ASP.NET State Management
Overview
The cause is hidden. The effect is visible to all.
-Ovid
All real-world applications of any shape and form need to maintain their own state to serve users' requests. ASP.NET applications are no exception, but unlike other types of applications, they need special system-level tools to achieve the result. The reason for this peculiarity lies in the stateless nature of the underlying protocol that Web applications still rely upon. As long as HTTP remains the transportation protocol for the Web, all applications will run into the same problem—they need to figure out the most effective way to persist state information.
Application state is a sort of blank container each application and programmer can fill with whatever piece of information makes sense to persist: from user preferences to global settings, from worker data to hit counters, from lookup tables to shopping carts. This extremely variegated mess of data can be organized and accessed according to a number of usage patterns. Typically, all the information contributing to the application state is distributed in various layers, each with its own set of settings for visibility, programmability, and lifetime.
ASP.NET provides state management facilities at four levels: application, session, page, and request. Each level has its own special container object, which is a topic we'll cover in this chapter. In particular, we'll explore the HttpApplicationState, HttpSessionState, and ViewState objects, which provide for application, session, and page state maintenance, respectively. In Chapter 13, we covered the HttpContext object, which is the primary tool used to manage information across the entire request lifetime. The context of the request is different from all other state objects in that the request has a limited lifetime but passes through the entire pipeline of objects processing an HTTP request. Table 14-1 summarizes the main features of the various state objects.
|
Object |
Lifetime |
Data Visibility |
Location |
|---|---|---|---|
|
Cache |
Implements an automatic scavenging mechanism, and periodically clears least-used contents |
Global to all sessions |
Does not support Web farm or Web garden scenarios |
|
HttpApplicationState |
Created when the first request hits the Web server, and released when the application shuts down |
Same as for Cache |
Same as for Cache |
|
HttpContext |
Spans the entire lifetime of the individual request |
Global to the objects involved with the request |
Same as for Cache |
|
HttpSessionState |
Created when the user makes the first request, and lasts until the user closes the session |
Global to all requests issued by the user who started the session |
Configurable to work on Web farms and gardens |
|
ViewState |
Represents the calling context of each page being generated |
Limited to all requests queued for the same page |
Configurable to work on Web farms and gardens (see Chapter 12) |
In spite of their quite unfamiliar names, the HttpApplicationState and HttpSessionState objects are state facilities totally compatible with ASP intrinsic objects such as Application and Session. Ad hoc properties known as Application and Session let you use these objects in much the same way you did in ASP.
| Note |
In this chapter, we'll review several objects involved, at various levels, with the state management. We won't discuss cookies in detail, but cookies are definitely useful for storing small amounts of information on the client. The information is sent with the request to the server and can be manipulated and re-sent through the response. The cookie is a text-based structure with simple key/value pairs and consumes no resources on the server. In addition, cookies have a configurable expiration policy. The downside of cookies is their limited size (which is browser-dependent, but seldom greater than 8 KB) and the fact that the user can disable them. In e-commerce applications, for example, cookies are the preferred way of storing persistent user-specific data such as the content of the shopping cart. |
The Application State
The HttpApplicationState object makes a dictionary available for storage to all request handlers invoked within an application. In ASP, only pages have access to the application state; this is no longer true in ASP.NET, in which all HTTP handlers and modules can store and retrieve values within the application's dictionary. The application state is accessible only within the context of the originating application. Other applications running on the system cannot access or modify the values.
An instance of the HttpApplicationState class is created the first time a client requests any resource from within a particular virtual directory. Each running application holds its own global state object. The most common way to access application state is by means of the Application property of the Page object. Application state is not shared across either a Web farm or Web garden.
Properties of the HttpApplicationState Class
The HttpApplicationState class is sealed and inherits from a class named NameObjectCollectionBase. In practice, the HttpApplicationState class is a sorted collection of pairs, each made of a string key and an object value. Such pairs can be accessed by using either the key string or the index. Internally, the base class employs a hash table with an initial capacity of zero that is automatically increased as required. The class makes no use of special hash code providers or particular comparers. In both cases, the default objects for a name/value collection are used—CaseInsensitiveHashCodeProvider and CaseInsensitiveComparer. Table 14-2 lists the properties of the HttpApplicationState class.
|
Property |
Description |
|---|---|
|
AllKeys |
Gets an array of strings containing all the keys of the items currently stored in the object. |
|
Contents |
Gets the current instance of the object. But wait! What this property returns is simply a reference to the application state object, not a clone. Provided for ASP compatibility. |
|
Count |
Gets the number of objects currently stored in the collection. |
|
Item |
Indexer property, provides read/write access to an element in the collection. The element can be specified either by name or index. Accessors of this property are implemented using Get and Set methods. |
|
StaticObjects |
Gets a collection including all instances of all objects declared in global.asax using an tag with the scope attribute set to Application. |
Note that static objects and actual state values are stored in separate collections. The exact type of the static collection is HttpStaticObjectsCollection.
Methods of the HttpApplicationState Class
The set of methods that the HttpApplicationState class features are mostly specialized versions of the typical methods of a name/value collection. As Table 14-3 shows, the most significant extension includes the locking mechanism necessary to serialize access to the state values.
Note that the GetEnumerator method is inherited from the base collection class and, as such, is oblivious to the locking mechanism of the class. If you enumerate the collection using this method, each returned value is obtained through a simple call to the BaseGetKey method—one of the methods on the base NameObjectCollectionBase class. Unfortunately, that method is not aware of the locking mechanism needed on the derived HttpApplicationState class because of the concurrent access to the application state. As a result, your enumeration would not be thread-safe. A better way to enumerate the content of the collection is by using a while statement and the Get method to access an item. Alternatively, you could lock the collection before you enumerate.
|
Method |
Description |
|---|---|
|
Add |
Adds a new value to the collection. The value is boxed as an object. |
|
Clear |
Removes all objects from the collection. |
|
Get |
Returns the value of an item in the collection. The item can be specified either by key or index. |
|
GetEnumerator |
Returns an enumerator object to iterate through the collection. |
|
GetKey |
Gets the string key of the item stored at the specified position. |
|
Lock |
Locks writing access to the whole collection. No concurrent caller can write to the collection object until UnLock is called. |
|
Remove |
Removes the item whose key matches the specified string. |
|
RemoveAll |
Calls Clear. |
|
RemoveAt |
Removes the item at the specified position. |
|
Set |
Assigns the specified value to the item with the specified key. The method is thread-safe, and access to the item is blocked until the writing is completed. |
|
UnLock |
Unlocks writing access to the collection. |
State Synchronization
Note that all operations on HttpApplicationState require some sort of synchronization to ensure that multiple threads running within an application safely access values without incurring deadlocks and access violations. The writing methods, such as Set and Remove, as well as the set accessor of the Item property implicitly apply a writing lock before proceeding. The Lock method ensures that only the current thread can modify the application state. The Lock method is provided to apply the same writing lock around portions of code that need to be protected from other threads' access.
You don't need to wrap a single call to Set, Clear, or Remove with a lock/ unlock pair of statements—those methods, in fact, are already thread-safe. Using Lock in these cases will only have the effect of producing additional overhead, which will increase the internal level of recursion.
// This operation is thread-safe Application["MyValue"] = 1;
Use Lock instead if you want to shield a group of instructions from concurrent writings.
// These operations execute atomically Application.Lock(); int val = (int) Application["MyValue"]; if (val < 10) Application["MyValue"] = Application["MyValue"] + 1; Application.UnLock();
Reading methods such as Get, the get accessor of Item, and even Count have an internal synchronization mechanism that, when used along with Lock, will protect them against concurrent and cross-thread readings and writings.
// The reading is protected from concurrent read/writes Application.Lock(); int val = (int) Application["MyValue"]; Application.UnLock();
You should always use Lock and UnLock together. However, if you omit the call to UnLock, the likelihood of incurring a deadlock is not high because the .NET Framework automatically removes the lock when the request completes or times out, or when an unhandled error occurs.
Tradeoffs of Application State
Instead of writing global data to the HttpApplicationState object, you could use public members within the global.asax file. Compared to entries in the HttpApplicationState collection, a global member is preferable because it is strongly typed and does not require hash-table access to locate the value. On the other hand, a global variable is not synchronized per se and must be manually protected.
Whatever form you choose to store the global state of an application, some general considerations apply regarding storing data globally. For one thing, global data storage results in permanent memory occupation. Unless explicitly removed by the code, any data stored in the application global state is removed only when the application shuts down. On one end, putting a few megabytes of data in the application's memory speeds up access; on the other hand, doing this occupies valuable memory for the entire duration of the application.
Storing data globally is also problematic because of locking. Synchronization is necessary to ensure that concurrent thread access doesn't cause inconsistencies in the data. But locking the application state can easily become a performance hit that leads to nonoptimal use of threads. The application global state is held in memory and never trespasses the machine's boundaries. In multimachine and multiprocessor environments, the application global state is limited to the single worker process running on the individual machine or CPU. As such, it isn't something that is really global. Finally, the duration of the data in memory is at risk because of possible failures in the process or, more simply, because of ASP.NET process recycling. If you're going to use the application state feature and plan to deploy the application in a Web farm or Web garden scenario, you're probably better off dropping global state in favor of database tables.
The Session State
The HttpSessionState class provides a dictionary-based model of storing and retrieving session-state values. Unlike HttpApplicationState, this class doesn't expose its contents to all users operating on the virtual directory at a given time. Only the requests that originate in the context of the same session—that is, generated across multiple page requests made by the same user—can access the session state. The session state can be stored and published in a variety of ways, including in a Web farm or Web garden scenario. By default, though, the session state is held within the ASP.NET worker process.
Compared to Session, which is the intrinsic object of ASP, the ASP.NET session state is nearly identical in use, but it's significantly richer in functionality and radically different in architecture. In addition, it provides some extremely handy facilities—such as support for cookieless browsers, Web farms, and Web gardens—and the capability of being hosted by external processes, including Microsoft SQL Server. In this way, ASP.NET session management can provide an unprecedented level of robustness and reliability. The programming interface of the HttpSessionState looks similar to ASP but, more importantly, the internal architecture has been tuned to provide the best throughput in what, according to reports and statistics, appears to be the most common usage scenario. The ASP.NET session-state mechanism is optimized for situations in which reading and writing operations are well balanced and occur with roughly the same frequency.
The Session State HTTP Module
The ASP.NET module in charge of setting up the session state for each user connecting to an application is an HTTP module named SessionStateModule. We already encountered this module in Chapter 12 and Chapter 13. Structured after the IHttpModule interface, the SessionStateModule object provides session-state services for ASP.NET applications.
Although the module has a poor programming interface—the IHttpModule interface contracts only for Init and Dispose methods—it does perform a number of quite sophisticated tasks, most of which are fundamental for the health and functionality of the Web application. The session-state module is invoked during the setup of the HttpApplication object that will process a given request and is responsible for either generating or obtaining a unique SessionID string and for storing and retrieving state data from an external state provider—for example, SQL Server.
State Client Managers
When invoked, the session-state HTTP module reads the settings in the section of the web.config file and determines what the expected state client manager is for the application. As Table 14-4 shows, there are three possibilities. The session state can be stored locally in the ASP.NET worker process; the session state can be maintained in an external, even remote, process named aspnet_state.exe; or finally, the session state can be managed by SQL Server and stored in an ad-hoc database table. Table 14-4 briefly discusses the various options.
|
Mode |
Description |
|---|---|
|
InProc |
Session values are kept as live objects in the memory of the ASP.NET worker process (aspnet_wp.exe or w3wp.exe in Windows Server 2003). This is the default option. |
|
StateServer |
Session values are serialized and stored in the memory of a separate process (aspnet_state.exe). The process can also run on another machine. Session values are deserialized into the session dictionary at the beginning of the request. If the request completes successfully, state values are serialized into the process memory and made available to other pages. |
|
SQLServer |
Session values are serialized and stored in a SQL Server table. The instance of SQL Server can run either locally or remotely. |
The InProc option is by far the fastest possible in terms of access. However, bear in mind that the more data you store in a session, the more memory is consumed on the Web server, which increases the risk of performance hits. If you plan to use any of the out-of-process solutions, the possible impact of serialization and deserialization should be carefully considered. We'll discuss this aspect in detail later in the chapter starting in the "Persist Session Data to Remote Servers" section.
The session-state module instantiates the state provider for the application and initializes it using the information read out of the web.config file. Next, each provider continues its own initialization, which varies depending on the type. For example, the SQL Server state manager opens a connection to the given database, whereas the out-of-process manager checks the specified TCP port. The InProc state manager, on the other hand, stores a reference to the callback function that will be used to fire the Session_OnEnd event. (I'll cover this in more detail in the section "Lifetime of a Session.")
All the actual state provider objects implement a common interface, named IStateClientManager, and by means of that interface, the session module polymorphically communicates with the provider in charge. The schema is outlined in Figure 14-1.
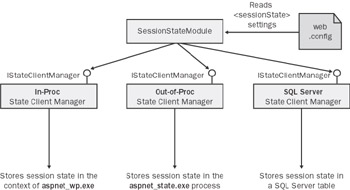
Figure 14-1: SessionStateModule and its child-state client managers.
Creating the HttpSessionState Object
The state module is also responsible for retrieving and attaching the session state to the context of each request that runs within the session. The session state is available only after the HttpApplication.AcquireRequestState event fires and gets irreversibly lost after the HttpApplication.ReleaseRequestState event. Subsequently, this means that no state is still available when Session_OnEnd fires. (For more information on the HttpApplication class and its events, see Chapter 13.)
The session module creates the HttpSessionState object for a request while processing the HttpApplication.AcquireRequestState event. At this time, the HttpSessionState object is given its SessionID and the session dictionary. The session dictionary is the actual collection of state values that pages will familiarly access through the Session property.
