11.3 The mechanics of mixing text of different writing directions
| Evolving rendering needs are being documented by Unicode and are influenced by XSL-FO.
There are three categories of direction strength for Unicode characters .
The embedding algorithm is based on isolating groups of sequences in "embedding levels."
The resulting stream of characters is grouped according to the Unicode directionality controls.
Examples in this book include sequences of right-to-left language text, as defined in Example 11-1.
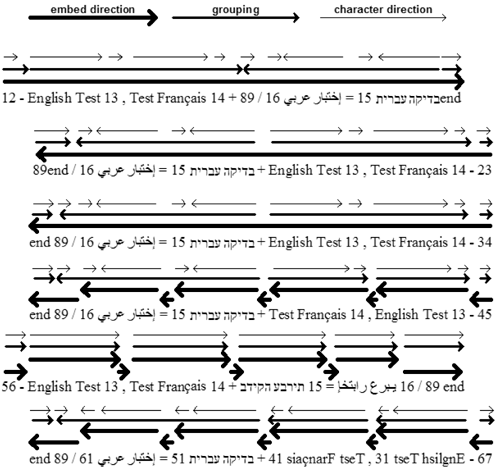
Example 11-1 Sample Unicode sequences of right-to-left language textLine 01 <!ENTITY hebrew-test "בדיקה 02 עברית"> 03 <!ENTITY arabic-test1 "إختبا"> 04 <!ENTITY arabic-test2 "ر عربي"> 05 <!ENTITY arabic-test "&arabic-test1;&arabic-test2;"> Consider a detailed example of mixing sequences of different directions in .
Example 11-2 Controlling bidirectionality using groupingLine 01 <block-container> 02 <block>12 - English Test 13 , Test Franais 14 03 + &hebrew-test; 15 = &arabic-test; 16 / 89end</block> 04 </block-container> 05 <block-container writing-mode="rl-tb"> 06 <block>23 - English Test 13 , Test Franais 14 07 + &hebrew-test; 15 = &arabic-test; 16 / 89end</block> 08 </block-container> 09 <block-container writing-mode="rl-tb"> 10 <block>34 - English Test 13 , Test Franais 14 11 + &hebrew-test; 15 = &arabic-test; 16 / 89 end</block> 12 </block-container> 13 <block-container writing-mode="rl-tb"> 14 <block>45 - <bidi-override unicode-bidi="embed" 15 >English Test 13</bidi-override> 16 , <bidi-override unicode-bidi="embed" 17 >Test Franais 14</bidi-override> 18 + <bidi-override unicode-bidi="embed" 19 >&hebrew-test; 15</bidi-override> 20 = <bidi-override unicode-bidi="embed" 21 >&arabic-test; 16</bidi-override> 22 / 89 end</block></block-container> 23 <block-container> 24 <block>56 - <bidi-override unicode-bidi="bidi-override" 25 >English Test 13</bidi-override> 26 , <bidi-override unicode-bidi="bidi-override" 27 >Test Franais 14</bidi-override> 28 + <bidi-override unicode-bidi="bidi-override" 29 >&hebrew-test; 15</bidi-override> 30 = <bidi-override unicode-bidi="bidi-override" 31 >&arabic-test; 16</bidi-override> 32 / 89 end</block></block-container> 33 <block-container writing-mode="rl-tb"> 34 <block>67 - <bidi-override unicode-bidi="bidi-override" 35 >English Test 13</bidi-override> 36 , <bidi-override unicode-bidi="bidi-override" 37 >Test Franais 14</bidi-override> 38 + <bidi-override unicode-bidi="bidi-override" 39 >&hebrew-test; 15</bidi-override> 40 = <bidi-override unicode-bidi="bidi-override" 41 >&arabic-test; 16</bidi-override> 42 / 89 end</block></block-container> Figure 11-1 illustrates the on-screen interpretation of Example 11-2.
Figure 11-1. Example of bidirectionality |
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Distributed Data Warehouse for Geo-spatial Services
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare
- Development of Interactive Web Sites to Enhance Police/Community Relations
- An Emerging Strategy for E-Business IT Governance
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- Measuring ROI in E-Commerce Applications: Analysis to Action
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control
- Governance Structures for IT in the Health Care Industry