System Configuration Considerations
| | ||
| | ||
| | ||
One of the big configuration decisions is whether to use one large machine or distribute your DW/BI system across multiple servers. A small company can run a DW/BI system on a single server that runs the relational database, Integration Services, Analysis Services, and Reporting Services with IIS. A large enterprises DW/BI system will be broken apart over multiple servers, some clustered. How can you possibly determine what configuration is going to be most appropriate for your workload? It helps to break the question down into the major system components and configuration options. These include memory, processors, storage, monolithic or distributed systems, and high availability systems.
How Much Memory?
All of the SQL Server DW/BI components love physical memory. The relational database uses memory at query time to resolve the DW/BI style of query, and during ETL processing for index restructuring. Analysis Services uses memory for resolving queries and performing calculations, for caching result sets, and for managing user session information. During processing, Analysis Services uses memory to compute aggregations, data mining models, and any stored calculations. The whole point of Integration Services data flow pipeline is to avoid temporarily writing data to disk during the ETL process. Depending on your package design, you may need several times as much memory as your largest incremental processing set. Reporting Services is probably the least memory- intensive of the four major components, but rendering large or complex reports will also place a strain on memory resources.
Because all the DW/BI system components are memory intensive, the obvious solution is to buy hardware that supports a lot of memory. You can purchase a four-way 64-bit server with 8 to 16GB of memory for surprisingly little money. A commodity 64-bit four-way machine can be an all-in-one server for smaller systems, and the basic workhorse system for more complex configurations. The largest and most complex DW/BI systems will need one or more high-performance systems sold directly by the major hardware vendors . The operating system and SQL Server software are so similar between 32-bit and 64-bit hardware that the management of 64-bit systems is not a huge additional burden . We find no compelling reason to use 32-bit hardware, unless youre doing a proof of concept on a shoestring.
Monolithic or Distributed?
An all-in-one configuration is appealing for the cost conscious: Youll minimize operating system and SQL Server licensing costs, and one server is easiest to manage. If you decide to distribute your system, the first way to do so is by putting one or more SQL Server components onto separate servers. This architecture is much easier to manage than distributing the load by the business process dimensional model, placing all the server components for each dimensional model on a different machine. You need a high-bandwidth network between the DW/BI system servers, as significant volumes of data are shipped back and forth between the components.
The all-in-one configuration illustrated in Figure 4.3 has all server components, including possibly SharePoint Portal Services as a reporting portal, running on a single machine. Most users ( clients ) will access the DW/BI system by connecting to Reporting Services, either directly or through SharePoint. Some analytic business users will connect directly to Analysis Services or the relational database for ad hoc and complex analyses.
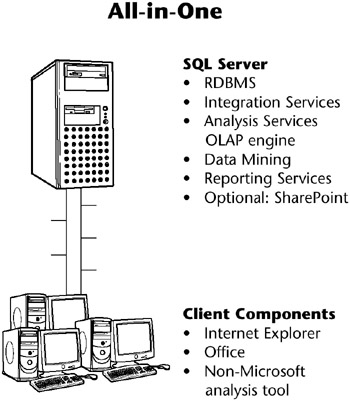
Figure 4.3: All-in-one business intelligence system
Figure 4.4 illustrates a common step up from the all-in-one configuration by creating a reporting server. Consider this configuration if your business users make heavy use of standardized reports built primarily from Analysis Services, and your DW/BI system processing occurs at night when users are not on the system. In this configuration, the Reporting Services catalog database will probably work best on the reporting server, although it could be placed on the SQL Server database server. In the reporting server configuration, some business users access the SQL Server data store directly.
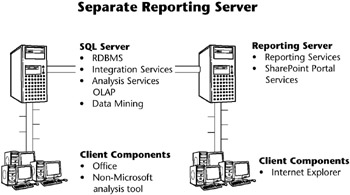
Figure 4.4: SQL Server data store and separate reporting server
If your system is allowed only a relatively short downtime, you should separate Analysis Services from the relational database, as pictured in Figure 4.5. In this configuration, the ETL process will not compete with Analysis Services queries, most of which will use the data cache on the Reporting and Analysis server. The Reporting Services catalog, located on the data store server, will compete with the ETL process for resources, but this is almost certainly better than having it compete with the reporting and analysis services. This configuration is not appropriate for a very high availability operation, which requires the use of clusters as discussed later in this chapter.