If a new session is being started, such a data dictionary is simply a newly created empty object. If the module is serving a request for an existing session, the data dictionary will be filled by deserializing the contents of the currently active state provider. At the end of the request, the current content of the dictionary, as modified by the page request, is flushed back to the state provider through a serialization step.
Synchronizing Access to the Session State
So when your Web page makes a call into the Session property, it's actually accessing a local, in-memory copy of the data. What if other pages attempt to concurrently access the session state? In that case, the current request might end up working on inconsistent data or data that isn't up to date.
To avoid that, the session-state module implements a reader/writer locking mechanism and queues the access to state values. A page that has session-state write access will hold a writer lock on the session until the request finishes. A page gains write access to the session state by setting the EnableSessionState attribute on the @Page directive to true. A page that has session-state read access—for example, when the EnableSessionState attribute is set to ReadOnly—will hold a reader lock on the session until the request finishes.
If a page request sets a reader lock, other concurrently running requests cannot update the session state but are allowed to read. If a page request sets a writer lock on the session state, all other pages are blocked regardless of whether they have to read or write. For example, if two frames attempt to write to Session, one of them has to wait until the other finishes. Figure 14-2 shows the big picture.
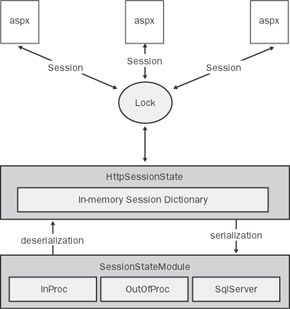
Figure 14-2: Page access to the session state is synchronized, and a serialization/deserialization layer ensures that each request is served an up-to-date dictionary of values, stored at the application's convenience.
Properties of the HttpSessionState Class
The HttpSessionState class is defined in the System.Web.SessionState namespace. It is a generic collection class and implements the ICollection and IEnumerable interfaces. Unlike HttpApplicationState, the HttpSessionState class does not inherit from an existing specialized collection class. The state values are held in an internal dictionary class named SessionDictionary. (In the .NET Framework, all dictionary classes are based on hash tables.) The properties of the HttpSessionState class are listed in Table 14-5.
|
Property |
Description |
|---|---|
|
CodePage |
Gets or sets the code page identifier for the current session. |
|
Contents |
Gets the current instance of the object. But wait! What this property returns is simply a reference to the application state object, not a clone. Provided for ASP compatibility. |
|
Count |
Gets the number of items currently stored in the session state. |
|
IsCookieless |
Gets a value that indicates whether the session ID is embedded in the URL or stored in an HTTP cookie. |
|
IsNewSession |
Gets a value that indicates whether the session was created with the current request. |
|
IsReadOnly |
Gets a value that indicates whether the session is read-only. The session is read-only if the EnableSessionState attribute on the @Page directive is set to the keyword ReadOnly. |
|
IsSynchronized |
Returns false. (This will be discussed more later in the section.) |
|
Item |
Indexer property, provides read/write access to a session-state value. The value can be specified either by name or index. |
|
Keys |
Gets a collection of the keys of all values stored in the session. |
|
LCID |
Gets or sets the locale identifier (LCID) of the current session. |
|
Mode |
Gets a SessionStateMode value denoting the state client manager being used. Acceptable values are InProc, StateServer, SQLServer, and Off. |
|
SessionID |
Gets a string with the ID used to identify the session. |
|
StaticObjects |
Gets a collection including all instances of all objects declared in global.asax by using an tag with the scope attribute set to Session. Note that you cannot add objects to this collection from within an ASP.NET application—that is, programmatically. |
|
SyncRoot |
Gets an instance of this object. (This will be discussed more later in the section.) |
|
Timeout |
Gets or sets the minutes that the session module should wait between two successive requests before terminating the session. |
The HttpSessionState class is a normal collection class because it implements the ICollection interface, but synchronization-wise it's a very special collection class. As mentioned, the synchronization mechanism is implemented in the SessionStateModule component, which guarantees that at most one thread will ever access the session state. However, because HttpSessionState implements ICollection interface, it must provide an implementation for both IsSynchronized and SyncRoot. Note that IsSynchronized and SyncRoot are collection-specific properties for synchronization and have nothing to do with the session synchronization discussed previously. They refer to the ability of the collection class (HttpSessionState in this case) to work synchronized. Technically speaking, the HttpSessionState is not synchronized as a collection class, but access to the session state is.
Methods of the HttpSessionState Class
Table 14-6 shows all the methods available in the HttpSessionState class. They are primarily involved with the typical operations of a collection. In this sense, the only exceptional method is Abandon, which causes the session to be canceled.
|
Method |
Description |
|---|---|
|
Abandon |
Sets an internal flag that instructs the session module to cancel the current session. |
|
Add |
Adds a new item to the session state. The value is boxed in an Object type. |
|
Clear |
Clears all values from the session state. |
|
CopyTo |
Copies the collection of session-state values to a one-dimensional array, starting at the specified index in the array. |
|
GetEnumerator |
Gets an enumerator to loop through all the values in the session. |
|
Remove |
Deletes an item from the session-state collection. The item is identified by the key. |
|
RemoveAll |
Calls Clear. |
|
RemoveAt |
Deletes an item from the session-state collection. The item is identified by position. |
When running the procedure to terminate the current request, the session-state module checks an internal flag to verify whether the user ordered that the session be abandoned. If the flag is set—that is, the Abandon method was called—any response cookie is removed and the procedure to terminate the session is begun. Note, though, that this does not necessarily mean that a Session_OnEnd event will fire. First, the Session_OnEnd event fires only if the session mode is InProc; second, the event does not fire if the session dictionary is empty and no real session state exists for the application. In other words, at least one request must have been completed for the Session_OnEnd event to fire when the session is closed either naturally or after a call to Abandon.
Identifying a Session
Each active ASP.NET session is identified using a 120-bit string made only of URL-allowed characters. Session IDs are guaranteed to be unique and randomly generated to avoid data conflicts and prevent malicious attacks. Obtaining a valid session ID algorithmically from an existing ID is virtually impossible. The SessionID string is communicated to the browser and then returned to the server application in either of two ways: by using cookies or a modified URL. By default, the session-state module creates an HTTP cookie on the client, but a modified URL can be used—especially for cookieless browsers—with the SessionID string embedded. Which approach is taken depends on the configuration settings stored in the application's web.config file. To configure session settings, you use the section. We fully described this configuration section in Chapter 12, but a quick refresher is in order.
cookieless="true|false" timeout="number of minutes" stateConnectionString="tcpip=server:port" sqlConnectionString="sql connection string" />
By default, the cookieless attribute is false, meaning that cookies are used. A cookie is really nothing more than a text file placed on the client's hard disk by a Web page. In ASP.NET, a cookie is represented by an instance of the HttpCookie class. Typically, a cookie has a name, a collection of values, and an expiration time. In addition, you can configure the cookie to operate on a particular virtual path and over secure connections (for example, HTTPS).
When the cookieless attribute setting is false, the session-state module actually creates a cookie with a particular name and stores the session ID in it. The cookie is created as the following pseudocode shows:
HttpCookie sessionCookie;
sessionCookie = new HttpCookie("ASP.NET_SessionId", sessionID);
sessionCookie.Path = "/";
ASP.NET_SessionId is the name of the cookie and the sessionID string is its value. The cookie is also associated with the root of the current domain. The Path property describes the relative URL that the cookie applies to. A session cookie is given a very short expiration term and is renewed at the end of each successful request. The cookie's Expires property indicates the time of day on the client at which the cookie expires. If not explicitly set, as is the case with session cookies, the Expires property defaults to DateTime.MinValue—that is, the smallest possible unit of time in the .NET Framework.
| Note |
A server-side module that needs to write a cookie adds an HttpCookie object to the Response.Cookies collection. Cookies associated with the requested domain are also available for reading through the Request.Cookies collection. |
Cookieless Sessions
To disable session cookies, you set the cookieless attribute to true in the configuration file, as shown here:
At this point, suppose that you request a page at the following URL:
http://www.contoso.com/test/sessions.aspx
What is really displayed in the browser's address bar is slightly different and now includes the session ID, as shown here:
http://www.contoso.com/test/(5ylg0455mrvws1uz5mmaau45)/sessions.aspx
When instantiated, the session-state module checks the value of the cookieless attribute. If true, the request is redirected (HTTP 302 status code) to a modified virtual URL that includes the session ID just before the page name. When processed again, the request embeds the session ID. The session ID is also stored in an extra HTTP header, named AspFilterSessionId, and in an HttpContext slot named AspCookielessSession. The following listing shows the HTTP packets exchanged between the browser and the ASP.NET runtime when a page is requested for a cookieless application:
GET /test/sessionanalyzer.aspx HTTP/1.1 Accept: */* Accept-Language: en-us Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; ...) Host: expo-star Connection: Keep-Alive HTTP/1.1 302 Found Server: Microsoft-IIS/5.0 Date: Mon, 04 Nov 2002 22:33:16 GMT Location: /test/(vz0wc1buubvzfr252f3yrqe0)/sessions.aspx Cache-Control: private Content-Type: text/html; charset=utf-8 Content-Length: 170 GET /test/(vz0wc1buubvzfr252f3yrqe0)/sessions.aspx HTTP/1.1 Accept: */* Accept-Language: en-us Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; ...) Host: expo-star Connection: Keep-Alive HTTP/1.1 200 OK Server: Microsoft-IIS/5.0 Date: Mon, 04 Nov 2002 22:33:16 GMT Cache-Control: no-cache Pragma: no-cache Content-Type: text/html; charset=utf-8 Content-Length: 14090
Figure 14-3 reveals the existence of the AspFilterSessionId header. Note, though, that this header doesn't really travel over the HTTP connection. The header is simply an extra element added to the Headers collection of the Request during the setup phase. Incidentally, the same information is also available as a server variable named HTTP_ASPFILTERSESSIONID.
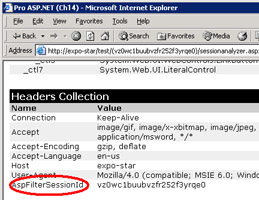
Figure 14-3: The trace of a cookieless session unveils the existence of the AspFilterSessionId header. The header is not transferred back and forth with the HTTP code but is entirely managed in memory when the HttpRequest object is set up.
Cookieless sessions cause a redirect when the session starts and whenever an absolute URL is invoked. When cookies are used, you can clear the address bar, go to another application, and then return to the previous one and retrieve the same session values. If you do this when session cookies are disabled, the session data is lost. This feature is not problematic for postbacks, which are automatically implemented using relative URLs, but it poses a serious problem if you use links to absolute URLs. In this case, a new session will always be created. The following code breaks the session:
<a href="/test/sessions.aspx">Click</a>
To use absolute URLs, resort to a little trick that uses the ApplyAppPathModifier method on the HttpResponse class:
<a href="<%"> >Click</a>
The ApplyAppPathModifier method (which was listed in Chapter 13) takes a string representing a URL and returns an absolute URL that embeds session information. For example, this trick is especially useful in situations in which you need to redirect from an HTTP page to an HTTPS page.
Generating the Session ID
A session ID is 15 bytes long by design (15x8 = 120 bits). The session ID is generated using the Random Number Generator (RNG) cryptographic provider. The service provider returns a sequence of 15 randomly generated numbers. The array of numbers is then mapped to valid URL characters and returned as a string.
| Important |
If the session contains nothing, a new session ID is generated for each request and the session state is not persisted to the state provider. However, if a Session_OnStart handler is used, the session state is always saved, even if empty. For this reason, and especially if you're not using the in-process session provider, define Session_OnStart handlers with extreme care and only if strictly necessary. In contrast, the session ID remains the same after a nonempty session dictionary times out or is abandoned. By design, even though the session state expires, the session ID lasts until the browser session is ended. This means that the same session ID is used to represent multiple sessions over time as long as the browser instance remains the same. |
Lifetime of a Session
The life of a session state begins only when the first item is added to the in-memory dictionary. The following code demonstrates how to modify an item in the session dictionary. "MyData" is the key that uniquely identifies the value. If a key named "MyData" already exists in the dictionary, the existing value is overwritten.
Session["MyData"] = "I love ASP.NET";
The Session dictionary generically contains Object types; to read data back, you need to cast the returned values to a more specific type.
string tmp = (string) Session["MyData"];
When a page or a session-enabled Web service saves data to Session, what really happens is that the value is loaded into an in-memory dictionary—an instance of an internal class named SessionDictionary. (See Figure 14-2.) Other concurrently running pages cannot access the session until the ongoing request completes.
The Session_OnStart Event
The session startup event is unrelated to the session state. The Session_OnStart event fires when the session-state module is servicing the first request for a given user that requires a new session ID. The ASP.NET runtime can serve multiple requests within the context of a single session, but only for the first of them does Session_OnStart fire. As pointed out in Chapter 13, the Session_OnStart event fires in between BeginRequest and AcquireRequestState.
A new session ID is created and a new Session_OnStart event fires whenever a page is requested that doesn't write data to the dictionary. The architecture of the session state is quite sophisticated because it has to support a variety of state providers. The overall schema entails that the content of the session dictionary be serialized to the state provider when the request completes. However, to optimize performance, this procedure really executes only if the content of the dictionary is not empty. As mentioned earlier, though, if the application defines a Session_OnStart event handler, the serialization takes place anyway.
The Session_OnEnd Event
The Session_OnEnd event signals the end of the session and is used to perform any clean-up code needed to terminate the session. Note, though, that the event is supported only in InProc mode—that is, only when the session data is stored in the ASP.NET worker process.
