An Introduction to SQL Server Integration Services
| | ||
| | ||
| | ||
We begin this chapter with an overview of SQL Server 2005 Integration Services. The goal of the introduction is to familiarize you with the ETL toolset so that you can understand its features and grow comfortable with its vocabulary. This overview is not a tutorial on Integration Services; were focusing more on the what and why of the tool than on the how.
| |
SQL Server 7.0 and SQL Server 2000 included a product called Data Transformation Services, DTS for short. Many customers used DTS to build part or all of their ETL systems. DTSs primary appealperhaps its only appeal was its price: Included with SQL Server, it was free. The most effective use of DTS was as a framework for an ETL system that was primarily SQL-based. In other words, people mostly wrote SQL statements or scripts to perform transformations, and used DTS to define the success/failure workflow between those scripts. Most DTS-based ETL systems were not substantively different than the old SQL-and-Perl-script custom systems of decades past, except the scripting part was replaced by the DTS model and design palette.
| |
The new Integration Services, which replaces Data Transformation Services (DTS), is a lot more than a name change: Its a completely new product. Integration Services has nothing in common with its predecessor. Its important to emphasize this point, especially to those readers who were familiar or even expert with the old DTS. Integration Services is more than just an ETL tool. You can use it to manage and maintain your databases and to integrate data among applications or perform complex calculations in real time. In this chapter, we focus on using Integration Services for ETL.
Your ETL team will develop one or more Integration Services packages to populate your DW/BI system. A package is analogous to a computer program or a script. When your DW/BI system is in production, you can execute a package to perform a database maintenance task, to load a table, or to populate an entire business process dimensional model.
An Integration Services package contains one or more tasks. In the ETL application youll primarily use control flow tasks , like manipulating files, sending email to an operator, or bulking insert data from a file. By far the most interesting task is called the Data Flow task, in which most of the real ETL work is done. Well talk a lot more about the Data Flow task later in this chapter.
Overview of BI Studio Integration Services Tool
During the design and development phases of your DW/BI project, youll use Integration Services in its design and debugging mode. Youll develop Integration Services packages in the Business Intelligence Development Studio tool (BI Studio), which as we described in Chapter 3 is part of the Visual Studio development toolset.
The easiest way to become familiar with the BI Studio Integration Services designer is to open an existing package, like the Master_Dims package illustrated in Figure 5.2. This package is included on the books web site, www.MsftDWToolkit.com.
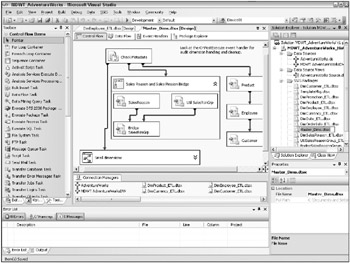
Figure 5.2: Editing the Master_Dims package in BI Studio
In the upper right of the BI Studio screen is the Solution Explorer. The Solution Explorer provides a mechanism for navigating between the different components of your Integration Services project: the data sources and data source views that youve defined; the Integration Services packages that are part of this project; and other files, which may include documentation. The Master_Dims package is open and currently displayed in the middle of the BI Studio. This project is part of a solution, which could include multiple Integration Services projects, Analysis Services projects, and Reporting Services projects.
In Figure 5.2, our solution is called MDWT_AdventureWorks, and contains several Integration Services projects, an Analysis Services project, and several reporting projects. Because the window is small, you can see only the opened Integration Services project, MDWT_AdventureWorks_Hist.
On the left-hand side of the BI Studio screen is the toolbox, which lists, in this view, the control flow items that you can add to your package. The large area in the center of the screen is the design surface, on which you place control flow tasks. You can connect tasks with precedence constraints, specifying whether to execute a downstream task upon success, failure, or completion of an earlier task or tasks. You can define expressions on the precedence constraints, which is a powerful feature for system automation. As youd expect, precedence constraints can contain OR conditions as well as AND conditions.
