The Basics of XQuery
| | ||
| | ||
| | ||
There are a number of syntax options to discuss here. The most significant factor to remember about XQuery is that it is not written in XML. However, XQuery queries can be embedded with XSL style sheets.
Executing XQuery Queries
This is an example XQuery coded command:
for $i in doc("demographics.xml")/demographics/region/country/city where $i/population>10000000 order by $i/name return $i/name Now you might ask questions like this: How does the preceding code work? What tool does it run in? How does one execute it? The answer is not in your browser. Remember XQuery is not written in XML. XQuery is written as a W3C specification, which implies a guideline. Thus, any vendor can use the specification to construct a program to execute XQuery queries, such as the for loop shown in the preceding code. Your Internet Explorer browser (or otherwise ) will not simply execute the preceding XQuery code example. The preceding example is not XML code and thus not universally interpreted by a standard issue Internet browser program such as Internet Explorer or Netscape.
So, before you go any further with describing XQuery, you can download and install a piece of software called Saxon. You can do this if you wish to follow along with examples as you read through this chapter. It is not essential that you perform the download. I will also be using an Oracle Database proprietary product called XML DB and various other Oracle Database tools and commands. All of these Oracle tools will allow execution of XQuery coded commands, along with a lot of other functions within the Oracle XML DB software.
Using Saxon
Saxon is a program that allows you to execute XQuery queries like the one shown in the previous section. You can download Saxon software from the following URL:
http://saxon.sourceforge.net The best option is probably the latest version. However, the version you find when reading this book might not be the version I found when writing it. So be aware that there might be differences. Saxon version 8.7.1 was used to write this book.
In order to use Saxon you need to have a Java virtual machine (JVM) installed on your computer to install the Java version. Execute the following command in a shell to check which version of Java you have installed, if any:
java version If nothing appears, you need to download an appropriate version of Java. Java can be downloaded at the following URL:
http://www.java.sun.com When Java is installed, typing a command such as the following will give an indication as to Saxon status. This depends on where the Saxon JAR files are installed:
java -jar "c:\program files\saxon\saxon8.jar" You should get a list of options for Saxon, something like that shown in Figure 11-1.
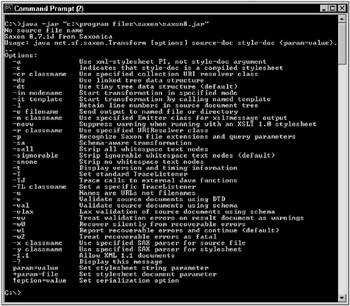
Figure 11-1: Executing the Saxon XQuery command processor
Now you can execute a query using a command something like the following, assuming all appropriate PATH and CLASSPATH settings are appropriate:
java -jar "c:\program files\saxon\saxon8.jar" test.xml test.xsl I opted to use the .NET version of Saxon. You will need the .NET Framework version 1.1 to accomplish this. .NET can be downloaded from Microsoft at the following URL (you will have to search for .NET Framework version 1.1):
http://www.microsoft.com Now go to the sourceforge website and download the .NET version of Saxon found at the following URL:
http://saxon.sourceforge.net/ Then download the latest .NET version of Saxon software. You will find instructions for installation in the documentation included with the download. The easiest method is as follows . Download the Zip file, in my case called saxonb8-7-1n.zip, and unzip the files contents into a directory called c:\saxon (on a Windows computer). Then set the SAXON_HOME variable to c:\saxon and add the c:\saxon\bin directory to your path (the PATH environment variable).
The documentation for Saxon 8.7 (the version I downloaded) is included in a file called saxon-resources8-7-1.zip. Included in that Zip file is a large quantity of samples. The easiest way to make sure you have installed the software properly is to use the examples suggested in the installation documentation. Saxon is a command-line tool. In other words, it is executed in a DOS shell window on a Windows computer.
In my case, I navigate to the c:\saxon directory and execute these two examples, as included in the documentation. This first example gives a rather long-winded result for a graphic but it does function:
bin\Transform -t samples\data\books.xml samples\styles\books.xsl This second example gives a nice short example, as shown in Figure 11-2:
bin\Query -t -s samples\data\books.xml samples\query\books-to-html.xq 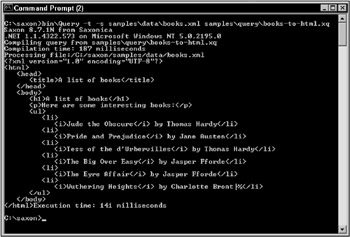
Figure 11-2: Executing the Saxon .NET post-installation samples
Embedding XQuery Code into HTML
As demonstrated by Figure 11-2, the direct output in the shell contains HTML commands. How is this? XQuery commands can be embedded into HTML files. So lets demonstrate this by using an example not found in XQuery documentation. The following XQuery will find all cities in my entire demographics.xml file and then reorder them in reverse order of population so that the largest cities are returned first:
xquery version "1.0"; <HTML> <HEAD><TITLE>Demographics</TITLE></HEAD> <BODY> <OL> { for $n in //city[population>0] order by $n/population descending return <LI><I> { string($n/name) } </I> has { string($n/population) } people</LI> } </OL> </BODY></HTML> Note in the preceding script how the XQuery code is embedded into HTML code by using the curly braces for example, <I>{ string($n/name) }</I> . There is also the xquery version command at the beginning of the script. Also be aware of the multiple layers of embedding using the curly braces, which is actually a little confusing, particularly on the line containing the return clause: The HTML tags <LI><I> change back to HTML such that the following XQuery string($n/name) command must once again be enclosed in curly braces. Thats the way it works.