For Session_OnEnd to fire, the session state has to exist first. That means you have to store some data in the session state and you must have completed at least one request. When the first value is added to the session dictionary, an item is inserted into the ASP.NET cache—the aforementioned Cache object that we'll cover in detail later in the "The ASP.NET Caching System" section. The item is given a particular name and value. The name is a colon-separated string made of System.Web.SessionState.SessionStateItem and the session ID. For example, it might look like this:
System.Web.SessionState.SessionStateItem:3ov5q2550u4oxprmqyro1b55
The value of the cache entry is an internal object of type SessionStateItem (version 1.0) or InProcSessionState (version 1.1). The behavior is specific to the in-process state provider; neither the out-of-process state server nor the SQL Server state server works with the Cache object.
However, much more interesting is that the item added to the cache—only one item per active session—is given a special expiration policy. You'll learn more about the ASP.NET cache and related expiration policies in the section "The ASP.NET Caching System." For now it suffices to say that the session-state item added to the cache is given a sliding expiration, with the time interval set to the session timeout. As long as there are requests processed within the session, the sliding period is automatically renewed. The session-state module does this while processing the application's EndRequest event. The technique used to reset the timeout is pretty simple and intuitive—the session module just performs a read on the cache! Given the internal structure of the ASP.NET Cache object, this evaluates to renew the sliding period. As a result, when the cache item expires, the session has timed out.
An expired item is automatically removed from the cache. As part of the expiration policy for this item, the state-session module also indicates a remove callback function. The cache automatically invokes the remove function which, in turn, fires the Session_OnEnd event.
| Caution |
The items in Cache that represent the state of a session are not accessible from outside the System.Web assembly and can't even be enumerated. In other words, you can't access the data resident in another session or even remove it. Note that in version 1.0 of the .NET Framework, session items, as well as some other system items, are dangerously exposed to applications. Version 1.1 of the .NET Framework is more secure and does not expose these items. |
Why Does My Session State Sometimes Get Lost?
Values parked in a Session object are removed from memory either programmatically by the code or by the system when the session times out or is abandoned. In some cases, though, even when nothing of the kind seemingly happens, the session state gets lost. Is there a reason for this apparently weird behavior?
When the working mode is InProc, the session state is mapped in the memory space of the AppDomain in which the page request is being served. In light of this, the session state is subject to process recycling and AppDomain restarts. As we discussed in Chapter 2, the ASP.NET worker process is periodically restarted to maintain an average good performance; when this happens, the session state is lost. Process recycling depends on the percentage of memory consumption and maybe the number of requests served. Although the process is cyclic, no general consideration can be made regarding the interval of the cycle. Be aware of this when designing your session-based, in-process application. As a general rule, bear in mind that the session state might not be there when you try to access it. Use exception handling or recovery techniques as appropriate for your application.
In Knowledge Base article Q316148, Microsoft suggests that some antivirus software might be marking the web.config or global.asax file as modified, thus causing a new application to be started and subsequently causing the loss of the session state. This holds true also if you or your code modify the timestamp of those files. Also, any addition to or removal from the Bin directory causes the application to restart.
| Note |
What happens to the session state when a running page hits an error? Will the current dictionary be saved or is it just lost? The state of the session is not saved if, at the end of the request, the page results in an error—that is, the GetLastError method of the Server object returns an exception. However, if in your exception handler you reset the error state by calling Server.ClearError, the values of the session are saved regularly as if no error ever occurred. |
Detecting Expired Sessions
So what's the best thing to do when a session expires, and more importantly, is there a way to detect whether a session has expired? Redirecting to an error page is probably the most reasonable thing to do, unless the characteristics of the application allow for an even more graceful recovery. Normally, applications know that a session has expired only through an exception, and therefore, when it's too late.
Unfortunately, as of version 1.1, in ASP.NET there are no built-in features to quickly and effectively let applications know about expired sessions so that they could redirect users to other pages. One trick you can try entails the use of cookies. The idea is that you write a cookie when the session starts in the Session_OnStart event handler. At a certain point, the session times out or is recycled. As mentioned earlier, even though the session has expired, the session ID remains in use until the browser is closed. With the next access to the page, a new session is started, but this time the cookie is already there. This is a signal meaning that ASP.NET is reusing the same session ID but the previous session has expired. As the final step, you redirect to another page. The following code shows how to achieve this:
void Session_OnStart(Object sender, EventArgs e)
{
HttpContext context = HttpContext.Current;
HttpCookieCollection cookies = context.Request.Cookies;
if (cookies["started_at"] == null)
{
HttpCookie cookie;
Cookie = new HttpCookie("started_at", DateTime.Now.ToString());
cookie.Path = "/";
context.Response.Cookies.Add(cookie);
}
else
{
context.Response.Redirect("session_expired.aspx");
}
}
Persist Session Data to Remote Servers
The session state loss problem we mentioned earlier for InProc mode can be neatly solved by employing either of the two out-of-process state providers—StateServer and SQLServer. In this case, though, the session state is held outside the ASP.NET worker process and an extra layer of code is needed to serialize and deserialize it to and from the actual storage medium. This operation takes place whenever a request is processed.
The need for copying session data from an external repository into the local session dictionary might tax the state management process to the point of causing a 15 percent to 25 percent decrease in performance. Note, though, that this is only a rough estimate, but it's closer to the minimum impact than to the maximum impact. The estimate, in fact, doesn't fully consider the complexity of the types actually saved into the session state.
State Serialization and Deserialization
When you use the InProc mode, objects are stored in the session state as live instances of classes. No real serialization and deserialization ever take place, meaning that you can actually store in Session whatever objects (including COM objects) you have created and access them with no significant overhead. The situation is less favorable if you opt for an out-of-process state provider.
In an out-of-process architecture, session values are to be copied from the native storage medium into the memory of the AppDomain that processes the request. A serialization/deserialization layer is needed to accomplish the task and represents one of the major costs for out-of-process state providers. How does this affect your code? First, you should make sure that only serializable objects are ever stored in the session dictionary; otherwise, as you can easily guess, the session state can't be saved.
| Note |
In ASP.NET 1.0, if you try to save a nonserializable object (for example, a COM object) in the session dictionary using SQL Server, the problem can go unnoticed. If you're working in StateServer mode, an exception is thrown instead. |
To perform the serialization and deserialization of types, ASP.NET uses two methods, each providing different results in terms of performance. For basic types, ASP.NET resorts to an optimized internal serializer; for other types, including objects and user-defined classes, ASP.NET makes use of the .NET binary formatter, which is slower. Basic types are string, DateTime, Boolean, byte, char, and all numeric types.
The optimized serializer—an internal class named AltSerialization—employs a BinaryWriter object and writes out one byte to denote the type and then the value. While reading, the AltSerialization class first extracts one byte, detects the type of the data to read, and then resorts to a type-specific ReadXxx method on the BinaryReader class. The type is associated with an index according to an internal table, as shown in Figure 14-4.
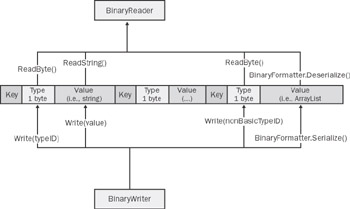
Figure 14-4: The serialization schema for basic types that the internal AltSerialization class uses.
| Note |
While Booleans and numeric types have a well-known size, the length of a string can vary quite a bit. How can the reader determine the correct size of a string? The BinaryReader.ReadString method exploits the fact that on the underlying stream the string is always prefixed with the length, encoded as an integer seven bits at a time. Values of the DateTime type, on the other hand, are saved by writing only the total number of ticks that form the date and are read as an Int64 type. |
As mentioned, more complex objects are serialized using the BinaryFormatter class as long as the involved types are marked as serializable. Both simple and complex types use the same stream, but all nonbasic types are identified with the same type ID. The performance-hit range of 15 percent to 25 percent is a rough estimate based on the assumption that basic types are used. The more you use complex types, the more the overhead grows, but reliable numbers can be calculated only by testing a particular application scenario.
In light of this, if you plan to use out-of-process sessions, make sure you store data effectively. For example, if you need to persist an instance of a class with three string properties, performancewise you are probably better off using three different slots filled with a basic type rather than one session slot for which the binary formatter is needed. However, understand that this is merely a guideline to be applied case by case and with a grain of salt. If you have a class with 100 string properties, you should probably store it as an object!
Storing Session Data
When working in StateServer mode, the entire content of the HttpSessionState object is serialized to an external application—a Microsoft Windows NT service named aspnet_state.exe. The service is called to serialize the session state when the request completes. The service internally stores each session state as an array of bytes. When a new request begins processing, the array corresponding to the given session ID is copied into a memory stream and then deserialized into an internal SessionStateItem object. This object really represents the session state. The HttpSessionState object that pages actually work with is only its application interface.
In Figure 14-5, you can see the overall format of a serialized session state as saved into the aspnet_state.exe Windows NT service.

Figure 14-5: The session state as persisted in an out-of-process state provider.
The array of bytes contains an integer denoting the timeout of the session and whether the session is cookieless, a couple of Boolean values indicating whether the session has a nonempty dictionary, and at least one static object. The bytes that follow represent the dictionary (with the previously described format) and the list of serialized static objects.
Static objects are objects—both COM and managed—that are statically declared in the global.asax file with a session scope. Figure 14-6 illustrates the binary layout of the StaticObjects collection of the session. The first bytes indicate how many objects are going to be serialized. Next, each object is serialized in a structure that includes: the abbreviated name; a Boolean value indicating whether the object has been instantiated, the serialization of the instance, and the .NET full name of the object; and a final Boolean value indicating whether or not the object is late bound.
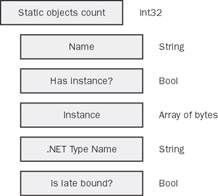
Figure 14-6: The persistence schema of the StaticObjects collection.
Note though that you cannot have static COM objects declared with a session scope if you're using an out-of-process state provider.
Configuring the StateServer Provider
Using out-of-process storage scenarios, you give the session state a longer life and your application greater robustness. Out-of-process session-state storage basically protects the session against Internet Information Services (IIS) and ASP.NET process failures. By separating the session state from the page itself, you can also much more easily scale an existing application to Web farm and Web garden architectures. In addition, the session state living in an external process eliminates at the root the risk of periodically losing data because of process recycling.
As mentioned, the ASP.NET session-state provider is a Windows NT service named aspnet_state.exe. It normally resides in the following folder:
C:WINNTMicrosoft.NETFrameworkv1.1.4322
As usual, notice that the final directory depends on the .NET Framework version you're actually running. Before using the state server, you should make sure the service is up and running on the local or remote machine used as the session store. The state service is a constituent part of ASP.NET and gets installed along with it, so you have no additional setup to run.
By default, the state service is stopped and requires a manual start. You can change its configuration through the property dialog box of the service, as shown in Figure 14-7.
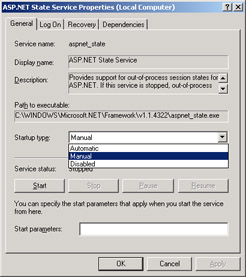
Figure 14-7: The property dialog box of the ASP.NET state server.
An ASP.NET application needs to specify the TCP/IP address of the machine hosting the session-state service. The following listing shows the changes needed to the web.config file to enable the remote session state:
Note that the value assigned to the mode attribute is case sensitive. The format of the stateConnectionString attribute is shown in the following line of code. The default machine address is 127.0.0.1, while the default port is 42424.
stateConnectionString="tcpip=server:port"
The server name can be either an IP address or a machine name. In this case, though, non-ASCII characters in the name are not supported. Finally, the port number is mandatory and cannot be omitted.
The ASP.NET application attempts to connect to the session-state server immediately after loading. The aspnet_state service must be up and running, otherwise an HTTP exception is thrown. By default, the service is not configured to start automatically.
| Caution |
When the session state is stored out of process, COM objects cannot be stored in the Session object because they aren't serializable. This limitation isn't specific to COM objects, however. Any nonserializable object cannot be stored in Session when the application session-state service works out of process. |
Persist Session Data to SQL Server
Maintaining the session state in an external process certainly makes the whole ASP.NET application more stable. Whatever happens to the aspnet_wp.exe worker process, the session state is still there, ready for further use. If the service is paused, the data is preserved and automatically retrieved when the service resumes. Unfortunately, if the state provider service is stopped or if a failure occurs, the data is lost. If robustness is key for your application, drop the StateServer mode in favor of SQLServer.
Performance and Robustness
When ASP.NET works in SQLServer mode, the session data is stored in a made-to-measure database table. As a result, the session data survives even SQL Server crashes, but you have to add a higher overhead to the bill. SQLServer mode allows you to store data on any connected machine, as long as the machine runs SQL Server 7.0 or later. Besides the different medium, the storage mechanism is nearly identical to that described for remote servers. In particular, the serialization and deserialization algorithm is the same, only a bit slower. When storing data of basic types, the time required to set up the page's HttpSessionState object is normally at least 25 percent higher than in an InProc scenario. Also in regard to this issue, the more complex types you use, the more time will probably be required to manage the session data.
Creating and Configuring the Database
To use SQL Server as the state provider, enter the following changes in the section of the web.config file:
In particular, you need to set the mode attribute (which is case sensitive) to SQLServer and specify the connection string through the sqlConnectionString attribute. Notice that the sqlConnectionString attribute string must include user ID, password, and server name. It cannot contain, though, tokens such as Database and Initial Catalog. User ID and passwords can be replaced by integrated security.
ASP.NET provides two pairs of scripts to configure the database environment. The first pair of scripts are named InstallSqlState.sql and UninstallSqlState.sql. They create a database named ASPState and several stored procedures. The data, though, is stored in a couple of tables in the TempDB database. In SQL Server, the TempDB database provides a storage area for temporary tables, temporary stored procedures, and other temporary working storage needs. This means that the session data is lost if the SQL Server machine is restarted.
