighs every other concern. Another problem is the attitude of the developers themselves. Most seem to be eternal optimists, and when placed under the gun, they believe their code will work correctly and unit testing is something to do only if time permits (which, of course, it never does).
| Note |
"It's not my job to do unit testing." |
An extension of this problem is the normal situation in most companies, where the developers/unit testers have not been trained to do unit testing. Many managers and some developers believe that if you know how to code, you also know how to test - as if testing was some inherent trait existent in every developer. Developers must be trained in the general concepts of testing at all levels (unit, integration, system, acceptance, etc.) and in the specific techniques necessary to effectively perform unit testing.
| Note |
"I haven't been trained to do unit testing." |
| Note |
"I don't have the tools to do unit testing." |
Finally, the proper procedures and tools have to be in place in order for developers to conduct unit testing. Documents need to be created that describe unit test plans, test designs, configuration management, etc. Adequate test tools and debuggers must also be available. Certainly, each developer needs to have access to debugging tools, code coverage tools, defect tracking systems, and library management systems. Other tools may be necessary in some organizations.
If the three preceding paragraphs describe some of the situations that exist in your organization, please read on. We have described some of the issues that need to be addressed in order to successfully implement and conduct unit testing in an organization.
Education and Buy In
The first step in implementing effective unit testing is to provide all developers with training on how to test. The training should include general training in testing methodologies as well as training on specific unit testing techniques and tools. Development managers would also benefit from participating in training on testing methodologies and techniques. Not only will the training provide them with an understanding of the discipline, it will also show support to their staff.
| Key Point |
Our testing classes have recently shown an increase in the number of developers attending. |
Many companies have independent test teams, often at the system test level. These test groups have a vested interest in the quality of the unit testing, since good unit testing can greatly facilitate the testing at higher levels by finding defects earlier in the lifecycle. Many development managers may find that the testing groups can provide some type of training for their staffs. Often the testing groups are willing (even excited) to provide a trainer or mentor to assist in the creation of unit test plans, test case design, etc.
Standards and Requirements
An effective way to develop standards is to provide company-unique samples of each kind of document required. As a minimum set the following samples should be created: unit test plan, test design, test case/test procedure, defect report, and test summary report. Unless the work is remarkably consistent from project to project, it may be necessary to provide samples for small projects (i.e., 3-4 individuals) and for larger projects, since documentation requirements are generally greater for larger projects. It's important that the samples include only the information necessary to avoid the perceived (and sometimes real) notion that documentation is being created for its own sake.
Often, the only process documentation required in addition to the sample documents is a series of flowcharts that describe how to accomplish certain tasks such as reporting a defect, checking code in and out, where and how to save test cases, when and how to implement an inspection or walkthrough, and how to use a test log. The key is to make all of these activities as simple and painless as possible.
It's important that an individual (or group) be identified as the champion of the testing process and documentation. The champion is a person whom everyone knows they can go to for help. Typically, the champion should be an opinion-leader although not necessarily a manager. In fact, the champion should probably not be in the chain of command.
| Key Point |
Developers should be responsible for creating and documenting unit testing processes. |
Developers should be responsible for creating and documenting unit testing processes. If a set of documents or procedures is passed down to the programming staff, they'll often adopt the attitude that "this is just another bureaucratic requirement." Similarly, the practitioners, possibly through the champion, must feel that the standards can be changed if they're not working. A periodic review of the procedures by a group of practitioners will help facilitate this idea.
Configuration Management
Systematic unit testing is seldom achieved without first establishing procedures for source code control. If developers are allowed unregulated control of their code during unit test, they are unlikely to execute formal unit tests that identify defects in their code, since no one likes to admit that their work is "less than perfect." Placing the code under configuration management is one way to signal that it is time for the execution of unit tests. There is a danger, of course, of establishing controls that are too rigid, especially early in the development process. Initially, it may be adequate to control source code at the team level or even at the individual developer level (if adequate guidelines are provided) rather than through the library manager, but if no procedures are established it will be difficult to differentiate between debugging and unit testing. The successful completion of a code inspection can also be used as a signal for formal unit test execution.
| Key Point |
Systematic unit testing is seldom achieved without first establishing procedures for source code control. |
Metrics
| Key Point |
Defect density is the ratio of defects to size. The most common ratio is the number of defects per thousand lines of code (KLOC). |
Another benefit of formal unit testing is that it allows the collection of unit-level metrics, which help identify problematic areas early in the development process. Although it's not necessarily an intuitive concept, programs or modules that have had large numbers of defects identified in them (and subsequently corrected) generally still have abnormally large numbers of undetected defects remaining. One reason that this phenomenon occurs may be because programs with large numbers of defects are complex or not well understood. Another reason might be that some bugs are introduced into the system as a result of implementing fixes. Organizations that can identify defect-prone modules during unit testing can tag them as high risk and ensure that they receive adequate attention prior to integration and system testing. High defect density during unit test may also signal that more time needs to be allotted for higher-level testing.