There are several components of the design surface: Control Flow, Data Flow, Event Handlers, and Package Explorer. Each of these is represented by its own tab across the top of the design surface. During and after package execution in BI Studio, youll be able to examine execution progress in the Progress tab, which doesnt appear until you run the package. (The Progress tab is renamed Execution Results once you exit execution mode.) Navigate between the design components by clicking on the appropriate tab. Youll use the Control Flow and Data Flow tabs most often. The Control Flow is the outer layer of the package, in which all the packages tasks and dependencies are defined.
The Package Explorer tab presents a navigation interface for you to examine the objects that have been defined in the package. Here you can browse the variables that are defined at the overall package level, or scoped down to a task or container. Similarly, you can view the event handlers that youve defined for the overall package or for any task or container. Variables and event handlers are discussed in more detail in the sections that follow.
Control Flow
The toolbox on the left-hand side of the screen in Figure 5.2 shows the available control flow tasks. There are two categories of control flow tasks: Control Flow Items and Maintenance Plan tasks. In the small screen pictured in Figure 5.2, only some of the control flow tasks are visible. You might use some of the maintenance tasks in your ETL packages, but their main use is for automating operations and maintenance.
The control flow items are more relevant for building an ETL system. The most important is the Data Flow task, which we discuss in much greater detail in the text that follows . As you design your ETL system, you should be aware of the other predefined tasks that are available to you:
-
Bulk Insert task: The Bulk Insert task lets you perform a fast load of data from flat files into a target table. Its similar to using BCP to bulk copy a file into a table, and is appropriate for loading clean data. If you need to transform data thats stored in a flat file, you should instead use a data flow task that uses the flat file as a source.
-
Execute SQL task: The Execute SQL task, as you might expect, will execute a SQL statement against a specified database. The database need not be SQL Server, but the statement must be written in the appropriate dialect of SQL. Use this task to perform database operations like creating views, tables, or even databases. A common use of this task is to query data or metadata, and to put the query results into a variable. We used the Execute SQL task in the package illustrated in Figure 5.2.
Note The Execute SQL task, like many other tasks and objects in Integration Services, uses an interfaceusually OLE DBto execute SQL even against SQL Server. You may find that a statement that you develop and test in Management Studio will generate an error inside the Execute SQL task: OLE DB syntax is more restrictive than that allowed in Management Studio. Declaring a variable is the most common SQL syntax thats disallowed by OLE DB.
-
File Transfer Protocol and File System tasks: Use the File Transfer Protocol task to transfer files and sets of files. Use the File System task to perform file system operations like copying, moving, or deleting files and folders.
-
Execute Package, Execute DTS2000 Package, and Execute Process tasks: The Execute Package task executes an Integration Services package. With it you can (and should) break a complex workflow into smaller packages, and define a parent or master package to execute them. The Master_ Dims package from Figure 5.2 is a master package used only for workflow. Its work is handled by the subpackages it calls. Create a separate package to populate each table in your data warehouse database. The use of parent and children packages enables the modularization and reuse of complex logic. If you have DTS2000 packages running already in your production system, you can run them with the Execute DTS2000 Package task. The Execute Process task will run any operating system process. For example, you may have a custom process that will generate the source system extract, or you may invoke a non-SQL Server relational databases bulk loader.
-
Send Mail task: The Send Mail task sends an email message. You will almost certainly use this task in an event handler, for example to send a message to an operator about a processing failure.
-
Script and ActiveX Script tasks: These tasks are available to perform an endless array of operations that are beyond the scope of the standard tasks. The ActiveX Script task is provided for backwards compatibility to DTS2000; use the Script task for new work. The Script task uses Visual Basic .NET from the Visual Studio for Applications environment. Or, you can use any .NET language to create a custom task that will become available in the list of control flow tasks. Defining a custom task is a programming job, rather than simply scripting, but has the significant benefit of re-use.
-
Data Mining and Analysis Services Processing tasks: The Data Mining task runs an Analysis Services data mining query and saves the results to a table. The Analysis Services Processing task will launch processing on Analysis Services dimensions and databases. Use the Analysis Services DDL task to create new Analysis Services partitions, or perform any data definition language operation. There are Data Mining and Analysis Services Data Flow transforms, as well as these control flow tasks. Use the Analysis Services control flow tasks to fully or incrementally update your databases and models. The use of the corresponding Data Flow transforms is discussed in the next section.