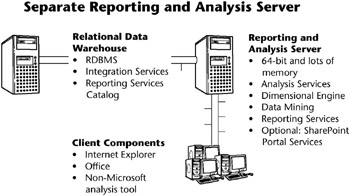
Figure 4.5: SQL Server data store and reporting and analysis server
As your system grows larger and places more demands on the hardware, you may end up at the logical end point: with each SQL Server component on its own server. Each of the chapters about the different components discusses some of the issues around distributing the system. But in general there is no built-in assumption that any two of the components are co-located on a single physical server.
You can even push the SQL Server architecture past the point of one server per component. Analysis Services can distribute the partitions of an OLAP database across multiple serversa feature that was available in SQL Server 2000, although it was seldom used. Reporting Services can run on a web farm, which can greatly enhance scalability. Your network of Integration Services packages can also be distributed across multiple servers, although we expect only the most extreme ETL problems would need to use this architecture.
After youve reached the limit of distributing the SQL Server components to multiple machines, you can think about partitioning along the lines of business process dimensional models. Usually, when a DW/BI system is distributed throughout the organization, its for political rather than performance reasons. Only for really large systems is it technically necessary to partition the DW/BI system along dimensional model boundaries. Also, various components may employ varying approaches to achieve uptime guarantees . We discuss how to make a horizontally distributed system work, but we prefer and recommend a more centralized architecture.
In the development environment, a common configuration is for developers to use a shared instance of the relational database and Analysis Services database on a two- or four-processor server. Some developers may also choose to run local instances of the database servers, in order to experiment in isolation from their colleagues.
What Kind of Storage System?
There are two kinds of storage systems to consider for your DW/BI system: Storage Area Network (SAN), or directly attached storage. You should plan to use RAID to provide some data redundancy whether you use a SAN or direct disk. We discuss alternative RAID configurations in the following section.
RAID
Almost all DW/BI system servers use a Redundant Array of Independent Disks (RAID) storage infrastructure. RAID-1, also known as mirroring, makes a complete copy of the disk. RAID-0+1, also known as a mirror of stripes, uses two RAID-0 stripes , with a RAID-1 mirror over top. RAID-1 and RAID-0+1 are used for replicating and sharing data among disks. They are the configurations of choice for performance-critical, fault-tolerant environments, but require 100 percent duplication of disks. RAID-1 has the same write performance as single disks, and twice the read performance. RAID-5s read performance is good, but its write performance suffers in comparison to RAID-1.
The RAID array needs to be managed, either by hardware or by software. A wide variety of hardware RAID-controlling technologies are available, including the Fibre Channel used by many SAN solutions. Use hardware to control the RAID. If you let the operating system control the RAID, those activities will compete with the operation and performance of the DW/BI system.
Dont skimp on the quality and quantity of the hardware controllers. To maximize performance you may need multiple controllers; work with your storage vendor to develop your requirements and specifications.
Storage Area Networks
The best, although most expensive, approach is to use a Storage Area Network (SAN). A SAN is strongly recommended for large DW/BI systems and for high availability systems. SAN disks can be configured in a RAID array.
A storage area network is defined as a set of interconnected servers and devices such as disks and tapes, which are connected to a common communication and data transfer infrastructure such as Fibre Channel. SANs allow multiple servers access to a shared pool of storage. The SAN management software coordinates security and access. Storage area networks are designed to be low-latency and high-bandwidth storage that is easier to manage than nonshared storage.
A SAN environment provides the following benefits:
-
Centralization of storage into a single pool: Storage is dynamically assigned from the pool as and when it is required, without complex reconfiguring.
-
Simplified management infrastructure.
-
Data can be transferred directly from device to device without server intervention: For example, data can be moved from a disk to a tape without first being read into the memory of a backup server.
