14.3 Linear Probing
If we can estimate in advance the number of elements to be put into the hash table and have enough contiguous memory available to hold all the keys with some room to spare, then it is probably not worthwhile to use any links at all in the hash table. Several methods have been devised that store N items in a table of size M > N, relying on empty places in the table to help with collision resolution. Such methods are called open-addressing hashing methods.
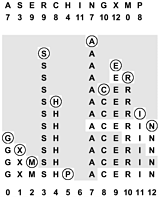
The simplest open-addressing method is called linear probing: when there is a collision (when we hash to a place in the table that is already occupied with an item whose key is not the same as the search key), then we just check the next position in the table. It is customary to refer to such a check (determining whether or not a given table position holds an item with key equal to the search key) as a probe. Linear probing is characterized by identifying three possible outcomes of a probe: if the table position contains an item whose key matches the search key, then we have a search hit; if the table position is empty, then we have a search miss; otherwise (if the table position contains an item whose key does not match the search key) we just probe the table position with the next higher index, continuing (wrapping back to the beginning of the table if we reach the end) until either the search key or an empty table position is found. If an item containing the search key is to be inserted following an unsuccessful search, then we put it into the empty table space that terminated the search. Program 14.4 is an implementation of the symbol-table ADT using this method. The process of constructing a hash table for a sample set of keys using linear probing is shown in Figure 14.7.
Figure 14.7. Hashing with linear probing
This diagram shows the process of inserting the keys A S E R C H I N G X M P into an initially empty hash table of size 13 with open addressing, using the hash values given at the top and resolving collisions with linear probing. First, the A goes into position 7, then the S goes into position 3, then the E goes into position 9, then the R goes into position 10 after a collision at position 9, and so forth. Probe sequences that run off the right end of the table continue on the left end: for example, the final key inserted, the P, hashes to position 8, then ends up in position 5 after collisions at positions 8 through 12, then 0 through 5. All table positions not probed are shaded.
As with separate chaining, the performance of open-addressing methods is dependent on the ratio a = N/M, but we interpret it differently. For separate chaining, a is the average number of items per list and is generally larger than 1. For open addressing, a is the percentage of those table positions that are occupied; it must be less than 1. We sometimes refer to a as the load factor of the hash table.
For a sparse table (small a), we expect most searches to find an empty position with just a few probes. For a nearly full table (a close to 1), a search could require a huge number of probes and even fall into an infinite loop when the table is completely full. Typically, to avoid long search times, we insist that the table not be allowed to become nearly full when using linear probing. That is, rather than using extra memory for links, we use it for extra space in the hash table that shortens probe sequences. The table size for linear probing is greater than for separate chaining, since we must have M > N, but the total amount of memory space used may be less, since no links are used. We will discuss space-usage comparisons in detail in Section 14.4; for the moment, we consider the analysis of the running time of linear probing as a function of a.
Program 14.4 Linear probing
This symbol-table implementation keeps references to items in a table twice the size of the maximum number of items expected.
To insert a new item, we hash to a table position and scan to the right to find an unoccupied position, using null entries as sentinels in unoccupied positions in precisely the same manner as in we did in key-indexed search (Program 12.7). To search for an item with a given key, we go to the key hash position and scan to look for a match, stopping when we hit an unoccupied position.
The constructor sets M such that we may expect the table to be less than half full, so the other operations will require just a few probes, if the hash function produces values that are similar to random ones.
private ITEM[] st; private int N, M; ST(int maxN) { N = 0; M = 2*maxN; st = new ITEM[M]; } void insert(ITEM x) { int i = hash(x.key(), M); while (st[i] != null) i = (i+1) % M; st[i] = x; N++; } ITEM search(KEY key) { int i = hash(key, M); while (st[i] != null) if (equals(key, st[i].key())) return st[i]; else i = (i+1) % M; return null; } The average cost of linear probing depends on the way in which the items cluster together into contiguous groups of occupied table cells, called clusters, when they are inserted. Consider the following two extremes in a linear probing table that is half full (M = 2N): In the best case, table positions with even indices could be empty, and table positions with odd indices could be occupied. In the worst case, the first half of the table positions could be empty, and the second half occupied. The average length of the clusters in both cases is N/(2N) = 1/2, but the average number of probes for an unsuccessful search is 1 (all searches take at least 1 probe) plus
![]()
in the best case, and is 1 plus
![]()
in the worst case.