-
XML and Web Services tasks: The XML task retrieves XML documents and applies XML operations to them. Use the XML task to validate an XML document against its XSD schema, or to compare or merge two XML documents. Use the Web Services task to make calls to a web service.
-
Message Queue, WMI Data Reader, and WMI Event Watcher tasks: These tasks are useful for building an automated ETL system. The Message Queue task uses Microsoft Message Queue (MSMQ) to manage tasks in a distributed system. You can use the WMI tasks to coordinate with the Windows Management Interface, and automate the execution of a package or set of tasks when a specific system event has occurred.
-
ForEach Loop, For Loop, and Sequence containers: Use containers like the ForEach Loop and For Loop to execute a set of tasks multiple times. For example, you can loop over all the tables in a database, performing a standard set of operations like updating index statistics. The Sequence container groups together several tasks. Use it to define a transaction boundary around a set of tasks so they all fail or succeed together. Or, use it simply to reduce the clutter on the design surface by hiding the detailed steps within the sequence. We used a sequence container in the package illustrated in Figure 5.2, for the Sales Reason and Sales Reason Bridge tables. You can also group control flow objects, and collapse or expand those groups. Theres no task for grouping. Simply select several objects, right-click, and choose Group . In Figure 5.2 we grouped the Execute Package tasks for several small dimensions, and collapsed that into the Small dimensions group.
-
Data Flow task: The Data Flow task is where most ETL work is performed. The Data Flow task is discussed in the next section.
Data Flow
The Data Flow task is a pipeline in which data is picked up, processed , and written to a destination. The key characteristic of the pipeline is defined by the tasks name: The data flows through the pipeline in memory. An implication of the data flow pipeline architecture is that avoiding I/O provides excellent performance, subject to the memory characteristics of the physical system.
In the control flow design surface, the Data Flow task looks like any other task. It is, however, unique in that if you double-click on the Data Flow task, you switch to the data flow design surface where you can view and edit the many steps of the data flow, as illustrated in Figure 5.3.
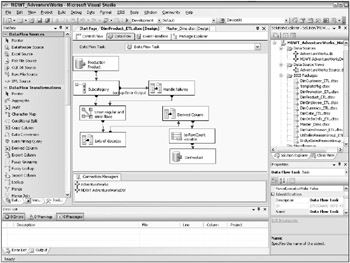
Figure 5.3: Viewing a Data Flow task
The toolbox on the left now displays the list of Data Flow transforms. You can re-order the transforms so that your favorites are at the top.
A data flow task contains one or more data sources, zero or more transformation steps, and zero or more data destinations. The simplest useful data flow task would have one source and one destination: It would copy data from one place to another. Most data flow tasks are a lot more complicated than that, with multiple sources, transformations, and even destinations.
Data Sources
There are several kinds of predefined source adapters, called Data Flow Sources in the toolbox pane:
-
Use the OLE DB Source adapter to extract data from any source that has an OLE DB provider, including SQL Server, Oracle, and DB2. You can source from a table or view, or from a SQL query or stored procedure. You may source from a query or stored procedure if your source table is huge and you want only a relatively small number of rows. Figure 5.3 depicts a data flow that uses an OLE DB data source.
-
Use the DataReader Source adapter to extract data from a .NET Provider like ADONET:SQL or ADONET:ORACLE. Youll probably use an OLE DB provider instead, even for sourcing data from SQL Server because it has a nicer user interface. If performance is vital , use the DataReader source adapter, which has slightly better performance than the OLE DB adapter, but only the most basic user interface.
-
The Flat File Source adapter pulls data from a flat file. You could use an OLE DB or ODBC flat file driver, but we prefer the Flat File Source because it has a better UI and handles bad data more flexibly.
-
The Raw File Source adapter pulls data from a raw data file, which is a format unique to Integration Services. Integration Services writes data to and reads data from the raw format very efficiently . Raw files are a great format to use for data staging, for example to store data extracts during the day (or month) until the main transformation logic kicks off. Also use raw files to hold a fast backup of the dimension tables or fact rows that will be updated during an ETL operation.
