Content Encoding
15.5 Content Encoding
HTTP applications sometimes want to encode content before sending it. For example, a server might compress a large HTML document before sending it to a client that is connected over a slow connection, to help lessen the time it takes to transmit the entity. A server might scramble or encrypt the contents in a way that prevents unauthorized third parties from viewing the contents of the document.
These types of encodings are applied to the content at the sender. Once the content is content-encoded, the encoded data is sent to the receiver in the entity body as usual.
15.5.1 The Content-Encoding Process
The content-encoding process is:
1. A web server generates an original response message, with original Content-Type and Content-Length headers.
2. A content-encoding server (perhaps the origin server or a downstream proxy) creates an encoded message. The encoded message has the same Content-Type but (if, for example, the body is compressed) a different Content-Length. The content-encoding server adds a Content-Encoding header to the encoded message, so that a receiving application can decode it.
3. A receiving program gets the encoded message, decodes it, and obtains the original.
Figure 15-3 sketches a content-encoding example.
Figure 15-3. Content-encoding example
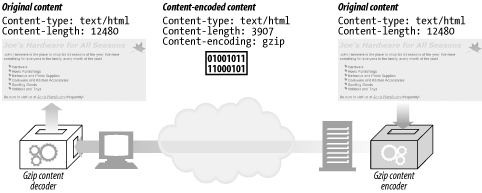
Here, an HTML page is encoded by a gzip content-encoding function, to produce a smaller, compressed body. The compressed body is sent across the network, flagged with the gzip encoding. The receiving client decompresses the entity using the gzip decoder.
This response snippet shows another example of an encoded response (a compressed image):
HTTP/1.1 200 OK
Date: Fri, 05 Nov 1999 22:35:15 GMT
Server: Apache/1.2.4
Content-Length: 6096
Content-Type: image/gif
Content-Encoding: gzip
[...]
Note that the Content-Type header can and should still be present in the message. It describes the original format of the entityinformation that may be necessary for displaying the entity once it has been decoded. Remember that the Content-Length header now represents the length of the encoded body.
15.5.2 Content-Encoding Types
HTTP defines a few standard content-encoding types and allows for additional encodings to be added as extension encodings. Encodings are standardized through the IANA, which assigns a unique token to each content-encoding algorithm. The Content-Encoding header uses these standardized token values to describe the algorithm used in the encoding.
Some of the common content-encoding tokens are listed in Table 15-2 .
Table 15-2. Content-encoding tokens | |
| Content-encoding value | Description |
| gzip | Indicates that the GNU zip encoding was applied to the entity. [8] |
| compress | Indicates that the Unix file compression program has been run on the entity. |
| deflate | Indicates that the entity has been compressed into the zlib format. [9] |
| identity | Indicates that no encoding has been performed on the entity. When a Content-Encoding header is not present, this can be assumed. |
[8] RFC 1952 describes the gzip encoding.
[9] RFCs 1950 and 1951 describe the zlib format and deflate compression.
The gzip, compress, and deflateencodings are lossless compression algorithms used to reduce the size of transmitted messages without loss of information. Of these, gzip typically is the most effective compression algorithm and is the most widely used.
15.5.3 Accept-Encoding Headers
Of course, we don't want servers encoding content in ways that the client can't decipher. To prevent servers from using encodings that the client doesn't support, the client passes along a list of supported content encodings in the Accept-Encoding request header. If the HTTP request does not contain an Accept-Encoding header, a server can assume that the client will accept any encoding (equivalent to passing Accept-Encoding: *).
Figure 15-4 shows an example of Accept-Encoding in an HTTP transaction.
Figure 15-4. Content encoding
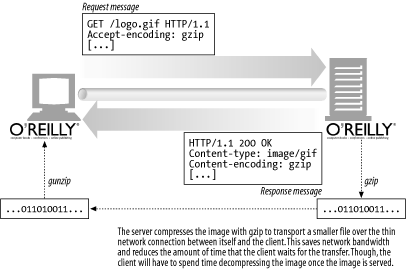
The Accept-Encoding field contains a comma-separated list of supported encodings. Here are a few examples:
Accept-Encoding: compress, gzip Accept-Encoding: Accept-Encoding: * Accept-Encoding: compress;q=0.5, gzip;q=1.0 Accept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0 Clients can indicate preferred encodings by attaching Q (quality) values as parameters to each encoding. Q values can range from 0.0, indicating that the client does not want the associated encoding, to 1.0, indicating the preferred encoding. The token "*" means "anything else." The process of selecting which content encoding to apply is part of a more general process of deciding which content to send back to a client in a response. This process and the Content-Encoding and Accept-Encoding headers are discussed in more detail in Chapter 17 .
The identity encoding token can be present only in the Accept-Encoding header and is used by clients to specify relative preference over other content-encoding algorithms.
EAN: 2147483647
Pages: 294