The second pair consists of InstallPersistSqlState.sql and UninstallPersistSqlState.sql. An ASPState database is created in this case also, but the tables are persistent because they are created within the same database. All scripts are located in the following path:
%SystemRoot%Microsoft.NETFrameworkv1.1.4322
| Note |
Note that in ASP.NET 1.0 only the first pair of scripts were installed. Soon after, though, Microsoft addressed the issue of persistent SQL Server session state with Knowledge Base article Q311209. |
The tables that get created are named ASPStateTempApplications and ASPStateTempSessions. Figure 14-8 shows a view of the session database in SQL Server.
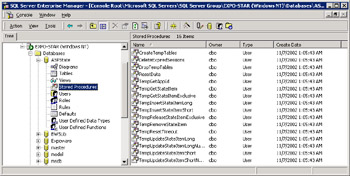
Figure 14-8: The ASPState database in SQL Server 2000.
The ASPStateTempApplications table defines a record for each currently running ASP.NET application. The table columns are listed in Table 14-7.
|
Column |
Type |
Description |
|---|---|---|
|
AppId |
Int |
Indexed field, represents a sort of autogenerated ID identifying a running application using the SQLServer session mode. |
|
AppName |
Char(280) |
Indicates the application ID of the AppDomain running the application. Matches the HttpRuntime.AppDomainAppId property. |
The ASPStateTempSessions table stores the actual session data. The table contains one row for each active session. The structure of the table is outlined in Table 14-8.
|
Column |
Type |
Description |
|---|---|---|
|
SessionId |
Char(32) |
Indexed field, represents the session ID. |
|
Created |
DateTime |
Indicates the time in which the session was created. Defaults to the current date. |
|
Expires |
DateTime |
Indicates the time in which the session will expire. This value is normally the time in which the session state was created plus the number of minutes specified in Timeout. Note that Created refers to the time at which the session started. On the other hand, Expires adds minutes to the time in which the first item is added to the session state. |
|
LockDate |
DateTime |
Indicates the time in which the session was locked to add the last item. |
|
LockCookie |
Int |
Indicates the number of times the session was locked—that is, the number of accesses. |
|
Timeout |
Int |
Indicates the timeout of the session in minutes. |
|
Locked |
Bit |
Indicates whether the session is currently locked. |
|
SessionItemShort |
VarBinary(7000) |
Nullable field, represents the values in the specified session. The layout of the bytes is identical to the layout discussed for StateServer providers. If more than 7000 bytes are needed to serialize the dictionary, the SessionItemLong field is used instead. |
|
SessionItemLong |
Image |
Nullable field, represents the serialized version of a session longer than 7000 bytes. |
In spite of the baffling type name, the column SessionItemLong, contains a long binary block of data. Although the user always works with image data as if it is a single, long sequence of bytes, the data is not stored in that format. The data is stored in a collection of 8-KB pages that aren't necessarily located next to each other. (For more information, see SQL Server's Books Online.)
When installing the SQL Server support for sessions, a job is also created to delete expired sessions from the session-state database. The job, which is shown in Figure 14-9, is named ASPState_Job_DeleteExpiredSessions, and the default configuration makes it run every minute. You should note that the SQLServerAgent service needs to be running for this to work.
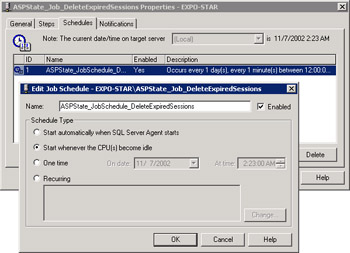
Figure 14-9: The SQL Server job to delete expired sessions.
Working in a Web Farm Scenario
ASP.NET applications designed to run in a Web farm or Web garden hardware configuration cannot implement an in-process session state. The InProc mode won't work on a Web farm because a distinct aspnet_wp.exe process will be running on each connected machine, with each process maintaining its own session state. It doesn't even work on a Web garden because multiple aspnet_wp.exe processes will be running on the same machine.
Keeping all states separate from worker processes allows you to partition an application across multiple worker processes even when they're running on multiple computers. In both Web farm and Web garden scenarios, there can be only one StateServer or SQLServer process to provide session-state management.
As mentioned in Chapter 12, if you're running a Web farm, make sure you have the same in all your Web servers. (More details can be found in Knowledge Base article Q313091.) In addition, for the session state to be maintained across different servers in the Web farm, all applications should have the same application path stored in the IIS metabase. This value is set as the AppDomain application ID and identifies a running application in the ASP.NET state database. (See Knowledge Base article Q325056 for more details.)
The View State of a Page
ASP.NET pages supply the ViewState property to let applications build a call context and retain values across two successive requests for the same page. The view state represents the state of the page when it was last processed on the server. The state is persisted—usually, but not necessarily, on the client side—and is restored before the page request is processed. We analyzed the overall page life cycle in Chapter 2. By default, the view state is maintained as a hidden field added to the page. As such, it travels back and forth with the page itself. Although sent to the client, the view state does not represent, nor does it contain, any information specifically aimed at the client. The information stored in the view state is pertinent only to the page and some of its child controls.
Using the view state has advantages and disadvantages you might want to carefully balance prior to making your state management decision. First, the view state doesn't require any server resources and is simple to implement and use. Because it's a physical part of the page, it's fast to retrieve and use. This last point, which in some respects is a strong one, turns into a considerable weakness as soon as you consider the page performance from a wider perspective.
Because the view state is packed with the page, it inevitably charges the HTML code transferred over HTTP with a few extra kilobytes of data—useless data, moreover, from the client's perspective. A complex real-world page, especially if it does not even attempt to optimize and restrict the use of the view state, can easily find 10 KB of extra stuff packed in the HTML code sent out to the browser. Finally, security is another hot topic for view states. Although you're not supposed to store sensitive data in the view state (for example, credit card numbers, passwords, or connection strings), the view state can still be a victim of malicious code. We'll return to security topics later in the "Common Issues with View State" section.
In summary, the view state is one of the most important features of ASP.NET, not so much because of its technical relevance but because it allows most of the magic of the Web Forms model. Used without strict criteria, the view state can easily become a burden for pages. Security issues also stand out, but countermeasures are in place, thus making the "real" risk of getting damaged much less significant than one might think at first.
The StateBag Class
The StateBag class is the class behind the view state that manages the information that ASP.NET pages and controls want to persist across successive posts of the same page instance. The class works like a dictionary and, in addition, implements the IStateManager interface. The Page and Control base classes expose the view state through the ViewState property. So you can add or remove items from the StateBag class as you would with any dictionary object, as the following code demonstrates:
ViewState["FontSize"] = value;
You should start writing to the view state only after the Init event fires for the page request. You can read from the view state during any stage of the page lifecycle, but not after the page enters rendering mode—that is, after the PreRender event fires.
View State Properties
Table 14-9 lists all the properties defined in the StateBag class.
|
Property |
Description |
|---|---|
|
Count |
Gets the number of elements stored in the object |
|
Item |
Indexer property, gets or sets the value of an item stored in the class |
|
Keys |
Gets a collection object containing the keys defined in the object |
|
Values |
Gets a collection object containing all the values stored in the object |
Each item in the StateBag class is represented by a StateItem object. An instance of the StateItem object is implicitly created when you set the Item indexer property with a value or when you call the Add method. Items added to the StateBag object are tracked until the view state is saved to the storage medium using the page's SaveViewState protected method. StateItem objects not saved yet have the IsDirty property return true.
View State Methods
Table 14-10 lists all the methods you can call on the StateBag class.
|
Method |
Description |
|---|---|
|
Add |
Adds a new StateItem object to the collection. If the item already exists, it gets updated. |
|
Clear |
Removes all items from the current view state. |
|
GetEnumerator |
Returns an object that scrolls over all the elements in the StateBag. |
|
IsItemDirty |
Indicates whether the element with the specified key has been modified during the request processing. |
|
Remove |
Removes the specified object from the StateBag object. |
The IsItemDirty method represents an indirect way to call into the IsDirty property of the specified StateItem object.
| Note |
The view state for the page is a cumulative property that results from the contents of the ViewState property of the page plus the view state of all the controls hosted in the page. |
Common Issues with View State
Architecturally speaking, the importance of the view state cannot be denied, as it is key to setting up the automatic state-management feature of ASP.NET. A couple of hot issues are connected to the usage of the view state, however. Most frequently asked questions about the view state are related to security and performance. Can we say that the view state is inherently secure and cannot be tampered with? How will the extra information contained in the view state affect the download time of the page? Let's find out.
Encrypting and Securing
Many developers are doubtful about using view state just because it's stored in a hidden field and left on the client at the mercy of potential intruders. As Figure 14-10 demonstrates, the information can be read if the page output source is viewed directly. While this action alone is certainly not a threat to the application (although it violates data confidentiality), having the view state on the client side does represent a potential security issue. Although the data is stored in a hashed format, there's no absolute guarantee that it cannot be tampered with.
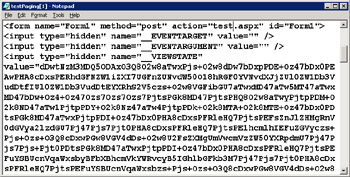
Figure 14-10: A view of the hashed and encoded view state for a not-too-complex page.
Although freely accessible in a hidden field named __VIEWSTATE, the view state information is hashed and Base64 encoded. To decode it, a number of steps must be completed and a number of circumstances must occur. In addition, consider that a tampered view state is normally detected on the server and an exception is thrown. Finally, and most importantly of all, the view state contains data, not code. What a hacker could perhaps do is modify the data that represents the state of the page to restore. This results in open holes for attacks only if basic rules of data validation and data checking are not enforced. But this, you understand, is a more general problem that affects writing secure code.
Machine Authentication Check
As mentioned in Chapter 1, the @Page directive contains an attribute named EnableViewStateMac, whose only purpose is making the view state a bit more secure by detecting any possible attempt to corrupt the original data. When serialized, and if EnableViewStateMac is set to true, the view state is appended with a validator hash string based on the algorithm and the key defined in the section of the machine.config file. The resulting array of bytes, the output of the StateBag's binary serialization plus the hash value, is Base64 encoded. By default, the encryption algorithm to calculate the hash is SHA1 and the encryption and decryption keys are auto-generated and stored in the Web server machine's Local Security Authority (LSA) subsystem. The LSA is a protected component of Windows NT, Windows 2000, and Windows XP. It provides security services and maintains information about all aspects of local security on a system.
If EnableViewStateMac is true, the hash value is extracted when the page posts back and is used to verify that the returned view state has not been tampered with on the client. If this is the case, an exception is thrown. The net effect is that you might be able to read the contents of the view state, but to replace it you need the encryption key, which is in the Web server's LSA.
The MAC in the name of the EnableViewStateMac property stands for Machine Authentication Check and, in spite of what some old documentation claims, it is enabled by default. The EnableViewStateMac attribute corresponds to a protected Page member with the same name.
If you disable the attribute, an attacker could crack the view state on the client and send a modified version to the server and have ASP.NET blissfully use that tampered-with information. To reinforce the security of the view state, in ASP.NET 1.1 the ViewStateUserKey property has also been added to the Page class. The property evaluates to a user-specific string (for example, the session ID or the user name) that is known on the server. ASP.NET uses the content of the property as an input to the hash algorithm that generates the MAC code.
Size Thresholds and Page Throughput
My personal opinion is that you should be concerned about the view state, but not because of the potential security holes it might open in your code—it can only let hackers exploit existing holes. You should be more concerned about the overall performance and responsiveness of the page. Especially for feature-rich pages that make use of plenty of controls, the view state can reach a considerable size, measured in KB of data. Such an extra burden taxes all requests and ends up being a serious overhead for the application as a whole.
The use of the view state feature should be carefully monitored because it can hinder your code. By default, the view state is enabled for all server controls; this doesn't mean that you strictly need it all the time. View state saves you from a lot of coding and, more importantly, makes coding simpler and smarter. However, if you find you're paying too much for this feature, drop view state altogether and reinitialize the state of the server controls at every postback. In this case, disabling view state saves processing time and speeds up the download process.
You can disable the view state for an entire page by using the EnableViewState attribute of the @Page directive. While this is not generally a recommended option, you should definitely consider it for read-only pages that either don't post back or don't need state to be maintained.
<% @Page EnableViewState="false" %>
A better approach entails disabling the view state only for some server controls hosted in the page. To disable it on a per-control basis, set the EnableViewState property of the control to false, as shown here:

While developing the page, you can keep the size of the view state under control by enabling tracing on the page. Once you have set the @Page trace attribute to true, look under the Viewstate Size Bytes column of the control tree, as shown in Figure 14-11.
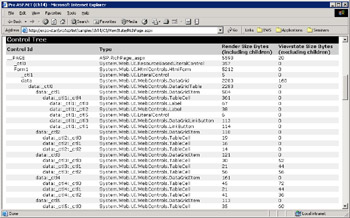
Figure 14-11: The view state size, control by control.
The tracer doesn't show the total amount of the view state for the page, but it lets you form a precise idea of what each control does. In Figure 14-11, the page contains a relatively simple DataGrid control. As you can see, the cells of the grid take up a large part of the view state. The TableCell control, in particular, saves the view state of all its user interfaces, including text, column, and row span style attributes.
| Note |
Contrary to what many developers think, the DataGrid server control doesn't store its data source in the view state. The DataGrid control per se caches almost all its public properties, but the amount of space required is not related to the data source. However, the DataGrid uses child controls—for example, the TableCell—which also store their text and style in view state. The text displayed in the cells is part of the DataGrid data source. |
In Figure 14-12, you see the same page with a client-side button that retrieves the view state string and calculates its length. The JavaScript code needed is pretty simple:
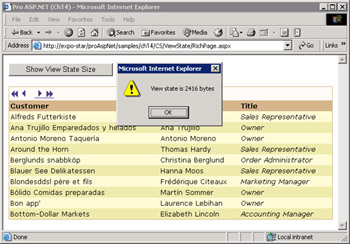
Figure 14-12: The overall view state size obtained scriptwise.