-
The XML Source adapter pulls data from an XML source. The XML source can be either in a file or in a package variable (which, presumably, you set in an earlier task in the package). You can optionally apply an XSD schema definition against the XML data. You should hesitate to take any XML data that doesnt have a schema! Because XML data is so unstructured, the source adapter lets you break out the data into multiple destinations. These might flow into different tables, or be handled in different ways before being recombined into a single table.
-
You can define a custom source adapter to consume data from a unique source, like a file whose rows have different formats under different conditions. For a single-time use, you could use the Script transform to write the source adapter. To easily re-use the custom adapter, develop it in any VS.NET language and install the custom adapter into the list of data flow transformations, as described in Books Online.
All of the source adapters except the raw file source use connection information that is shared across the package. If you plan to pull data from 25 tables in a database, you define one shared connection, including login information, to that database. If you need to change the connection information, for example when you change servers, you have to modify only the single shared connection. Within one or more data flow tasks, define the data source steps to use the shared connection to extract the data from those 25 tables. You can see the example connections in Figure 5.3 in the Connections Managers pane in the lower-middle section of the screen.
All of the source adapters, except the raw file source, support an error flow in addition to the normal output data flow. The ability to define error flow logic on the source is particularly useful for unstructured data sources like Excel workbooks or flat files, where malformed data is very common. Well discuss error flows in greater detail later in this chapter.
Data Destinations
There are several kinds of predefined destination adapters, called Data Flow Destinations. These are available in the same toolbox illustrated in Figure 5.3, simply by scrolling down in the toolbox list.
-
The OLE DB destination adapter will load data into any OLE DB target database or table, like SQL Server, Oracle, DB2, or even Excel. If you are loading a large volume of data into non-SQL Server OLE DB destination, its usually more efficient to write the data as a flat file and use the Execute Process control flow task to invoke the target databases bulk loader.
-
You can use the SQL Server destination adapter to load data into the SQL Server relational database, instead of the OLE DB adapter. There are several differences between the two adapters:
-
The SQL Server adapter can write data only to a SQL Server relational database running on the same machine as Integration Services.
-
The SQL Server adapter requires that data be formatted perfectly ; it skips some data checking and conversion steps that the OLE DB adapter performs for you.
-
The SQL Server adapter can perform faster than the OLE DB adapter because it skips those data checking and conversion steps.
-
Unlike the OLE DB adapter, the SQL Server adapter doesnt let you set a batch size or commit size for bulk loading. In some scenarios, setting these parameters optimally enables the OLE DB adapter to out-perform the SQL Server adapter.
-
-
Use OLE DB during the early stages of development because its more forgiving of data type mismatches . Late in the development cycle, test the performance of the two adapters to determine which you want to use in production.
-
The Flat File and Raw File destination adapters write the data stream to the file system. Use raw files if the data will be consumed only by Integration Services. Flat files are a standard format appropriate for many uses.
-
Use the Data Reader destination adapter to generate a Reporting Services report directly from an Integration Services package. This feature enables an interesting use of Integration Services for real-time DW/BI systems, as we discuss in Chapter 17.
-
The Recordset destination adapter populates an ADODB recordset object held in memory.
-
The SQL Mobile destination adapter is appropriate for pushing data down to SQL Server Mobile Edition databases.
-
The Dimension and Partition Processing destination adapters push the pipeline data into an Analysis Services dimension or fact partition, without the usual intermediate step of writing the data to a relational database. In this scenario, the Analysis Services database is populated directly from the ETL data stream. This feature is most interesting for real-time DW/BI systems.
-
You can define a custom destination adapter to write data to a custom target, just as you could develop a custom source adapter. We hope someone will develop a flexible, high-performance Oracle destination.
Data Transformations
Between sources and destinations are the data transformation steps. These include:
-
Sort and Aggregate transforms perform high performance sorting and aggregation. The Aggregate transform can generate multiple aggregates in a single step. The Sort transform can optionally remove duplicate rows. Both the Sort and Aggregate transforms are asynchronous, which means they consume all the data in the flow before they generate an output flow. When you think about what theyre doing, this makes perfect sense. The performance of the Sort and Aggregate transforms is excellent, and should meet most applications sorting and aggregation requirements. In exceptional circumstances you may need a third-party sort or aggregation utility that integrates with Integration Services.
