10.2 Basic Instruction Design Goals
10.2 Basic Instruction Design Goals
The efficiency of your programs largely depends upon the instructions that they use. Short instructions use very little memory and often execute rapidly - nice attributes to have when writing great code. On the other hand, larger instructions can often handle more complex tasks , with a single instruction often doing the work of several less-complex instructions. To enable software engineers to write the best possible code, computer architects must strike a careful compromise between overly simplistic instructions (which are short and efficient, but don't do very much work) and overly complex instructions that consume excessive memory or require too many machine cycles to execute.
In a typical CPU, the computer encodes instructions as numeric values (operation codes or opcodes ) and stores them in memory. The encoding of these instructions is one of the major tasks in instruction set design, requiring careful thought. Each instruction must have a unique opcode (clearly, two different instructions cannot share the same opcode or the CPU will not be able to differentiate them). With an n -bit number, there are 2 n different possible opcodes, so to encode m instructions requires at least log 2 ( m ) bits. The main point to keep in mind is that the size of individual CPU instructions is dependent on the total number of instructions that the CPU supports.
Encoding opcodes is a little more involved than assigning a unique numeric value to each instruction. Remember, decoding each instruction and executing the specified task requires actual circuitry. Suppose we have a 7-bit opcode. With an opcode of this size, we could encode 128 different instructions. To decode each of these 128 instructions requires a 7-line to 128-line decoder - an expensive piece of circuitry . However, assuming that the instruction opcodes contain certain (binary) patterns, a single large decoder can often be replaced by several smaller, less expensive decoders.
If an instruction set contains 128 unrelated instructions, there's little one can do other than decode the entire bit string for each instruction. However, in most architectures the instructions fall into related groups. On the 80x86 CPUs, for example, the mov(eax,ebx); and mov(ecx,edx); instructions have different opcodes because the instructions are different. However, these two instructions are obviously related in that they both move data from one register to another. The only differences between the two are their source and destination operands. This suggests that CPU designers could encode instructions like mov with a sub-opcode, and then they could encode the instruction's operands using other bit fields within the opcode.
For example, given an instruction set with only eight instructions, each with two operands, and each operand having only one of four possible values, the instructions could be encoded using three packed fields containing three, two, and two bits, respectively (see Figure 10-1). This encoding only needs three simple decoders to determine what the CPU should do. While this is a simple case, it does demonstrate one very important facet of instruction set design - it is important to make opcodes easy to decode and the easiest way to do this is to construct the opcode using several different bit fields. The smaller these bit fields are, the easier it will be for the hardware to decode and execute the instruction.
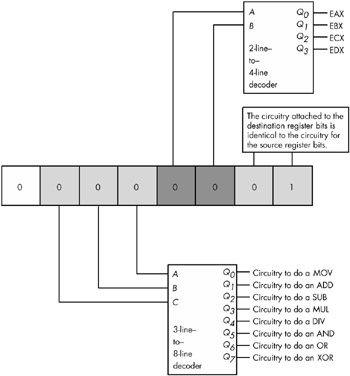
Figure 10-1: Separating an opcode into several fields to ease decoding
It would seem that when encoding 2 n different instructions using n bits, there would be very little leeway in choosing the size of the instruction. It's going to take n bits to encode those 2 n instructions; you can't do it with any fewer. It is possible, however, to use more than n bits; and believe it or not, that's the secret to reducing the average instruction size.
10.2.1 Choosing Opcode Length
Before discussing how it is possible to use larger instructions to generate shorter programs, a quick digression is necessary. The first thing to know is that the opcode length isn't arbitrary. Assuming that a CPU is capable of reading bytes from memory, the opcode will probably have to be some even multiple of eight bits long. If the CPU is not capable of reading bytes from memory (most RISC CPUs read memory only in 32- or 64-bit chunks ), then the opcode is going to be the same size as the smallest object the CPU can read from memory at one time. Any attempt to shrink the opcode size below this limit is futile. In this chapter, we'll work with opcodes that must have a length that is a multiple of eight bits.
Another point to consider here is the size of an instruction's operands. Some CPU designers include all operands in their opcode. Other CPU designers do not count operands like immediate constants or address displacements as part of the opcode. We will take the latter approach here and not count either of these as part of the actual opcode.
An 8-bit opcode can encode only 256 different instructions. Even if we don't count instruction operands as part of the opcode, having only 256 different instructions is a stringent limit. Though CPUs with 8-bit opcodes exist, modern processors tend to have far more than 256 different instructions. Because opcodes must have a length that is a multiple of 8 bits, the next smallest possible opcode size is 16 bits. A 2-byte opcode can encode up to 65,536 different instructions, though the opcode size has doubled from 8 to 16 bits (meaning that the instructions will be larger).
When reducing instruction size is an important design goal, CPU designers often employ data compression theory to reduce the average instruction size. The first step is to analyze programs written for a typical CPU and count the number of occurrences of each instruction over a large number of applications. The second step is to create a list of these instructions, sorted by their frequency of use. Next, the most frequently used instructions are assigned 1-byte opcodes; 2-byte opcodes are assigned to the next most frequently used instructions, and opcodes of three or more bytes are assigned to the rarely used instructions. Although this scheme requires opcodes with a maximum size of three or more bytes, most of the actual instructions appearing in a program will use one or two byte opcodes. The average opcode length will be somewhere between one and two bytes (let's call it 1.5 bytes), and a typical program will be shorter than had all instructions employed a 2-byte opcode (see Figure 10-2).