Programming Web Forms Without View State
Let's briefly recap what view state is all about and what you might lose if you ban it from your pages. View state represents the current state of the page and its controls just before the page is rendered to HTML. When the page posts back, the view state—a sort of call context for the page request—is recovered from the hidden field, deserialized, and used to initialize the server controls in the page and the page itself. However, as pointed out in Chapter 2, this is only the first half of the story.
After loading the view state, the page reads client-side information through the Request object and uses those values to override most of the settings for the server controls. In general, the two operations are neatly separated and take place independently. In particular, though, the second operation—reading from Request.Form—in many situations ends up just overriding some of the settings read out of the view state. You understand that in this case the view state is only an extra burden.
Let's examine a typical case and suppose you have a page with a text box server control. What you expect is that when the page posts back, the text box server control is automatically assigned the value set on the client. Well, to meet this rather common requirement, you don't need view state. Let's consider the following page:
<% @Page language="c#" EnableViewState="false" %>
The behavior of the page is stateful even if view state is disabled. The reason lies in the fact that you are using two server controls—TextBox and CheckBox—whose key properties are updated according to the values set by the user. These values will override any setting view state might have set. As a result, as long as you're simply interested in persisting properties such as Text or Checked, you don't need view state at all.
| Note |
You don't need view state for the properties of a control whose value is ultimately determined by the posted data. For example, this is what happens for the Text property of a TextBox but not for ReadOnly or MaxLength. |
All the properties declared as tag attributes are automatically restored as specified during the initialization of the control. As long as these extra properties are not expected to change during the session, you don't need view state at all. So when is view state really necessary?
Suppose that your text box can be edited only if the user has certain privileges. A possible implementation entails that you declare the text box as read-only and turn off the attribute the first time the page is loaded after checking the user's credentials. The code might be as follows:
<% @Page language="C#" %>
This programming style is inherently stateful and works as expected as long as you have view state enabled. Try setting the EnableViewState attribute to false and then re-run the page. In the OnInit page event, the text box is instantiated as declared in the page layout—that is, with the ReadOnly property equal to true. The first time the page is processed (IsPostBack returns false), the attribute is programmatically turned on according to the user's role. So far so good.
The preceding code, though, is stateful in the sense that it assumes that after the first access to the page, the run time can remember all settings. This is no longer the case if you turn view state off. In this case, because IsPostBack now returns true, the Page_Load event never has a chance to modify the text box ReadOnly property. Because the view state is disabled, the ReadOnly property remains set to true whatever the user's role is. By choosing an alternative programming style, you can obtain the same function without resorting to view state, thus saving 40 bytes of HTML for each instance of a TextBox control. The following code shows in boldface type the changes needed to disable view state for the page:
<% @Page language="c#" EnableViewState="false" %>
readonly="false" text="Type your UID here" />
In some cases, you can disable view state and still have the page run unchanged. In other cases, some minor changes must be entered to the code to make sure all properties of all controls are properly initialized. In general, you can do without view state whenever the state can be deduced either from the client or from the runtime environment (for example, by determining whether the user has certain privileges). In contrast, doing without view state is hard whenever state information can't be dynamically inferred. For example, if you want to track the sort order of a pageable DataGrid, you can cache it only in the view state.
Keeping the View State on the Server
As discussed so far, there are a couple of good reasons to keep the view state off the client browser. First, the view state can be tampered with, at least in theory. Second, the more stuff you pack into the view state, the more time the page takes to download. These two apparently unrelated issues have a common root—the view state is stored on the client through a hidden field. However, the client-side hidden field is not set in stone and is simply the default storage medium where the view state information can be stored. Let's see how to proceed to save the view state in a file on the Web server.
The LosFormatter Class
To design an alternative storage scheme for the view state, we need to put our hands on the string that ASP.NET stores in the hidden field. The string will be saved in a server-side file and read from where the page is being processed. When it comes to doing this, there is bad news and good news. The bad news is that the Base64 view state string is not publicly exposed to the code running within the page. The good news is that, although officially undocumented, the class that the .NET Framework actually uses to serialize and deserialize the view state is configured as a public type (as opposed to an internal type), and as such it can be called from user applications. The class is named LosFormatter.
The LosFormatter class has a simple programming interface made of only two publicly callable methods—Serialize and Deserialize. The Serialize method writes the final Base64 representation of the view state to a Stream or TextWriter object.
public void Serialize(Stream stream, object viewState); public void Serialize(TextWriter output, object viewState);
The Deserialize method builds a StateBag object from a stream, a TextReader object, or a plain Base64 string.
public object Deserialize(Stream stream); public object Deserialize(TextReader input); public object Deserialize(string input);
The LosFormatter class is the entry point in the view state internal mechanism. By using it, you can be sure everything will happen exactly as in the default case.
| Note |
The LosFormatter class features a read/write property named EnableViewStateMac, whose role is exactly that of enabling hashing on the Base64 string. The variable cannot be accessed because it's marked as internal, meaning that only classes in the same assembly can work with it. However, because we're simply plugging our code into the ASP.NET view state pipeline, we can control the machine authentication check by using the high-level tools discussed earlier. |
Creating a View-State-Less Page
The Page class provides a couple of protected virtual methods that the run time uses when it needs to deserialize or serialize the view state. The methods are named LoadPageStateFromPersistenceMedium and SavePageStateToPersistenceMedium.
protected virtual void SavePageStateToPersistenceMedium(object viewState); protected virtual object LoadPageStateFromPersistenceMedium();
If you override both methods, you can load and save view state information from and to anything other than a hidden field. By the way, you cannot override only one method. Because the methods are defined as protected members, the only way to redefine them is by creating a new class and making it inherit from Page. The following code just gives you an idea of the default behavior of LoadPageStateFromPersistenceMedium:
string m_viewState = Request.Form["__VIEWSTATE"]; LosFormatter m_formatter = new LosFormatter(); StateBag viewStateBag = m_formatter.Deserialize(m_viewState);
The structure of the page we're going to create is as follows:
public class AltViewStatePage : Page
{
protected override
object LoadPageStateFromPersistenceMedium()
{ ... }
protected override
void SavePageStateToPersistenceMedium(object viewState)
{ ... }
}
Saving the View State to a Web Server File
The tasks accomplished by the SavePageStateToPersistenceMedium method are easy to explain and understand. The method takes a string as an argument, opens the output stream, and calls into the LosFormatter serializer.
protected override
void SavePageStateToPersistenceMedium(object viewStateBag)
{
string file = GetFileName();
StreamWriter sw = new StreamWriter(file);
LosFormatter m_formatter = new LosFormatter();
m_formatter.Serialize(sw, viewStateBag);
sw.Close();
return;
}
How should we choose the name of the file to make sure that no conflicts arise? The view state is specific to a page request made within a particular session. So the session ID and the request URL are pieces of information that can be used to associate the request with the right file. Alternatively, you could give the view state file a randomly generated name and persist it in a custom hidden field within the page. Note that in this case you can't rely on the __VIEWSTATE hidden field because when overriding the methods, you alter the internal procedure that would have created it.
The GetFileName function in the preceding code gives the file a name according to the following pattern:
SessionID_URL.viewstate
Figure 14-13 (presented a bit later) shows one of these files created in a temporary directory. Note that for an ASP.NET application to create a local file, you must give the ASPNET account special permissions on a file or folder. I suggest creating a new subfolder to contain all the view state files. Deleting files for expired sessions can be a bit tricky, and a Windows NT service is probably the tool that works better.
Figure 14-13: View state files created on the server. The folder must grant write permissions to the ASPNET account.
Loading the View State from a Web Server File
In our implementation, the LoadPageStateFromPersistenceMedium method determines the name of the file to read from, extracts the Base64 string, and calls LosFormatter to deserialize.
protected override object LoadPageStateFromPersistenceMedium()
{
object viewStateBag;
string file = GetFileName();
StreamReader sr = new StreamReader(file);
string m_viewState = sr.ReadToEnd();
sr.Close();
LosFormatter m_formatter = new LosFormatter();
try {
viewStateBag = m_formatter.Deserialize(m_viewState);
}
catch {
throw new HttpException("The View State is invalid.");
}
return viewStateBag;
}
To take advantage of this feature to keep view state on the server, a page needs only to inherit from the AltViewStatePage class defined here. The following header will suffice:
<% @Page Language="C#" Inherits="ProAspNet.CS.Ch14.AltViewStatePage" %>
Figure 14-13 shows the view state files created in a temporary folder on the Web server machine.
The page shown in Figure 14-13 (simplepage.aspx) enables view state, but no hidden field is present in its client-side code.
The ASP NET Caching System
By definition, caching is the system's, or the application's, ability to save frequently used data to an intermediate storage medium. An intermediate storage medium is any support placed in between the application and its primary data source that lets you persist and retrieve data more quickly than with the primary data source. In a typical Web scenario, the intermediate storage medium is the Web server's memory, whereas the data source is the back-end data management system.
The ability to store in memory chunks of frequently accessed data can become a winning factor in the building of scalable Web applications. Instead of continuously connecting to the database server, locking records, and consuming one of the available connection channels, you can simply read the results needed from the local memory or maybe a disk file. This scenario delineates caching as an asset for any application. Well, not just any. Be aware that caching is rather a double-edged sword, and if abused or misused, it can easily morph into an insidious weakness. This typically happens when the quantity of memory-held information grows beyond a reasonable threshold. In a Web scenario, you should also distinguish between the session state and the application state and their actual size.
In general, caching as a tout-court solution does not necessarily guarantee better performance and is not quite a magic wand. However, if used in the context of an appropriate applicationwide strategy, it can result in a terrific boost for all kinds of applications—Web applications in particular.
In ASP.NET, caching comes in two independent but not exclusive flavors. One option is known as output page caching and consists of persisting the output of generated pages, thus having the system return the pages instead of processing them over and over again. We'll discuss this feature in the final part of the chapter "Caching ASP.NET Pages," paying special attention to the circumstances in which it is really useful. The second caching option takes place at the application level and is based on the new Cache object, which works side by side with the Session and Application objects. Let's start learning more about the Cache class.
The Cache Class
The Cache class is exposed by the System.Web.Caching namespace and represents a new entry in the set of tools that provide for state management in ASP.NET. The Cache class works like an applicationwide repository for data and objects, but this is the only aspect that it has in common with the HttpApplicationState class.
The Cache class is safe for multithreaded operations and does not require you to place locks on the repository prior to reading or writing. Next, what is stored in the Cache object is managed by the application, but under some circumstances it can automatically be invalidated, and then freed, by the system. Some items stored in the application cache can be bound to the timestamp of one or more files or directories. Thus, when incoming changes to disk break this link, cached items are marked as invalid and made no longer available to the application. The Cache object is equipped with a scavenging tool that periodically clears stored data that hasn't been used lately or has timed out.
An instance of the Cache class is created on a per-AppDomain basis and remains valid until that AppDomain is up and running. The current instance of the application's ASP.NET cache is returned by the Cache property of the HttpContext object or the Cache property of the Page object.
Cache and Other State Objects
As mentioned, the Cache class lives side by side with the HttpApplicationState class. The two classes, though, are quite different. Cache is a thread-safe object and does not require you to explicitly lock and unlock before access. All critical sections in the internal code are adequately protected using synchronization constructs. Another key difference with the HttpApplicationState class is that data stored in Cache doesn't necessarily live as long as the application does. The Cache object lets you associate a duration as well as a priority with any of the items you store.
Any cached item expires after the specified number of seconds, freeing up some memory. By setting priority, you can control the memory occupation and help the object control that on your behalf. Both Cache and HttpApplicationState are globally visible classes and span all active sessions. However, neither works in a Web farm or Web garden scenario; in general, they don't work outside the current AppDomain.
The Cache object is unique in its capability to automatically scavenge the memory and get rid of unused items. Aside from that, it provides the same dictionary-based and familiar programming interface as Application and Session. Unlike Session, the Cache class does not store data on a per-user basis. Furthermore, when the session state is managed in-process, all currently running sessions are stored as distinct items in the ASP.NET Cache.
| Note |
If you're looking for a global repository object that, like Session, works across a Web farm or Web garden architecture, your expectations can be frustrated. No such object exists in the .NET Framework, but building an ad hoc one can be much easier than you might think. Web services, for example, provide a good infrastructure to devise and build such a made-to-measure component. |
Properties of the Cache Class
The Cache class provides a couple of properties and a couple of public fields. The properties let you count and access the various items. The public fields are internal constants used to configure the expiration policy of the cache items. Table 14-11 lists and describes them all.
|
Property |
Description |
|---|---|
|
Count |
Gets the number of items stored in the cache |
|
Item |
Indexer property, provides access to the cache item identified by the specified key |
|
NoAbsoluteExpiration |
Static constant, indicates a given item will never expire |
|
NoSlidingExpiration |
Static constant, indicates sliding expiration is disabled for a given item |
The NoAbsoluteExpiration field is of the DateTime type and is set to the DateTime.MaxValue date—that is, the largest possible date defined in the .NET Framework. The NoSlidingExpiration field is of the TimeSpan type and is set to TimeSpan.Zero, meaning that sliding expiration is disabled. We'll say more about sliding expiration shortly. The Item property is a read/write property that can also be used to add new items to the cache. If the key specified as the argument of the Item property does not exist, a new entry is created. Otherwise, the existing entry is overwritten.
Cache["MyItem"] = value;
The data stored in the cache is generically considered to be of type object, whereas the key must be a case-sensitive string. When you insert a new item in the cache using the Item property, a number of default attributes are assumed. In particular, the item is given no expiration policy, no remove callback, and a normal priority. As a result, the item will stay in the cache indefinitely, until programmatically removed or until the application terminates. To specify any extra arguments and exercise closer control on the item, use the Insert method of the Cache class instead.