SORTING AND AGGREGATING LARGE DATASETS Exercise caution in using the Sort and Aggregate transforms for large datasets. These transforms will use virtual address space, and can create memory pressure on other applications running on the server. In Chapter 15 we describe how to monitor your DW/BI system to watch for memory pressure.
-
Conditional Split and Multicast transforms create multiple output streams from one data stream. Use Conditional Split to define a condition that divides the data stream into discrete pieces, for example based on a columns value being greater or less than 100. You can treat the split streams differently and recombine them later, or you can use the Conditional Split to filter the data. The Multicast transform efficiently replicates a stream, perhaps for parallel processing. The Conditional Split transform sends each input row to one and only one output stream; Multicast sends each input row to each output stream.
-
The Union All, Merge, Merge Join, and Lookup transforms all join multiple data streams. Use Union All to combine multiple streams with similar structures, perhaps from an upstream Conditional Split, or for Customer records from multiple source systems. Merge is very similar to Union All, but it interleaves sorted rows. If you dont care about the order of the rows in the output stream, Union All is both more forgiving and more efficient. Merge Join is a lot like a database join: it merges rows based on columns in common, and can perform a left, full, or inner join. The Lookup transform is very useful for decoding a code from the source data into a friendly label using information stored in a database table. Youll make heavy use of the Lookup transform in performing the surrogate key assignment on your incoming fact data. The operations performed by these four transforms could all be performed using SQL queries. But if the data is in the pipeline its easier and almost always more efficient to use these transforms than to write to a table and potentially index that table before performing a SQL query. We use the Lookup transform in the data flow illustrated in Figure 5.3.
-
The Character Map, Copy/Map, Data Conversion, and Derived Column transforms all do basic transformations. Character Map works only on string data, and will perform transformations like changing case, and changing character width for international strings. Copy/Map simply creates a second copy of an existing column in the stream. Data Conversion changes the data type of one or more columns, for example translating a date string to a true date. Finally, the Derived Column transform is where the most interesting transformation logic occurs. Use Integration Services variables and expressions, discussed in the text that follows, to develop complex transformations on one or more columns, like parsing or concatenating strings, calculating a mathematical expression, or performing a date/time computation. The Derived Column transform dialog box calls the expression editor to help you construct your expressions. We use the Derived Column transform in Figure 5.3.
-
The Slowly Changing Dimension transform does a lot more for you than most of the other transforms. It launches a wizard that generates a bunch of objects to manage dimension changes. Youll use the wizard to specify which columns take a Type 1 change, a Type 2 change, or which can never be changed. The generated objects automatically compare the incoming dimension rows with the existing dimension, propagate a new row for the Type 2 dimension if necessary, update Type 1 attributes, and manage the common slowly changing dimension metadata attributes. You could do all this by hand using more atomic Integration Services objects, but the Slowly Changing Dimension transform is a lot easier.
-
Use the OLE DB Command transform to update or delete rows in a target table, based on the data in the data flow. The OLE DB Command transformation executes a SQL statement for each row in a data flow; the SQL statement is usually parameterized. The OLE DB Command is the only way to execute an UPDATE statement from within the Data Flow. If your ETL process requires a large number of updatesmost common for snapshot fact tablesyou should consider writing the target rows to a staging table and performing a bulk UPDATE statement from the Execute SQL task in the Control Flow instead.
-
The Row Count and Audit transforms are most useful for developing process metadata about the data flow. Use the Row Count transform to efficiently count the rows that will be loaded to the target, or that flow into the error handler. Audit captures information about the system environment at the time the data flow task is run, including the computer name, user id, and execution start time.
-
You can use the Percentage Sampling and Row Sampling transforms during package testing, to operate against a subset of the source data. Youll also use sampling to choose a random sample for deep analysis and data mining, and for building your sandbox source system as described later in this chapter.
-
The Pivot and Unpivot transforms will reduce or increase, respectively, the number of rows in the data stream. Use the Unpivot transform to create 12 rows of data from a single source row that has 12 columns holding a years worth of monthly values.