Generalizing this argument, we find that the average number of probes for an unsuccessful search is proportional to the squares of the lengths of the clusters. We compute the average by computing the cost of a search miss starting at each position in the table, then dividing the total by M. All search misses take at least 1 probe, so we count the number of probes after the first. If a cluster is of length t, then the expression
![]()
counts the contribution of that cluster to the grand total. The sum of the cluster lengths is N, so, adding this cost for all cells in the table, we find that the total average cost for a search miss is 1 + N/(2M) plus the sum of the squares of the lengths of the clusters, divided by 2M. Given a table, we can quickly compute the average cost of unsuccessful search in that table (see Exercise 14.28), but the clusters are formed by a complicated dynamic process (the linear-probing algorithm) that is difficult to characterize analytically.
Despite the relatively simple form of the results, precise analysis of linear probing is a challenging task. Knuth's derviation of the following formulas in 1962 was a landmark in the analysis of algorithms (see reference section):
Property 14.3
When collisions are resolved with linear probing, the average number of probes required to search in a hash table of size M that contains N = aM keys is about
![]()
for hits and misses, respectively.
These estimates lose accuracy as a approaches 1, but we do not need them for that case, because we should not be using linear probing in a nearly full table in any event. For smaller a, the equations are sufficiently accurate. The following table summarizes the expected number of probes for search hits and misses with linear probing:
| load factor (a) | 1/2 | 2/3 | 3/4 | 9/10 |
| search hit | 1.5 | 2.0 | 3.0 | 5.5 |
| search miss | 2.5 | 5.0 | 8.5 | 55.5 |
Search misses are always more expensive than hits, and we expect that both require only a few probes in a table that is less than half full. 
As we did with separate chaining, we leave to the client the choice of whether or not to keep items with duplicate keys in the table. Such items do not necessarily appear in contiguous positions in a linear probing table other items with the same hash value can appear among items with duplicate keys.
By the very nature of the way the table is constructed, the keys in a table built with linear probing are in random order. The sort and select ADT operations require starting from scratch with one of the methods described in Chapters 6 through 10, so linear probing is not appropriate for applications where these operations are frequent.
How do we delete a key from a table built with linear probing? We cannot just remove it, because items that were inserted later might have skipped over that item, so searches for those items would terminate prematurely at the hole left by the deleted item. One solution to this problem is to rehash all the items for which this problem could arise those between the deleted one and the next unoccupied position to the right. Figure 14.8 shows an example illustrating this process; Program 14.5 is an implementation. In a sparse table, this repair process will require only a few rehash operations, at most. Another way to implement deletion is to replace the deleted key with a sentinel key that can serve as a placeholder for searches but can be identified and reused for insertions (see Exercise 14.33).
Figure 14.8. Removal in a linear-probing hash table
This diagram shows the process of removing the X from the table in Figure 14.7. The second line shows the result of just taking the X out of the table and is an unacceptable final result because the M and the P are cut off from their hash positions by the empty table position left by the X. Thus, we reinsert the M, S, H, and P (the keys to the right of the X in the same cluster) in that order, using the hash values given at the top and resolving collisions with linear probing. The M fills the hole left by the X, then the S and the H hash into the table without collisions, then the P winds up in position 2.

Program 14.5 Removal from a linear-probing hash table
To remove an item with a given key, we search for such an item and replace it with null. Then, we need to correct for the possibility that some item that lies to the right of the now-unoccupied position originally hashed to that position or to its left, because the vacancy would terminate a search for such an item. Therefore, we reinsert all the items in the same cluster as the removed item and to that item's right. Since the table is less than half full, the number of items that are reinserted will be small, on the average.
public void remove(ITEM x) { int i = hash(x.key(), M); while (st[i] != null) if (equals(x.key(), st[i].key())) break; else i = (i+1) % M; if (st[i] == null) return; st[i] = null; N--; for (int j = i+1; st[j] != null; j = (j+1) % M) { x = st[j]; st[j] = null; insert(x); N--; } } Exercises
14.24 How long could it take, in the worst case, to insert N keys into an initially empty table, using linear probing?
14.26 Do Exercise 14.25 for M = 10.
14.28 Write a program that inserts N/2 random integers into a table of size N using linear probing, then computes the average cost of a search miss in the resulting table from the cluster lengths, for N = 103, 104, 105, and 106.
14.29 Write a program that inserts N/2 random integers into a table of size N using linear probing, then computes the average cost of a search hit in the resulting table, for N = 103, 104, 105, and 106. Do not search for all the keys at the end (keep track of the cost of constructing the table).
14.30 Run experiments to determine whether the average cost of search hits or search misses changes as a long sequence of alternating random insertions and deletions using Programs 14.4 and 14.5 is made in a hash table of size 2N with N keys, for N = 10, 100, and 1000, and for up to N2 insertion deletion pairs for each N.
| Top |
EAN: 2147483647
Pages: 158