Methods of the Cache Class
The methods of the Cache class let you add, remove, and enumerate the items stored. As we'll see in a moment, insertion and removal of cached items can be quite a complex operation that involves the operating system as well. Methods of the Cache class are listed and described in Table 14-12.
Both the Add and Insert methods don't accept null values as the key or the value of an item to cache. If null values are used, an exception is thrown. If you're going to set the sliding expiration for an item, make sure it's not more than one year. Otherwise, an exception will be raised. Finally, bear in mind that you cannot set both sliding and absolute expirations on the same cached item.
|
Method |
Description |
|---|---|
|
Add |
Adds the specified item to the cache. It allows you to specify dependencies, expiration and priority policies, and a remove callback. The call fails if an item with the same key already exists. The method also returns an item of the object being added. |
|
Get |
Retrieves an item from the cache. The item is identified by key. The method returns null if no item with that key is found. |
|
GetEnumerator |
Returns a dictionary enumerator object to iterate through all the valid items stored in the cache. |
|
Insert |
Inserts the specified item into the cache. Insert provides several overloads and allows you to specify dependencies, expiration and priority policies, and a remove callback. The method is void and, unlike Add, overwrites an existing item having the same key as the item being inserted. |
|
Remove |
Removes the specified item from the cache. The item is identified by the key. The method returns the instance of the object being removed or null if no item with that key is found. |
| Note |
Add and Insert work in much the same way, but a couple of differences make it worthwhile to have both. Add fails (but no exception is raised) if the item already exists, whereas Insert overwrites the existing item. In addition, Add has just one signature, while Insert provides several different overloads. |
Working with the ASP NET Cache
An instance of the Cache object is associated with each running application and shares the associated application's lifetime. The cache holds references to data and proactively verifies their validity and expiration. When the system runs short of memory, the Cache object automatically removes some little-used items and frees valuable server resources. Each item when stored into the cache can be given special attributes that determine a priority and an expiration policy. All these are system-provided tools to help programmers control the scavenging mechanism of the ASP.NET cache.
Inserting New Items in the Cache
A cache item is characterized by a handful of attributes that can be specified as input arguments of both Add and Insert. In particular, an item stored in the ASP.NET Cache object can have the following properties:
- Key A case-sensitive string, represents the key used to store the item in the internal hash table the ASP.NET cache relies upon. If this value is null, an exception is thrown. If the key already exists, what happens depends on the particular method you're using: Add fails, while Insert just overwrites the existing item.
- Value A non-null value of type Object that references the information stored in the cache. The value is managed and returned as an Object and needs casting to become useful in the application context.
- Dependencies Object of type CacheDependency, tracks a physical dependency between the item being added to the cache and files, directories, or other objects in the application's cache. Whenever any of the files or the directories are modified, or the specified objects in the cache change, the newly added item is marked obsolete and automatically removed.
- Absolute Expiration Date A DateTime object that represents the absolute expiration date for the item being added. When this time arrives, the object is automatically removed from the cache. Items not subject to absolute expiration dates must use the NoAbsoluteExpiration constants representing the farthest allowable date. The absolute expiration date doesn't change after the item is used in either reading or writing.
- Sliding Expiration A TimeSpan object, represents a relative expiration period for the item being added. When you set the parameter to a non-null value, the expiration-date parameter is automatically set to the current time plus the sliding period. If you explicitly set the sliding expiration, you cannot set the absolute expiration date too. From the user's perspective, these are mutually exclusive parameters. If the item is accessed before its natural expiration time, the sliding period is automatically renewed.
- Priority A value picked out of the CacheItemPriority enumeration, denotes the priority of the item. It is a value ranging from Low to NotRemovable. The default level of priority is Normal. The priority level determines the importance of the item; items with a lower priority are removed first.
- Removal Callback If specified, indicates the function that the ASP.NET Cache object calls back when the item will be removed from the cache. In this way, applications can be notified when their own items are removed from the cache no matter what the reason is. As we mentioned earlier in the chapter, when the session state works in InProc mode, a removal callback function is used to fire the Session_OnEnd event. The delegate type used for this callback is CacheItemRemoveCallback.
There are basically three ways to add new items to the ASP.NET Cache object—the set accessor of Item property, the Add method, and the Insert method. The Item property allows you to indicate only the key and the value. The Add method has only one signature that includes all the aforementioned arguments. The Insert method is the most flexible of all options and provides the following four overloads:
public void Insert(string, object); public void Insert(string, object, CacheDependency); public void Insert(string, object, CacheDependency, DateTime, TimeSpan); public void Insert(string, object, CacheDependency, DateTime, TimeSpan, CacheItemPriority, CacheItemRemovedCallback);
The following code snippet shows the typical call that is performed under the hood when the Item set accessor is used:
Insert(key, value, null, Cache.NoAbsoluteExpiration, Cache.NoSlidingExpiration, CacheItemPriority.Normal, null);
If you use the Add method to insert an item whose key matches that of an existing item, no exception is raised, nothing happens, and the method returns null.
Removing Items from the Cache
All items marked with an expiration policy, or a dependency, are automatically removed from the cache when something happens in the system to invalidate them. To programmatically remove an item, on the other hand, you resort to the Remove method. Note that this method can remove any item, including items marked with the highest level of priority (NotRemovable). The following code snippet shows how to call the Remove method:
Cache.Remove("MyItem");
Normally, the method returns the object just removed from the cache. However, if the specified key is not found, the method fails and null is returned, but no exception is ever raised.
When items with an associated callback function are removed from the cache, a value from the CacheItemRemovedReason enumeration is passed on to the function to justify the operation. The enumeration includes the values listed in Table 14-13.
|
Reason |
Description |
|---|---|
|
DependencyChanged |
Removed because a file or a key dependency changed. |
|
Expired |
Removed because expired. |
|
Removed |
Programmatically removed from the cache using Remove. Note that a Removed event might also be fired if an existing item is replaced either through Insert or the Item property. |
|
Underused |
Removed by the system to free memory. |
If the item being removed is associated with a callback, the function is executed immediately after having removed the item.
Tracking Item Dependencies
Items added to the cache through the Add or Insert method can be linked to an array of files and directories as well as to an array of existing cache items. The link between the new item and its cache dependency is maintained using an instance of the CacheDependency class. The CacheDependency object can represent a single file or directory or an array of files and directories. In addition, it can also represent an array of cache keys—that is, keys of other items stored in the Cache. The dependency list of a cached item can also be composed of both files or directories and cache keys.
The CacheDependency class has quite a long list of constructors that provide for the possibilities listed in Table 14-14.
|
Constructor |
Description |
|---|---|
|
String |
A file path—that is, a URL to a file or a directory name |
|
String[] |
An array of file paths |
|
String, DateTime |
A file path monitored starting at a specified time |
|
String[], DateTime |
An array of file paths monitored starting at a specified time |
|
String[], String[] |
An array of file paths, and an array of cache keys |
|
String[], String[], CacheDependency |
An array of file paths, an array of cache keys, and a separate CacheDependency class |
|
String[], String[], DateTime |
An array of file paths and an array of cache keys monitored starting at a specified time |
|
String[], String[], CacheDependency, DateTime |
An array of file paths, an array of cache keys, and a separate instance of the CacheDependency class monitored starting at a specified time |
Any change in any of the monitored objects invalidates the current item. It's interesting to note that you can set a time to start monitoring for changes. By default, monitoring begins right after the item is stored in the cache. A CacheDependency object can be made dependent on another instance of the same class. In this case, any change detected on the items controlled by the separate object results in a broken dependency and the subsequent invalidation of the present item.
In the following code snippet, the item is associated with the timestamp of a file. The net effect is that any change made to the file that affects the timestamp invalidates the item, which will then be removed from the cache.
CacheDependency dep = new CacheDependency(filename); Cache.Insert(key, value, dep);
Bear in mind that the CacheDependency object needs to take file and directory names expressed through absolute file system paths.
| Note |
As of ASP.NET 1.1, the Cache object doesn't support dependencies set on database items. While Microsoft is considering this feature for a future version of ASP.NET, there's something you can do right now. You can define a trigger on the database and make it create or modify a file whenever executed. Next, you bind the cache item with this file. See the "Resources" section at the end of the chapter for a link to an MSDN article that demonstrates this technique. |
Defining a Removal Callback
Item removal is an event independent from the application's behavior and control. The difficulty with item removal is that because the application is oblivious to what has happened, it attempts to access the removed item later and gets only a null value back. To work around this issue, you can either check for the item's existence before access is attempted or, more effectively, register a removal callback and reload the item if it's invalidated. This approach makes particular sense if the cached item just represents the content of the tracked file.
The following sample page demonstrates how to read the contents of a Web server's file and cache it with a key named "MyData." The item is inserted with a removal callback. The callback simply re-reads and reloads the file if the removal reason is DependencyChanged. Otherwise, the item just deleted is restored.
<%@ Page Language="C#" %> <%@ Import Namespace="System.IO" %>
Contents of the cache
Note that the item removal callback is a piece of code defined by a user page but automatically run by the Cache object as soon as the removal event is fired. If the removal event has to do with a broken dependency, the Cache object will execute the callback as soon as the file change notification is detected. In other words, for the cache to be updated, you don't need to refresh the page. Of course, you need to refresh the page to see the changes (if there were any) reflected. To test the page just discussed, point the browser to the URL and modify the underlying file. Next, refresh the page, and if everything worked fine, you should see the updated contents of the dependency file.
| Note |
If you add an object to the Cache and make it dependent on a file, directory, or key that doesn't exist, the item is regularly cached and marked with a dependency as usual. If the file, directory, or key is created later, the dependency is broken and the cached item is invalidated. In other words, if the dependency item doesn't exist, it's virtually created with a null timestamp or empty content. |
To define a removal callback, you first declare a variable of type CacheRemovedItemCallback. Next, you instantiate this member with a new delegate object with the right signature.
CacheItemRemovedCallback onRemove; onRemove = new CacheItemRemovedCallback(ReloadItemRemoved);
The CacheDependency object is simply passed the onRemove delegate member, which carries out the actual function code for the Cache object to call back.
Setting the Item Priority
Each item in the cache is given a priority—that is, a value picked up from the CacheItemPriority enumeration. A priority is a value ranging from Low (lowest) to NotRemovable (highest) with the default set to Normal. The priority is supposed to determine the importance of the item for the Cache object. The higher the priority is, the greater the effort to keep the object in memory. Also in critical and stress conditions when the system resources are going dangerously down, priority will be used to determine which objects are kept in memory.
If you want to give a particular priority level to an item being added to the cache, you have to use either the Add or Insert method. The priority can be any value listed in Table 14-15.
|
Priority |
Value |
Description |
|---|---|---|
|
Low |
1 |
Items with this level of priority are the first items to be deleted from the cache as the server frees system memory. |
|
BelowNormal |
2 |
Intermediate level of priority between Normal and Low. |
|
Normal |
3 |
Default priority level, is assigned to all items and is added using the Item property. |
|
Default |
3 |
Same as Normal. |
|
AboveNormal |
4 |
Intermediate level of priority between Normal and High. |
|
High |
5 |
Items with this level of priority are the last items to be removed from the cache as the server frees memory. |
|
NotRemovable |
6 |
Items with this level of priority are never removed from the cache. Use this level with extreme care. |
The Cache object is designed with two goals in mind. First, it has to be an efficient and easy-to-program global repository of application data. Second, it has to be smart enough to detect when the system is running low on memory resources and to clear elements to free memory. This trait clearly differentiates the Cache object from HttpApplicationState, which instead maintains its objects until the end of the application (unless the application itself frees those items). The technique used to eliminate low-priority and seldom-used objects is known as scavenging.
Controlling Data Expiration
Priority and changed dependencies are two causes that could lead a cached item to be automatically garbage-collected from the Cache. Another possible cause for a premature removal from the Cache is infrequent use associated with an expiration policy. By default, all items added to the cache have no expiration date, neither absolute nor relative. If you add items by using either the Add or Insert method, you can choose between two mutually exclusive expiration policies: absolute and sliding expiration.
Absolute expiration is when a cached item is associated with a DateTime value and is removed from the cache as the specified time is reached. The DateTime.MaxValue field, and its more general alias NoAbsoluteExpiration, can be used to indicate the last date value supported by the .NET Framework and to subsequently indicate that the item will never expire.
Sliding expiration implements a sort of relative expiration policy. The idea is that the object expires after a certain interval. In this case, though, the interval is automatically renewed after each access to the item. Sliding expiration is rendered through a TimeSpan object—a type that in the .NET Framework represents an interval of time. The TimeSpan.Zero field represents the empty interval and is also the value associated with the NoSlidingExpiration static field on the Cache class. When you cache an item with a sliding expiration of 10 minutes, you use the following code:
Insert(key, value, null, Cache.NoAbsoluteExpiration, TimeSpan.FromMinutes(10), CacheItemPriority.Normal, null);
Internally, the item is cached with an absolute expiration date given by the current time plus the specified TimeSpan value. In light of this, the preceding code could have been rewritten as follows:
Insert(key, value, null, DateTime.Now.AddMinutes(10), Cache.NoSlidingExpiration, CacheItemPriority.Normal, null);
However, a subtle difference still exists between the two code snippets. In the former case—that is, when sliding expiration is explicitly turned on—each access to the item resets the absolute expiration date to the time of the last access plus the time span. In the latter case, because sliding expiration is explicitly turned off, any access to the item doesn't change the absolute expiration time.
Statistics About Memory Usage
Immediately after initialization, the Cache collects statistical information about the memory in the system and the current status of the system resources. Next, it registers a timer to invoke a callback function at one-second intervals. The callback function periodically updates and reviews the memory statistics and, if needed, activates the scavenging module. Memory statistics are collected using a bunch of Win32 API functions, including the GlobalMemoryStatusEx API used to obtain information about the system's current usage of both physical and virtual memory.