-
Use the Data Mining Model Training and Data Mining Query transforms to incorporate Analysis Services data mining technology into your ETL application. For example, you may have a Customer Score attribute in the Customer dimension, whose value comes from a data mining model. These transforms will compute that model and return the results into the data flow pipeline.
-
Fuzzy Grouping and Fuzzy Lookup transforms employ fuzzy logic algorithms that were developed by Microsoft Research. These are useful transforms for data cleansing and de-duplication. Fuzzy Lookup, like the Lookup transform, compares and matches two sets of data, but with a measure of confidence based on semantic similarity. Fuzzy Grouping acts much the same way, but is used to de-duplicate data on fuzzy criteria. Unlike third-party tools that perform name/address matching based on a detailed history of addresses, these fuzzy algorithms are based on semantics. You have to experiment with the settings, but the transforms are valuable for a wide range of data cleansing problems.
-
Term Extraction and Term Lookup transforms employ text-mining algorithms that were also developed by Microsoft Research. Term Extraction is a text-mining component which returns key terms from a document in a text column. Term Lookup matches a document to key terms in a reference table.
-
The File Extractor and File Injector transforms are used primarily to strip out (extract) text and image data from a data flow and put it into a file or files, or to add such data from files into the data flow.
-
The Script component provides a simple mechanism for creating a custom transformation in the Visual Studio for Applications environment. We include a simple example of using the Script component in Chapter 6.
Error Flows
Most of the data flow source adapters and transformations support two kinds of output flows: normal flows (green) and error flows (red). The error flow from a flat file source would include any rows with a type mismatch, for example string data in a numeric field. The error flow is a data flow just like the normal flow. You can transform the data to fix the error, and hook it back up with the normal flow. You can write the error flow to a table or file. You can see an illustration of error flows in Figure 5.3, extending to the right of the Subcategory lookup.
The most important characteristic of the error flow construct is that an error in some data rows does not halt the entire data flow step unless you design the flow to do so. And, you can perform arbitrarily complex transformations to the error flow, to correct the data or to log the bad rows for a person to examine and fix.
| Warning | By default, all steps in the data flow are set up to fail if an error is encountered . To make use of error flows, youll need to modify this default behavior by setting up an error flow and changing the error flow characteristics of the transform. |
Concepts for Dynamic Packages
There are many tools available to modify the actions that a package takes when its executing. As we describe in the following subsections, expressions and variables work hand in hand. Integration Services implements a rich expression language that is used in control flow and also in the data flow transform. The results of expressions are often placed into variables, which can be shared throughout the network of packages.
Configurations are a way to change the way a package executes at runtime. You will use configurations most often to set connection information like server names .
Expressions
As youd expect, Integration Services includes an expression language for specifying data flow transformations. Surprisingly, that expression syntax is neither TSQL nor VBScript, but something unique to Integration Services.
Most expressions are simple: A + B , or A > B , a function like GETDATE() , or a constant like ABC . The two places where youre most likely to use expressions, including complex expressions, are in the Conditional Split and Derived Column data flow transforms. The dialog boxes for these two transforms provide the Expression Builder, which is a graphical tool for building expressions. The Expression Builder provides a list of available data columns and variables, and a list of functions and operators, which you can use to construct an expression. The Expression Builder automatically adds needed syntax elements, like the @ prefix on variable names.
In addition to the Conditional Split and Derived Column transforms, you can use expressions in the following contexts:
-
A variables value can be set to an expression.
-
Many container task properties can be set to a variable or expression. Perhaps youre manipulating files whose names are affixed with a date and time. Create an expression to generate the file names in, say, the FTP task, and iterate over the expression.
-
Data Flow transforms cannot be reconfigured dynamically. This is different from DTS2000, where such dynamic reconfiguration was often necessary. However, many of the transforms can source from a query or data passed in from a variable. This feature, combined with the Script transform, meets a lot of the needs for dynamic configuration.
-
A For Loop containers initialization, evaluation, and increment statements are expressions.