Figure 10-2: Encoding instructions using a variable-length opcode
Although using variable-length instructions allows one to create smaller programs, it comes at a price. First, decoding variable-length instructions is a bit more complicated than decoding fixed-length instructions. Before decoding a particular instruction field, the CPU must first decode the instruction's size. This extra step consumes time and may affect the overall performance of the CPU by introducing delays in the decoding step and, thereby, limiting the maximum clock speed of the CPU (because those delays stretch out a single clock period, thus reducing the CPU's clock frequency). Another problem with having variable-length instructions is that it makes decoding multiple instructions in a pipeline difficult, because the CPU cannot easily determine the instruction boundaries in the prefetch queue.
These reasons, along with some others, explain why most popular RISC architectures avoid variable-length instructions. However, in this chapter, we'll study a variable-length approach because saving memory is an admirable goal.
10.2.2 Planning for the Future
Before actually choosing the instructions to implement in a CPU, designers must plan for the future. The need for new instructions will undoubtedly appear after the initial design, so reserving some opcodes specifically for expansion purposes is a good idea. Given the instruction opcode format appearing in Figure 10-2, it might not be a bad idea to reserve one block of 64 1-byte opcodes, half (4,096) of the 2-byte opcodes, and half (1,048,576) of the 3-byte opcodes for future use. Giving up 64 of the very valuable 1-byte opcodes may seem extravagant, but history suggests that such foresight is rewarded.
10.2.3 Choosing Instructions
The next step is to choose the instructions to implement. Even if nearly half the instructions have been reserved for future expansion, that doesn't mean that all the remaining opcodes must be used to implement instructions. A designer can leave a good number of these instructions unimplemented, effectively reserving them for the future as well. The right approach is not to use up the opcodes as quickly as possible, but rather to produce a consistent and complete instruction set given the design compromises. The main point to keep in mind here is that it's much easier to add an instruction later than it is to remove an instruction later. So, for the first go-around, it's generally better to go with a simpler design rather than a more complex design.
The first step is to choose some generic instruction types. Early in the design process it is important to limit the choice to very common instructions. Instruction sets of other processors are probably the best place to look for suggestions when choosing these instructions. For example, most processors will have instructions like the following:
-
Data movement instructions (such as mov )
-
Arithmetic and logical instructions (such as add, sub, and, or, not )
-
Comparison instructions
-
A set of conditional jump instructions (generally used after the comparison instructions)
-
Input/output instructions
-
Other miscellaneous instructions
The designer of the CPU's initial instruction set should have the goal of choosing a reasonable set of instructions that will allow programmers to write efficient programs without adding so many instructions that the instruction set design exceeds the silicon budget or violates other design constraints. This requires strategic decisions, which CPU designers should make based on careful research, experimentation, and simulation.
10.2.4 Assigning Opcodes to Instructions
Once the initial instructions have been chosen , the next step is to assign opcodes to them. The first step is to group the instructions into sets according to the characteristics they share. For example, an add instruction is probably going to support the exact same set of operands as the sub instruction. Therefore, it makes sense to put these two instructions into the same group. On the other hand, the not instruction generally requires only a single operand, as does a neg instruction. Therefore, it makes sense to put these two instructions in the same group, but in a different group from the one with add and sub .
Once all the instructions are grouped, the next step is to encode them. A typical encoding scheme will use some bits to select the group the instruction falls into, some bits to select a particular instruction from that group, and some bits to encode the operand types (such as registers, memory locations, and constants). The number of bits needed to encode all this information can have a direct impact on the instruction's size, regardless of the instruction's usage frequency. For example, suppose two bits are needed to select an instruction's group, four bits to select the instruction within that group, and six bits to specify the instruction's operand types. In this case, the instructions are not going to fit into an 8-bit opcode. On the other hand, if all that's needed is to push one of eight different registers onto the stack, four bits will be enough to specify the push instruction group, and three bits will be enough to specify the register.
Encoding instruction operands with a minimal amount of space is always a problem, because many instructions allow a large number of operands. For example, the generic 80x86 mov instruction allows two operands and requires a 2-byte opcode. [1] However, Intel noticed that the mov( disp ,eax); and mov(eax, disp ); instructions occur frequently in programs. Therefore, they created a special 1-byte version of these instructions to reduce their size and, consequently, the size of programs that use these instructions. Note that Intel did not remove the 2-byte versions of these instructions. There are two different instructions that will store EAX into memory and two different instructions that will load EAX from memory. A compiler or assembler would always emit the shorter versions of each of these pairs of instructions.
Notice an important trade-off Intel made with the mov instruction: it gave up an extra opcode in order to provide a shorter version of one variant of each instruction. Actually, Intel uses this trick all over the place to create shorter and easier-to-decode instructions. Back in 1978, creating redundant instructions to reduce program size was a good compromise given the cost of memory. Today, however, a CPU designer would probably use those redundant opcodes for different purposes.
[1] Actually, Intel claims it's a 1-byte opcode plus a 1-byte mod-reg-r/m byte. For our purposes, we'll treat the mod-reg-r/m byte as part of the opcode.
EAN: 2147483647
Pages: 144