The Cache object classifies the status of the system resources in terms of low and high pressure. Each value corresponds to a different percentage of occupied memory. Typically, low pressure is in the range of 15 percent to 40 percent, while high pressure is measured from 45 percent to 65 percent of memory occupation. When the memory pressure exceeds the guard level, seldom-used objects are the first to be removed according to their priority.
Building a Cache Viewer
Enumerating the items in the Cache is as easy as walking through a collection of objects using an ad hoc enumerator. Unlike Session and Application objects, though, there's no graphical way to see the contents of the Cache, not even when tracing is turned on. In this section, we'll build a simple user control that reads the items in the cache and displays them in a grid. We covered user controls in Chapter 10. You register the CacheViewer user control with your application by using the following code:
<%@ Register TagPrefix="expo" TagName="CacheViewer" src="books/2/371/1/html/2/CacheViewer.ascx" %>
To embed an instance of the control, you resort to the following tag in the body of the ASP.NET page:
The control incorporates a DataGrid control and exposes one method named Refresh to populate the internal grid with an information readout of the Cache.
Enumerating Items in the Cache
The CacheViewer control creates and displays a DataTable with two columns—one for the key and one for the value of the item stored. The value is rendered using the ToString method, meaning that the string and numbers will be loyally rendered but objects will typically be rendered through their class name. The following code shows the implementation of the Refresh method:
public void Refresh() {
DataTable dt = GetCacheContents();
grid.DataSource = dt;
grid.DataBind();
}
private DataTable GetCacheContents() {
DataTable dt = CreateDataTable();
foreach(DictionaryEntry elem in Cache) {
AddItemToTable(dt, elem);
}
return dt;
}
private DataTable CreateDataTable() {
DataTable dt = new DataTable();
dt.Columns.Add("Key", typeof(string));
dt.Columns.Add("Value", typeof(string));
return dt;
}
private void AddItemToTable(DataTable dt, DictionaryEntry elem) {
DataRow row = dt.NewRow();
row["Key"] = elem.Key.ToString();
row["Value"] = elem.Value.ToString();
dt.Rows.Add(row);
}
Figure 14-14 shows a typical output of the CacheViewer control.
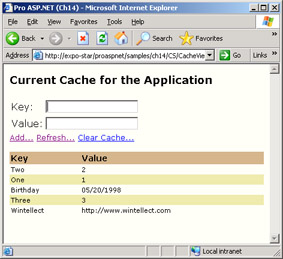
Figure 14-14: The content of the Cache object in a sample application.
The Cache class is a collection class that is instantiated within the HttpRuntime object. More exactly, an internal class named CacheInternal is used and its content is partitioned in public and private items. The set of public items is exposed to user applications through the Cache object. The rest of the HTTP runtime cache—the private items—contains system information, including objects that represent the state of all active sessions. Private items are inaccessible from user applications because of the protection level.
Clearing the Cache
The .NET Framework provides no method on the Cache class to programmatically clear all the content. The following code snippet shows how to build one:
public void Clear() {
foreach(DictionaryEntry elem in Cache) {
string s = elem.Key.ToString();
Cache.Remove(s);
}
}
The CacheViewer control provides a Clear method that removes all public items in the cache.
| Important |
The grid created by the CacheViewer control contains only a couple of columns because there's no other way to retrieve the additional information about an item in the cache. In particular, there's no way to know about the expiration policy, dependency, or removal callback. When you enumerate the contents of the Cache object, a generic DictionaryEntry object is returned with no property or method pointing to more specific information. Also note that because the Cache object stores data internally using a hash table, the enumerator returns contained items in an apparently weird order, neither alphabetical nor time-based. The order in which items are returned, instead, is based on the internal hash code used to index items. |
Caching ASP NET Pages
Output caching is an ASP.NET feature that allows you to store dynamic page responses so that next requests can be satisfied without executing the page but simply by returning the cached output. Output caching can take place at two levels—entire pages or portions of the page. In the latter case, the portion of the page to be cached is an embedded user control. Page caching is smart enough to let you save distinct output based on the requesting URL, query string, or form POST parameters, and even custom strings. Output caching can be configured either declaratively through the @OutputCache directive or programmatically through an API built around the HttpCachePolicy class.
The @OutputCache Directive
The @OutputCache directive can be used with both ASP.NET pages and user controls to declaratively control the caching capabilities of the resource. The directive accepts a handful of attributes. A couple of these attributes—Duration and VaryByParam—are mandatory. The Duration attribute indicates in seconds how long the system should cache the page output. The VaryByParam attribute allows you to vary the cached output depending on the GET query string or form POST parameters. The following declaration will cache the page for one minute regardless of any GET or POST parameters:
<%@ OutputCache Duration="60" VaryByParam="None" %>
The @OutputCache directive is made up of six attributes that indicate the location of the cache, its duration, and the arguments to use to vary page caching. The list of supported attributes is shown in Table 14-16.
|
Attribute |
Description |
|---|---|
|
Duration |
The time, in seconds, that the page or user control is cached. |
|
Location |
Specifies a valid location to store the output of a page. The attribute takes its value from the OutputCacheLocation enumeration. The default is Any. |
|
VaryByCustom |
A semicolon-separated list of strings that lets you maintain distinct cached copies of the page based on the browser type or user-defined strings. |
|
VaryByHeader |
A semicolon-separated list of HTTP headers. |
|
VaryByParam |
A semicolon-separated list of strings representing query string values sent with GET method attributes, or parameters sent using the POST method. |
|
VaryByControl |
A semicolon-separated list of strings representing fully qualified names of properties on a user control. Only valid for caching user controls; don't use it with ASP.NET pages. |
Note that the VaryByParam attribute is mandatory. If you omit it, a runtime exception is always thrown. However, if you don't need to vary by parameters, set the attribute to None. The empty string is not an acceptable value for the VaryByParam attribute.
Choosing a Duration for the Output Cache
When the output caching service is active on a page—that is, the @OutputCache directive has been specified—the Duration attribute indicates the seconds that the ASP.NET system will maintain an HTML-compiled version of the page. Next, requests for the same page, or for an existing parameterized version of the page, will be serviced while bypassing the page handler.
The request is still assigned to an HttpApplication object and begins the normal processing by firing the BeginRequest event. The ASP.NET caching system includes an HTTP module—the OutputCacheModule—that registers its own handlers for the two application-level events related to output caching—ResolveRequestCache and UpdateRequestCache. In particular, the ResolveRequestCache event handler is used to short-circuit the processing of requests that have been cached. When the page is being generated, the output cache module grabs the output of the pages marked with the @OutputCache directive and stores it internally for further use.
Setting the Duration attribute on a page sets an expiration policy for the HTTP response generated by the ASP.NET runtime. The output is cached by the module for exactly the specified number of seconds. In the meantime, all the incoming requests that hit one of the cached pages are serviced by the module rather than by the ASP.NET pipeline.
A fair value for the Duration attribute depends on the application, but it normally doesn't exceed 60 seconds and works great, especially if the page doesn't need to be updated frequently.
| Note |
In ASP.NET 1.1, the output page-caching mechanism still requires that a new HTTP application be created, although for only a short time. With Microsoft Windows Server 2003 and the IIS 6.0 process model (discussed in Chapter 2), the output caching is integrated in the Web server, resulting in much better performance and responsiveness. |
Choosing a Location for the Output Cache
The output cache can be located in various places, either on the client that originated the request or the server. It can also be located on an intermediate proxy server. The various options are listed in Table 14-17.
|
Location |
Cache-Control |
Description |
|---|---|---|
|
Any |
Public |
The HTTP header Expires is set accordingly to the duration set in the @OutputCache directive. A new item is placed in the ASP.NET Cache object representing the output of the page. The type of this object is CachedRawResponse. |
|
Client |
Private |
The HTTP header Expires is set accordingly to the duration set in the @OutputCache directive. No item is created in the ASP.NET Cache object. |
|
DownStream |
Public |
The HTTP header Expires is set accordingly to the duration set in the @OutputCache directive. No item is created in the ASP.NET Cache object. |
|
None |
No-Cache |
The HTTP header Expires is not defined. The Pragma header is set to No-Cache. No item is created in the ASP.NET Cache object. |
|
Server |
No-Cache |
The HTTP header Expires is not defined. The Pragma header is set to No-Cache. A new CachedRawResponse item is placed in the ASP.NET Cache object to represent the output of the page. |
Most browsers and intermediate proxies exploit any expiration information the Web server embeds in the HTML page being generated. A few HTTP 1.1 headers relate to page caching; they are Expires and Cache-Control.
In particular, the Expires HTTP header is used to specify the time when a particular page on the server should be updated by the client. Until that time, any new request the browser receives for the resource is served using the local, client-side cache and no server round-trip is ever made. When specified and not set to No-Cache, the HTTP 1.1 Cache-Control typically takes values such as public or private. A value of public means that both the browser and the proxy servers can cache the page. A value of private prevents proxy servers from caching the page; only the browser will cache the page. The Cache-Control is part of the HTTP 1.1 specification and is supported only by Internet Explorer 5.5 and higher.
If you look at the HTTP headers generated by ASP.NET when output caching is enabled, you'll notice that sometimes the Pragma header is used—in particular, when the location is set to Server. In this case, the header is assigned a value of No-Cache, meaning that client-side caching is totally disabled both on the browser side and the proxy side. As a result, any access to the page is resolved through a connection. To be precise, the Pragma header set to No-Cache disables caching only over HTTPS channels. If used over nonsecure channels, the page is actually cached but marked as expired.
Let's examine the client and Web server caching configuration when each of the feasible locations is used:
- Any Default option, means that the page can be cached everywhere, including in the browser, the server, and any proxies along the way. The Expires header is set to the page's absolute expiration time as determined by the Duration attribute; the Cache-Control is set to Public, meaning that the proxies can cache if they want and need to. On the Web server, a new item is placed in the Cache object with the HTML output of the page. In summary, with this option the page output is cached everywhere. As a result, if the page is accessed through the browser before it expires, no roundtrip is ever made. If, in the same timeframe, the page is refreshed—meaning that server-side access is made anyway—the overhead is minimal, the request is short-circuited by the output cache module, and no full request processing takes place.
- Client The page is cached only by the browser because the Cache-Control header is set to Private. Neither proxies nor ASP.NET stores a copy of it. The Expires header is set accordingly to the value of the Duration attribute.
- DownStream The page can be cached both on the client and in memory of any intermediate proxy. The Expires header is set accordingly to the value of the Duration attribute, and no copy of the page output is maintained by ASP.NET.
- None Page output caching is disabled both on the server and on the client. No Expires HTTP header is generated, and both the Cache-Control and Pragma headers are set to No-Cache.
- Server The page output is exclusively cached on the server and its raw response stored in the Cache object. The client-side caching is disabled. No Expires header is created and both the Cache-Control and Pragma headers are set to No-Cache.
- ServerAndClient The output cache can be stored only at the origin server or at the requesting client. Proxy servers are not allowed to cache the response.
Note The ASP.NET output caching API affects caching both on the client and the Web server. You can control the caching mechanism by using a bunch of ASP.NET attributes such as Location and Duration. Note, though, that the Location attribute is not supported for @OutputCache directives included in user controls.
The HttpCachePolicy Class
The HttpCachePolicy class represents a programming interface alternative to using the @OutputCache directive. It provides direct methods to set cache-related HTTP headers such Expires and Cache-Control, which you could control to some extent anyway by using the interface of the HttpResponse object.
Properties of the HttpCachePolicy Class
Table 14-18 shows the properties of the HttpCachePolicy class.
|
Property |
Description` |
|---|---|
|
VaryByHeaders |
Gets an object of type HttpCacheVaryByHeaders, representing the list of all HTTP headers that will be used to vary cache output. |
|
VaryByParams |
Gets an object of type HttpCacheVaryByParams, representing the list of parameters received by a GET or POST request that affects caching. |
When a cached page has several headers or parameters, a separate version of the page is available for each HTTP header type or parameter name.
Methods of the HttpCachePolicy Class
Table 14-19 shows the methods of the HttpCachePolicy class.
|
Method |
Description |
|---|---|
|
AddValidationCallback |
Registers a callback function to be used to validate the page output in the server cache before returning it. |
|
AppendCacheExtension |
Appends the specified text to the Cache-Control HTTP header. The existing text is not overwritten. |
|
SetCacheability |
Sets the Cache-Control HTTP header to any of the following values: NoCache, Private, Public, Server, ServerAndNoCache, ServerAndPrivate. The allowable values are taken from the HttpCacheability enumeration type. |
|
SetETag |
Sets the ETag header to the specified string. The ETag header is a unique identifier for a specific version of a document. |
|
SetETagFromFileDependencies |
Sets the ETag header to a string built by combining and then hashing the last modified date of all the files upon which the page is dependent. |
|
SetExpires |
Sets the Expires header to an absolute date and time. |
|
SetLastModified |
Sets the Last-Modified HTTP header to a particular date and time. |
|
SetLastModifiedFromFileDependencies |
Sets the Last-Modified HTTP header to the most recent timestamps of the files upon which the page is dependent. |
|
SetMaxAge |
Sets the max-age attribute on the Cache-Control header based on the specified TimeSpan value. The sliding period cannot exceed one year. |
|
SetNoServerCaching |
Disables server output caching for the current response. |
|
SetNoStore |
Sets the Cache-Control: no-store directive. |
|
SetNoTransforms |
Sets the Cache-Control: no-transform directive. |
|
SetProxyMaxAge |
Sets the Cache-Control: s-maxage header based on the specified TimeSpan. |
|
SetRevalidation |
Sets the Cache-Control header to either the must-revalidate or proxy-revalidate directive. |
|
SetSlidingExpiration |
Sets cache expiration to sliding. When cache expiration is set to sliding, the Cache-Control header is renewed at each response. |
|
SetValidUntilExpires |
When SetValidUntilExpires is set to true, ASP.NET ignores the cache invalidation header sent by the browser. The page remains in the cache until it expires. |
|
SetVaryByCustom |
Sets the Vary HTTP header to the specified text string. |
Most methods of the HttpCachePolicy class let you control the values of some HTTP headers that relate to the browser cache. The AddValidationCallback method, on the other hand, provides a mechanism to programmatically check the validity of page output in the server cache before it is returned from the cache.
