Common Component Conventions
| Although each of the stock components is unique, they also share some similarities, especially in the component designers. This section covers the component and designer conventions, which most of the stock components use to some extent. Custom Component Editors and the Advanced EditorYou can edit data flow components in three ways. Like most objects in the designer, you can modify component properties in the property grid. You can get by with modifying certain properties with only the property grid, but it has limitations. Another way to edit components in the designer is to use their custom editor. Some, but not all, stock components have a custom editor. Custom component editors only support a given component and provide features for supporting the specific functions and properties of that component. The final way to modify components is to use the Advanced Editor, which is the default editor for some components with no custom editor and is available to edit most components even if they have custom editors. The Advanced Editor is a generic editor, but it also exposes some component properties that are not visible in any other location; specifically, the input and output properties of components. You can open the editor or Advanced Editor by either right-clicking on the component and selecting the corresponding menu item for the editor you want to open, or you can click on the Show Editor or Show Advanced Editor links at the bottom of the properties grid. You must have the component selected in the designer for these links to appear. If the links don't appear, right-click on the margin just below the property grid and in the context menu that appears, make sure the Commands menu item is selected. Figure 20.1 shows the editor links. Figure 20.1. The properties grid for the OLE DB Source Adapter with the editor links Error OutputComponents might provide a secondary output called, appropriately enough, an error output. Error outputs provide a way for a component to redirect rows with one or more columns containing errors. Errors occur when the transform encounters unexpected data. For example, if the transform is expecting a column to contain an integer but it actually contains a date, that would be considered an error. Also, the Data Flow Task treats potential truncations as a different class of errors so that you can handle both with different settings. Although errors are always bad, truncations might be OK or even desirable. Error outputs provide a way for components to divert error and truncation rows to a separate output, providing various options for handling the exceptional data. Figure 20.2 shows the error row editor for the OLE DB Source Adapter. Figure 20.2. Changing the error output options for multiple columns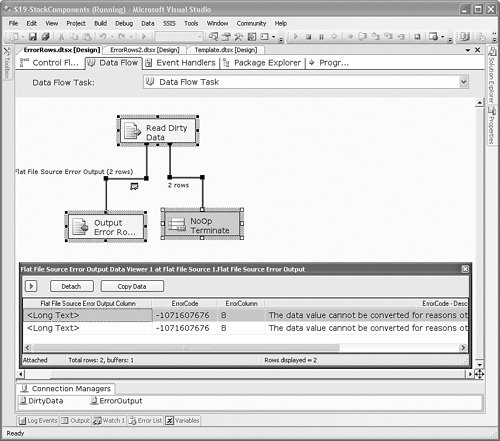 Using the Error Output Editor, you can specify how the component will handle a row with an error. There are three options:
Caution When selecting multiple columns and choosing the error disposition, as shown in Figure 20.2, make sure you click the Apply button so that your change will be applied to all the selected columns. The option you choose is, of course, dependent on your requirements and how important it is to you that your data be completely clean. Following are some examples of how people process rows with errors.
Note Notice that error output settings are found on the Error Output tab. Many of the components support error outputs, but not all of them. Some components have a separate Configure Error Outputs button instead of the tab. Some components have neither if they don't support error outputs. Error ColumnsError outputs have two additional columns called ErrorCode and ErrorColumn. The ErrorCode column contains the error ID of the error and the ErrorColumn contains the column ID of the column that generated the error. If you create a Data Viewer on the error output, you can see the ErrorCode, ErrorColumn, and ErrorCode Description for each error row. Figure 20.3 shows the ErrorRows sample package in the S20-StockComponents sample solution. Figure 20.3. Viewing the error output columns The ErrorCode column gives you an ID that you can look up in the errors list. The ErrorColumn is the ID of the column that caused the error. To use this value, open the Advanced Editor for the component that caused the error and look at the output columns. In this case, the OutputColumn value was 8. Figure 20.4 shows that the column with the ID of 8 was "Column 1" on the Flat File Source Adapter called