Execute the preceding XQuery using the following Saxon command:
Query -s demographics.xml fig1103.xquery > fig1103.html The HTML file is produced from the Saxon processing of the XQuery command by redirecting the Saxon output to an HTML file, rather than the shell display. I have also removed the ˆ t (timing) option, which was in the Saxon examples.
This is a partial result of the preceding XQuery:
<?xml version="1.0" encoding="UTF-8"?> <HTML> <HEAD> <TITLE>Demographics</TITLE> </HEAD> <BODY> <OL> <LI> <I>Tokyo</I> has 34000000 people</LI> <LI> <I>Mexico City</I> has 22350000 people</LI> <LI> <I>Seoul</I> has 22050000 people</LI> <LI> <I>New York</I> has 21800000 people</LI> <LI> <I>Sao Paulo</I> has 20000000 people</LI> ... </OL> </BODY> </HTML> Figure 11-3 shows the same result but as an HTML page executed in a browser.
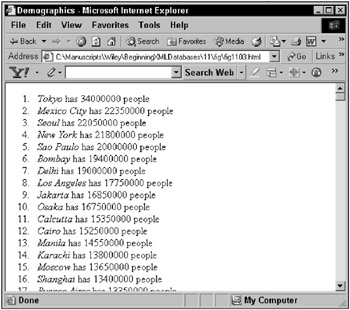
Figure 11-3: Executing an HTML page in a browser
Another way to get a numbered list into the output of a for loop is by using the at keyword as shown in this script:
for $n at $m in //city[population>0] order by $n/population descending return <city>{$m}. { string($n/name) } has { string($n/population) } people</city> The result of the preceding script is shown in Figure 11-4.
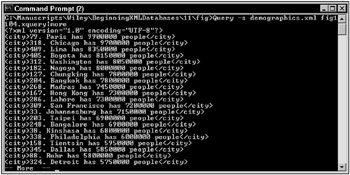
Figure 11-4: Adding a list iterator to a for loop
Now lets go into some of the details and syntax of XQuery.
XQuery Terminology
XQuery has seven different types of nodes: element, attribute, text, namespace, processing-instruction, comment, and document. A document node is actually an XML document root node. Having read all the previous chapters in this book, it should be very clear what all these nodes are. Figure 11-5 shows a brief picture of some of the different types of nodes and atomic values that XQuery can read from an XML document.
XQuery is not constructed in XML but it is used to parse through XML documents.
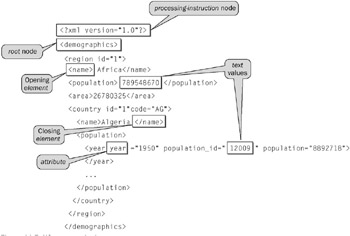
Figure 11-5: XQuery terminology
Other commonly used terms are as follows:
Atomic value: A text value, having no children or parent node.
Item value: This can be an atomic value or a node.
Parent: Refers to the parent node of a node, generally referring to nodes and not atomic values.
Child: Opposite of parent where a node can have zero or more nodes. A node that can have a child node, but does not, is referred to as an empty node.
Sibling: A sibling is a node in the same collection that has the same parent node.
Ancestor: Any node above the current node in a tree. For example, the parent, grandparent, great-grandparent, or the root node.
Descendant: Any node below the current node. For example, child, grandchild, and so on.
All this terminology has been introduced in previous chapters.
XQuery Syntax
There are a number of general rules for XQuery syntax:
-
XQuery commands and coding in general are all case sensitive, just as XML is.
-
All nodes as in elements, attributes, and variables must be valid as XML names .
-
Define variables using a $ character, as in $var .
-
Include comments into XQuery scripts by enclosing as follows:
-
If-then-else statements are permitted in XQuery as follows, where the if statement expression is enclosed in round brackets (parentheses):
if (...) then ... else ... -
Compare multiple values using standard arithmetic operators, such as =, !=, >, and <=.
-
Compare individual values using eq, ne, gt, lt, ge, and le.
Functions in XQuery
As you have seen in the numerous examples already shown in this chapter, XPath 1.0 and XPath 2.0 functions, as presented in the previous chapters, can be used easily in XQuery. You can even custom build your own functions to use within an XQuery query using the following syntax, which is fairly consistent syntactically with many other programming languages, both declarative and procedural:
declare function prefix:function_name($parameter AS datatype) AS returnDatatype { {(: ... :)} }; A custom-built function can be called as any other function would. If the function is defined as having a prefix then the prefix must be included in the function call.
| | ||
| | ||
| | ||
EAN: 2147483647
Pages: 183