-
A precedence constraint can use an expression to specify whether the downstream tasks run. For example, you can set a precedence task to evaluate to TRUE if some value (like an error rowcount) is less than a specified maximum.
Variables
You can define variables within your package. Variables can be scoped to any object: package-wide, within a container like a sequence, or scoped down as specific as a single task. Variables that are defined at the package level are available to all objects and tasks within the package.
Youll frequently set a variable to a constant expression like 1000 , but the full power of the expression syntax is available to you. As a simple example, near the beginning of your package you may set a variable youve defined to track the package start time, to the expression GETDATE() .
| Warning | There are several ways to get the current time. In addition to GETDATE() , you could use the Integration Services variable StartTime . Unless all your servers clocks are synchronized, you should use a consistent method to get the current time. |
Youll find more uses for variables than we can list here. Some of the common uses are to:
-
Control execution of container loops
-
Populate a variable from a SQL query, and then use that variable to control the packages execution
-
Build expressions using variables, for use in data flow transforms like Derived Column
You can examine the values of variables while the package is executing in debug mode.
User-defined variables are the most interesting, but there are a ton of system variables available for you to examine and, possibly, log to your metadata tables.
You can create a new variable from within many dialog boxes that use variables. But its better to think about the variables youll need during design time, and create them by choosing the SSIS Variables menu and working in the Variables taskpad.
Configurations
Configurations help your Integration Services packages respond gracefully to changes in your operating environment. You can overwrite most of the settings for Integration Services objects by supplying a configuration file at runtime. Variables initial values can also be set from a configuration file.
The single most powerful use of configurations, which everyone should use, is to change server connection settings for sources and destinations. At runtime, without editing the package, you can point all connections to the production servers, or easily change server names or database names. It makes sense to use configurations to change other properties in the production environment, like a disk space threshold, or a threshold for how many rows are processed at a time.
Multiple packages can use the same configuration file, which makes it very easy to deploy a server name change in the production environment. A single package can use multiple configurations. You control the order in which the configuration files are applied; if multiple configurations affect the same property, the last configuration wins.
Integration Services can load configurations from various sources: SQL Server, an XML file, a parent package variable, or a Windows environment variable or registry entry. XML configuration files are easily managed in your source control system. As database people, we generally prefer to use SQL Server to store configurations in production. In Chapter 6 we describe how to use configurations to communicate between packages using a parent package variable.
Use the Configuration Wizard to create the basic structure of a configuration file. Launch that wizard by choosing the SSIS Package Configurations menu item in BI Studio. The Configuration Wizard generates the configuration as an XML file in the file system with the file extension .dtsConfig. To change the values of an item in the XML file, use your favorite editor. You may want to add the configuration file into the project, as a miscellaneous file. This last step isnt necessary, but it makes the configuration file easy to find and edit from within BI Studio. Dont forget to put the configuration files under source control!
In the test and production environments, you will use the DTExecUI or DTExec utilities to execute your packages, rather than the debugging environment in the BI Studio. With those utilities, you can specify which configuration file or files to use for this execution. We talk more about these utilities in Chapter 15.
Event Handlers
The Integration Services package, container, and task objects will raise events during package execution. You can create custom event handlers for these events. These event handlers are just like a separate package or subpackage, and will contain tasks just like the main package does. You can write a different event handler for many different kinds of events, including OnError, OnPreExecute, or OnPostExecute.
Write an OnPostExecute event handler to clean up temporary storage and other settings when a package or task finishes. Write a package OnPreExecute event handler to check whether theres enough disk space available for the package to run. Write an OnError event handler to restore the data warehouse database to a consistent state, and notify an operator of the problem.
Events percolate up until they find an event handler. For example, if you define an OnProgress event handler at the package level, the individual tasks in that package will use that same event handler unless they have an OnProgress event handler of their own.
You can design and edit event handlers from the Event Handler tab on the Integration Services design surface. The easiest way to see which event handlers have been defined for a package object is to switch to the Package Explorer tab.
| | ||
| | ||
| | ||
EAN: N/A
Pages: 125
- Integration Strategies and Tactics for Information Technology Governance
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Governing Information Technology Through COBIT
- Governance in IT Outsourcing Partnerships