Collecting metrics during unit testing also facilitates estimating testing time and resources for future releases and helps identify areas for process improvement. One word of caution: we are interested in measuring the product and the process, but many developers may feel that they are being measured! Make sure you understand the culture and personality of the development group before you implement measurements that might appear threatening.
Case Study 4-7: Most developers would rather just fix the bugs in their code rather than reveal them.
They'd Rather Just Fix the Bugs Than Reveal Them
I've always found it difficult to collect metrics on unit testing, since most developers would rather just fix the bugs in their code rather than reveal them. This is unfortunate because knowledge of which units contained the most bugs is lost. Knowing which units had the most bugs is useful for systems testers because those buggy units tend to have more "escapes" than other units.
One test manager explained how she learned of those problematic units without requiring the developers to record their bugs. She merely asked every developer, "Of all the units that you created, which ones were the most difficult?" It turns out that the units identified as difficult had a greater concentration of bugs than the ones that weren't identified.
- Rick Craig
Reusing Unit Testware
In this era of tight budgets and schedules, it's absolutely imperative that every effort be made to maximize all resources. One way of doing this is in the reuse of work products such as test cases and procedures, test plans, etc. If unit test cases are properly documented, they can be invaluable in helping to describe the system (i.e., they can be thought of as part of the system documentation). Furthermore, well-documented test cases can be reused during regression testing and sometimes can even be reused at higher levels of test. This idea of reusing some of the unit tests at a higher level of test is a concept that some practitioners have difficulty accepting. We're not suggesting that all of the unit-level tests need to be rerun (say at integration test), or that the unit test set by itself is adequate for higher-level testing. We're only suggesting that if a unit test satisfies a testing objective at integration or system test, it may be possible to reuse it for that purpose. Running the same test case at two different levels frequently results in testing quite different attributes. All of this is a moot point, of course, if the test cases are not intelligently documented and saved (by intelligently, we mean that you know what each test case is designed to test, i.e., coverage).
| Key Point |
Well-documented test cases can be reused during regression testing and sometimes can even be reused at higher levels of test. |
Reviews, Walkthroughs, and Inspections
| Key Point |
Refer to Chapter 3 under Walkthroughs and Inspections for more information. |
More and more software engineers believe that review techniques (such as inspections) that use the power of the human mind and the dynamics of group interaction are a powerful and effective method of identifying defects. Some organizations agonize over what to inspect (code, test cases, test plans), when to conduct inspections (before unit testing, after unit testing, both before and after), and how to measure their effectiveness, but very few organizations that we have encountered regret choosing to use inspections. The use of code inspections complements systematic unit testing by helping to flag when to begin unit test execution. Inspections are also effective at finding defects that are difficult to find during unit testing and vice versa.
Buddy Testing
For some time now, we've been recommending that our clients employ a team approach ("Buddy Testing") to coding and unit testing. Using this concept, two-person teams are identified and assigned programming tasks. Developer 'A' writes the test cases for Developer 'B's specification before Developer 'B' begins coding. Developer 'B' does the same thing for Developer 'A'. There are several advantages to this technique:
- Objectivity is introduced into testing at a very low level, which is seldom achieved during developmental testing.
- By creating the test cases prior to coding, they can serve as models of the program specification requirements. Most developers will find that having the test cases available prior to coding actually changes the way they write their code. The test cases are designed to break the code as well as show that it works. Many developers who write test cases after coding merely demonstrate that their code "does what it does." Don't underestimate the power of buddy testing. This is applying the principle of preventative testing at the lowest level.
- Finally, buddy testing provides a certain degree of cross-training on the application. If developer 'A' leaves, then Developer 'B' has knowledge of his or her code.
| Key Point |
Most developers will find that having the test cases available prior to coding actually changes the way they write their code. |
The downside of buddy testing is the extra time required to write the test cases up front and for the developers to familiarize themselves with each other's specifications and code.
We've been using buddy testing for 20 years or so and first published an introduction to the process in 1995. Most of the methods we espouse as part of buddy testing are also incorporated in a larger discipline now known as extreme programming. For more information, we highly recommend Extreme Programming: Embrace Change (The XP Series) by Kent Beck.
As we explained throughout this chapter, detailed test planning must start at the beginning and proceed in parallel with the software development lifecycle in order to be effective. We recommend that you start with the basic levels of test defined by the IEEE (acceptance, system, integration and unit) and add or delete levels as necessary. If you use this approach, you'll provide yourself with a good foundation to build your detailed test plans.
Preface
- An Overview of the Testing Process
- Risk Analysis
- Master Test Planning
- Detailed Test Planning
- Analysis and Design
- Test Implementation
- Test Execution
- The Test Organization
- The Software Tester
- The Test Manager
- Improving the Testing Process
- Some Final Thoughts…
- Appendix A Glossary of Terms
- Appendix B Testing Survey
- Appendix C IEEE Templates
- Appendix D Sample Master Test Plan
- Appendix E Simplified Unit Test Plan
- Appendix F Process Diagrams
EAN: 2147483647
Pages: 114