These benefits are valuable to a DW/BI system environment. As the DW/BI system grows, its much easier to allocate storage as required. For very large systems, a direct copy of the database files at the SAN level is the most effective backup technique. Finally, SANs play an important role in a DW/BI system with high availability requirements.
| Note | Directly attached RAID disks can offer better performance than SANs, particularly for sequential I/O. However, the advantages of the SAN technology usually, although not always, outweigh the difference in performance for DW/BI applications. |
Processors
To make a gross generalization, DW/BI systems are more likely to hit bottlenecks in memory or I/O than in processing power. However, all of the SQL Server components individually are designed for parallelism, so systems will benefitoften significantlyfrom additional processors. Its hard to imagine anyone taking the time to build a DW/BI system that wouldnt at least benefit from a dual processor box, and most systems use four or more processors.
The additional processing capacity that comes from the 64-bit platform can be very useful. As weve already discussed, the greatest benefit of 64-bit comes from its ability to address very large memory.
Setting Up for High Availability
What does high availability mean for a DW/BI system? The answer, as you might expect, lies with the business users requirements. The job of the DW/BI team is to gather requirements, evaluate and price technical options, and present the business sponsor with a recommendation and cost justification.
Relatively few DW/BI teams deliver 24x7 availability for the entire DW/BI system. Very high availability for the entire system is most common for multinational companies with business users spread throughout the globe. Even so, extremely high availability is seldom a mandate . If you move your DW/BI system to real time, youll need to design more rigorously for high availability. Typically, although not always, real time affects a relatively small set of the data, and the high availability requirements might not affect the bulk of data and operations.
For most DW/BI systems, the business users are happy to use the system from approximately 7 or 8 a.m. to 10 p.m. local time. A DW/BI system thats used primarily for strategic and tactical decision making can tolerate an occasional downtime during the day.
No matter what your availability requirements, the most important thing that you can do is use redundant storage for all your data. As described previously, disk mirroring with a RAID-1 technology is best, but RAID-5 is acceptable for many situations. Disk failure is far more common than other types of system failures; its a good thing that redundant storage is so easy and inexpensive.
It may be necessary to cluster your Analysis Services and relational database servers in order to deliver the highest availability. A properly configured cluster can provide failover in the event of an emergency. A cluster can also provide scalability under normal circumstances. You can run Reporting Services in a web farm configuration, which provides similar advantages for both scalability and availability for that portion of your DW/BI system. SQL Server Books Online provides clear instructions for clustering databases and installing Reporting Services on a web farm. But if high availability is mission critical, you should seriously consider contacting Microsoft for references to highly qualified consultants who can help with the system design and configuration.
| Reference | See the SQL Server Books Online topic How to: Configure a Report Server Scale-Out Deployment (Reporting Services Configuration). |
For the vast gray area between needing 24x7 availability and having an 8- hour load window, there are a lot of things that you can do to minimize the systems downtime. The easiest thing to do is to use Analysis Services as the primary or only presentation server. The heavy lifting of the ETL processing occurs in Integration Services and in the relational database. Once the data is cleaned and conformed, the process of performing an incremental OLAP database update is generally quite fast. And even better, Analysis Services performs updates into a shadow partition so the database remains open for querying during processing. You cant expect query performance to remain at quite the same level while the database is being processed , but in most cases you can schedule the update at a time when the system is lightly used.
Even if you use the relational data warehouse database to support queries and reports, you can minimize the amount of downtime. Dimension updates are seldom the problem; its the fact table inserts and especially updates, for example for a rolling snapshot fact table, which are most problematic . As we discuss later in this chapter, you can use partitioned fact tables to load current data without affecting the availability of yesterdays fact table. If your fact table is small and youre not using partitioning, you can use a similar technique to perform inserts and updates on a copy of yesterday s fact table, and then quickly switch it into production with an extremely short downtime. See the Partitioned Fact Tables section later in this chapter for a longer description of this technique.
| Note | Partitioning for Analysis Services and relational databases are features of SQL Server 2005 Enterprise Edition. These features are not available in Standard Edition. |
If you need very high availability for the relational data warehouse database, you may need to use the database snapshot feature. Users would query the snapshot while the underlying database is being loaded. This approach is most likely to be useful for those delivering 24-hour access to a global enterprise.
| | ||
| | ||
| | ||
EAN: N/A
Pages: 125