Server Cache-Validation Callback
Before the response is served from the ASP.NET cache, all registered handlers are given a chance to verify the validity of the cached page. If at least one handler marks the cached page as invalid, the entry is removed from the cache and the request is served as if it were never cached. The signature of the callback function looks like this:
public delegate void HttpCacheValidateHandler( HttpContext context, object data, ref HttpValidationStatus validationStatus );
The first argument denotes the context of the current request, whereas the second argument is any user-defined data the application needs to pass to the handler. Finally, the third argument is a reference to a value from the HttpValidationStatus enumeration. The callback sets this value to indicate the result of the validation. Acceptable values are IgnoreThisRequest, Invalid, and Valid. In the case of IgnoreThisRequest, the cached resource is not invalidated but the request is served as if no response was ever cached. If the return value is Invalid, the cached page is not used and gets invalidated. Finally, if the return value is Valid, the cached response is used to serve the request.
Caching Multiple Versions of a Page
Depending on the application context from which a certain page is invoked, the page might generate different results. The same page can be called to operate with different parameters, can be configured using different HTTP headers, can produce different output based on the requesting browser, and so forth.
ASP.NET allows you to cache multiple versions of a page response; you can distinguish versions by GET and POST parameters, HTTP headers, browser type, custom strings, and control properties.
Vary by Parameters
To vary output caching by parameters, you can use either the VaryByParam attribute of the @OutputCache directive or the VaryByParams property on the HttpCachePolicy class. If you proceed declaratively, use the following syntax:
<% @OutputCache Duration="60" VaryByParam="employeeID" %>
Note that the VaryByParam attribute is mandatory; if you don't want to specify a parameter to vary cached content, set the value to None. If you want to vary the output by all parameters, set the attribute to *. When the VaryByParam attribute is set to multiple parameters, the output cache contains a different version of the requested document for each specified parameter. Multiple parameters are separated by a semicolon. Valid parameters to use are items specified on the GET query string or parameters set in the body of a POST command.
If you want to use the HttpCachePolicy class, first set the expiration and the cacheability of the page using the SetExpires and SetCacheability methods. Next, set the VaryByParams property as shown here:
Response.Cache.VaryByParams["employeeid;lastname"] = true;
This code snippet shows how to vary page output based on the employee ID and the last name properties. Note that the Cache property on the HttpResponse class is just an instance of the HttpCachePolicy type.
Vary by Headers
The @OutputCache directive VaryByHeader attribute and the HttpCachePolicy VaryByHeaders property allow you to cache multiple versions of a page, according to the value of one or more HTTP headers that you specify.
If you want to cache pages by multiple headers, include a semicolon-delimited list of header names. If you want to cache a different version of the page for each different header value, set the VaryByHeader attribute to an asterisk *. For example, the following declaration caches for one minute pages based on the language accepted by the browser. Each language will have a different cached copy of the page output.
<%@ OutputCache Duration="60" VaryByParam="None" VaryByHeader="Accept-Language" %>
If you opt for a programmatic approach, here's the code to use that leverages the VaryByHeaders property of the HttpCachePolicy class:
Response.Cache.VaryByHeaders["Accept-Language"] = true;
| Note |
The VaryByHeader attribute enables caching items in all HTTP 1.1 caches, not just the ASP.NET cache. Whether the setting also applies to the browser cache depends on the value of the Location attribute. |
If you want to vary the pages in the cache by all HTTP header names, use the VaryByUnspecifiedParameters method of the HttpCacheVaryByHeaders class. It's the same as using the asterisk with the VaryByHeader attribute. As a final note, consider that the VaryByHeader attribute is not supported for @OutputCache directives defined in user controls.
Vary by Custom Strings
The VaryByCustom attribute in the @OutputCache directive allows you to vary the versions of page output by the type of browser that requests the page. To obtain this information, you simply give the attribute the special value of browser.
<%@ OutputCache Duration="60" VaryByParam="None" VaryByCustom="browser" %>
Browser name and major version number are the pieces of information used to build a custom string to vary cached output by. In particular, the string is what returns the Type property of the HttpBrowserCapabilities object. You use the SetVaryByCustom method on the HttpCachePolicy class if you don't like the declarative approach.
Response.Cache.SetVaryByCustom("browser");
You can set both the VaryByCustom attribute and the SetVaryByCustom method to work on custom strings. In this case, you need to override the GetVaryByCustomString method of the HttpApplication object and make it return the actual vary string. The following pseudocode represents the standard implementation of GetVaryByCustomString:
string GetVaryByCustomString(HttpContext context, string custom) {
if (custom == "browser")
return context.Request.Browser.Type;
return null;
}
You should make the method return a non-null string when the custom argument matches the string passed to the VaryByCustom attribute or the SetVaryByCustom method. Note that the string returned by the GetVaryByCustomString method must refer to some easily identifiable property of the browser or the application—for example, the minor version number or the title of the page.
Caching Portions of ASP NET Pages
The capability of caching the output of Web pages adds a lot of power to your programming arsenal, but sometimes caching the entire content of a page is not possible or is just impractical. Some pages, in fact, are made of pieces with radically different features as far as cacheability is concerned. In these situations, being able to cache portions of a page is an incredible added value. Enter user controls.
Caching the Output of User Controls
As we saw in Chapter 10, user controls are good at a number of things, including caching portions of Web pages. Once you have identified a section of a page that is both heavy to compute and not subject to frequent updates, you build a user control and make it produce that output. The user control is a sort of embedded page and, as such, shares some of the directives of the Web page. One shared directive is just @OutputCache. As a result, when you have a page with multiple user controls, you can control page caching on a per-control basis rather than a per-page basis.
To make a user control cacheable, you declare the @OutputCache attribute by using almost the same set of attributes we discussed earlier for pages. For example, the following code snippet caches the output of the control that embeds it for one minute:
<% @OutputCache Duration="60" VaryByParam="None" %>
A few of the @OutputCache attributes I listed in Table 14-16 are not supported when the directive works within a user control. For example, the Location attribute is not supported because all controls in the page share the same location. So if you need to specify the cache location, do that at the page level and for all embedded controls. The same holds true for the VaryByHeader attribute.
The output of a user control can vary by custom strings and by parameters. More often, though, you'll want to vary the output of a control by property values. In this case, use the new VaryByControl attribute.
Vary by Controls
The VaryByControl attribute allows you to vary the cache for each specified user control property. The property is mandatory unless the VaryByParam attribute has been specified. You can indicate both VaryByParam and VaryByControl, but at least one of them is needed.
<%@ OutputCache Duration="60" VaryByControl="Text" %>
This directive caches a different copy of the control output based on the different values of the Text property.
Implementing Partial Caching
The following page demonstrates two user controls whose output varies by the value of the Text property. The ASPX page hosts two instances of the user control with different values in the Text property, and two different copies of the output will be stored in the output cache.
<%@ Page Language="C#" %> <%@ Register TagPrefix="e" TagName="UserControl" src="books/2/371/1/html/2/UserControl.ascx" %>
The user control contains a label set with the value of the Text property.
<% @Control Language="C#" %> <% @OutputCache Duration="10" VaryByControl="Text" %>
<%=Text%>
Cached at <%=DateTime.Now.ToString()%>
Figure 14-15 shows the output of the page. Notice the timestamps of the page and the controls.
Figure 14-15: An ASP.NET page with two user controls implementing partial caching. The page is not cached while the two controls have a cache duration of 10 seconds.
The output text cached for each instance of the control is still stored in the ASP.NET Cache object, in the private portion.
| Note |
If you plan to cache user controls—that is, you're trying for partial caching—you probably don't want to cache the entire page. However, a good question to ask is: what happens if user controls are cached within a cacheable page? In this case, the page @OutputCache wins. Both the page and the controls are cached individually, and the ASP.NET Cache object contains both the page's raw response and the control's HTML responses. However, if the duration is different, the controls are refreshed only when the page needs to be refreshed. A cacheable user control can be embedded both in a cacheable page and in a wrapper cacheable user control. |
The PartialCachingControl Class
When a PartialCachingControl cacheable user control is used within a Web Forms page, the base of the control being instantiated is PartialCachingControl. A user control is made cacheable in either of two ways: by using the @OutputCache directive or the PartialCaching attribute. The PartialCaching attribute—an instance of the PartialCachingAttribute class—is especially useful in code-behind user controls. You use the attribute as follows:
[PartialCaching(60)]
You can declare this attribute in a class derived from the UserControl class to specify settings for the user control output cache. Note that the PartialCaching attribute allows you to specify the duration only in seconds.
Whatever protocol is used to create an instance of the user control, an instance of the PartialCachingControl class is returned as long as the control is declared cacheable. The class has nearly the same programming interface as UserControl. The difference is in a couple of extra properties—Dependency and CachedControl. The Dependency property manages the instance of the CacheDependency class associated with the cached user control output. The property allows you to remove user control output from the output cache when a file or key dependency changes. The CachedControl property returns an instance of the control. However, if the output of the control is retrieved from the cache, no instance of the control is ever created and the property returns null.
| Caution |
If you're building a page made of cacheable controls, you should pay a lot of attention to the code that manages the control ID. Note especially that if the page is using a cached copy of the control output, no control is ever instantiated and subsequently any access to the control ID results in a null object reference. |
Conclusion
State management is a hot topic for all real-world Web applications. Setting up an effective and efficient solution for state management is often the difference between an application being scalable or nonscalable. In ASP, state management was offered through a couple of objects—Application and Session. The Application object is a global repository of data, whereas the Session object works on a per-session basis. ASP.NET provides a richer set of tools, including the Cache and ViewState objects. In addition, the architecture of the session state object has been revolutionized and made flexible as never before. You can store session data in the memory of the ASP.NET worker process as well as in external processes, and even in a SQL Server table. In spite of the radically different options, the programming interface is nearly identical. More importantly, the ASP.NET session state can be persisted in a Web farm or Web garden scenario as well.
In the internal implementation of the ASP.NET Session object, a key role is played by the Cache object. It is a global, application-specific repository of data with advanced capabilities such as priority, file dependencies, removal callbacks, and expiration dates. In addition, the Cache object periodically monitors memory consumption. When the memory pressure exceeds a certain threshold, a sort of internal garbage collector module is run to remove seldom-used items. When the session state is held in the ASP.NET worker process, the physical container for the session state is just the Cache object.
The Cache object is also key to the output caching mechanism—another powerful feature of ASP.NET. The typical situation in which output caching is great is when you know that many users will be accessing the same page or the same range of pages in a short time. In this case, you might decide to cache the HTML output of the page to save time by not reworking the page for all the requests that arrive in the fixed period. The tradeoff is between memory occupation and page responsiveness. The caching machinery can be adapted to work also on the client exploiting HTTP headers such as Cache-Control and Expires.
If caching the entire page is impractical, you can always opt for partial caching. Partial caching leverages the concept of user controls—that is, small, nested pages that inherit several features of the page. In particular, user controls can be cached individually based on the browser, GET and POST parameters, and the value of a particular set of properties.
As we thoroughly discussed in Chapter 4, an ASP.NET page is designed around a single server-side form with an automatic scheme for persisting the context of the specific page request. The call context is normally stored in the ViewState structure, namely an encoded collection stored in a hidden field and transmitted back and forth between the browser and the Web server. Having the view state implemented in the default way might pose some performance and security issues. In this chapter, we also discussed how to persist the view state on the server, thus significantly reducing both the security concerns and improving the usage of the bandwidth. Security, a topic in the software industry that can never be discussed too much, will be the subject of the next chapter.
Resources
- Supporting Database Cache Dependencies in ASP.NET (http://msdn.microsoft.com/msdnmag/issues/03/04/WickedCode/default.aspx)
- ASP.NET: Nine Options for Managing Persistent User State in Your ASP.NET Application (http://msdn.microsoft.com/msdnmag/issues/03/04/ASPNETUserState/default.aspx)
- ViewState: All You Wanted to Know (http://www.aspalliance.com/PaulWilson/Articles/?id=7)
- How to Share Session State Between Classic ASP and ASP.NET (http://msdn.microsoft.com/library/en-us/dnaspp/html/converttoaspnet.asp)
- Developing Microsoft ASP.NET Server Controls and Components, by Nikhil Kothari and Vandana Datye (Microsoft Press, 2002)
Part I - Building an ASP.NET Page
Part II - Adding Data in an ASP.NET Site
- The ADO.NET Object Model
- Creating Bindable Grids of Data
- Paging Through Data Sources
- Real-World Data Access
Part III - ASP.NET Controls
Part IV - ASP.NET Application Essentials
- Configuration and Deployment
- The HTTP Request Context
- ASP.NET State Management
- ASP.NET Security
- Working with the File System
- Working with Web Services
Part V - Custom ASP.NET Controls
- Extending Existing ASP.NET Controls
- Creating New ASP.NET Controls
- Data-Bound and Templated Controls
- Design-Time Support for Custom Controls
Part VI - Advanced Topics
Index
EAN: 2147483647
Pages: 209
- Seeing Services Through Your Customers Eyes-Becoming a customer-centered organization
- Success Story #2 Bank One Bigger… Now Better
- Success Story #3 Fort Wayne, Indiana From 0 to 60 in nothing flat
- Success Story #4 Stanford Hospital and Clinics At the forefront of the quality revolution
- Designing World-Class Services (Design for Lean Six Sigma)