Read Dirty Data. Figure 20.4. Finding the column that caused an error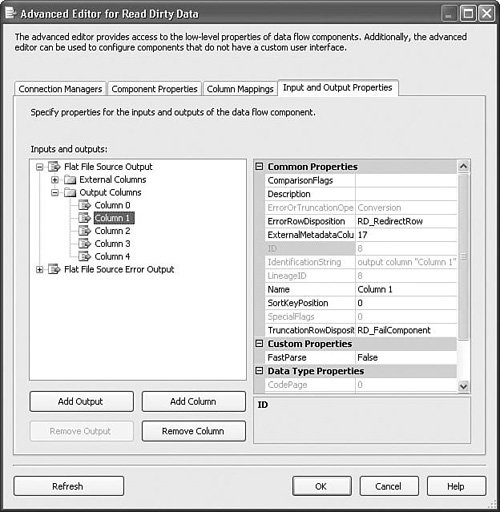 Column MappingAnother thing components have in common is the way they represent columns and column mappings. Figure 20.5 shows the editor for the Flat File Source Adapter. Because it is a source, there are no input columns to which you can map the output columns. You can choose to eliminate columns if you want. In this case, "Column 4" is deselected, making it unavailable to any of the downstream components. Figure 20.5. Eliminating an input column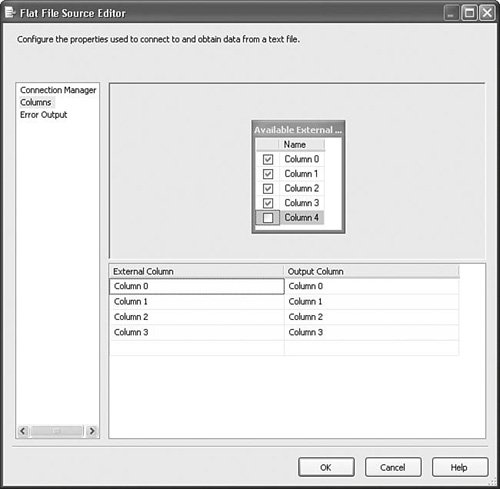 Figure 20.6 shows the Flat File Destination Editor with the three columns of the error output from the Flat File Source Adapter called Read Dirty Data in Figure 20.3. To remove one of the mappings, the lines between the columns, you click on it with the mouse and press the Delete key. Figure 20.6. Selecting and deleting mappings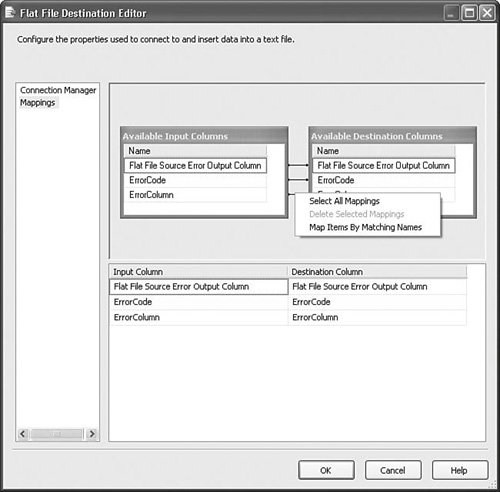 You can also right-click in any spot inside the Columns window to access the context menu shown previously. This is a quick way to select and delete all the mappings, which is useful when the metadata on either the input or output changes and you need to remap the columns. Access ModesMany components provide different ways to access a given resource. For example, the OLE DB Source Adapter provides four options for where to retrieve rows:
The XML Source Adapter provides three different ways to access XML data:
These options for accessing resources are called Access modes and are common throughout components. They provide a way to flexibly and dynamically modify important component settings. External MetadataWhen a component is disconnected from its data source or destination, it has no way to validate against the actual source or destination metadata. Integration Services provides a way to cache the source or destination metadata at the component so that the component can still validate and map columns, even when the component is disconnected. When the component is connected to its data source or destination, it validates its components against the metadata in the source or destination. When disconnected, it validates against the External Metadata cache. Component GroupsAs the thickness of this chapter confirms, there are a lot of data flow components that ship with Integration Services; 45 by my count, depending on the edition you have installed. So, here, the components are organized by functional categories. Source adapters and destination adapters are obvious categories, and the transforms are further organized into three categories:
Although overlaps exist between the categories, and arguments could be made that a transform doesn't belong in one but should be in another, this categorization is purely for convenience of organization and shouldn't be viewed strictly. Source AdaptersSource adapters retrieve data from the location and format in which it is stored and convert it to the common data flow buffer format, placing it in a data flow buffer. Flow Control TransformsFlow Control transforms direct rows down different paths, create new outputs or columns, merge multiple outputs, or otherwise direct data to different portions of the data flow based on predicates or structure. Auditing TransformsAuditing transforms generate metadata about the data flow that is consumed outside of the Data Flow Task. This information can be useful for diagnostic or lineage information. Data Manipulation TransformsThese are the transforms that perform the heavy data transformation lifting. They vary in data processing extremes from the Character Map transform, which merely performs case conversions on strings, to the Aggregate transform, which consumes all rows on the input while potentially producing only one output row. Destination AdaptersDestination adapters retrieve data from data flow buffers and insert it into the adapter-specific format and location. Advanced ComponentsThere are some components that ship with the Developer and Enterprise Editions of SQL Server only or are for specialized purposes, so they are discussed in their own chapter. You can find them in Chapter 22.
Component PropertiesFor each component, a table is provided that lists the properties in a condensed format for reference. These aren't properties on the component itself, but rather descriptive properties or classifications to help better characterize the components. The properties and possible values contained in the tables are as follows:
|
EAN: 2147483647
Pages: 200