Chapter 6. DB2 Indexes
| < Day Day Up > |
| IN THIS CHAPTER
You can create indexes on DB2 table columns to speed up query processing. An index uses pointers to actual data to more efficiently access specific pieces of data. Once created, DB2 automatically maintains each index as data is added, modified, and deleted from the table. As data is selected from the table DB2 can choose to use the index to access the data more efficiently . It is important to remember that index modification and usage is automatic ”you do not need to tell DB2 to modify indexes as data changes nor can you tell DB2 to use a particular index to access data. This automation and separation makes it easy to deploy DB2 indexes. To illustrate how an index works think about the index in this book. If you are trying to find a reference to a particular term in this large book, you can look up the word in the index ”which is arranged alphabetically . When you find the word in the index, one or more page numbers will be listed after the word. These numbers point to the actual pages in the book where information on the term can be found. Just like using a book's index can be much faster than sequentially flipping through each page of a book, using a DB2 index can be much faster than sequentially accessing every page in a table. And, just like the book index, an index is only useful if the term you seek has been indexed. An index is a balanced B-tree structure that orders the values of columns in a table. When you index a table by one or more of its columns, you can access data directly and more efficiently because the index is ordered by the columns to be retrieved. Figure 6.1 depicts a simple b-tree index structure. By following the index tree structure data can be more rapidly accessed than by sequentially scanning all of the rows of the table. For example, a four level index (such as the one shown in the figure) can locate indexed data with 5 I/Os ”one for each of the four levels and an additional read to the data page. This is much more efficient than a table scan which would have to access each table space page, of which there may be hundreds, thousands, or even millions depending on the size of the table. Figure 6.1. Conceptual diagram of a B-tree index structure.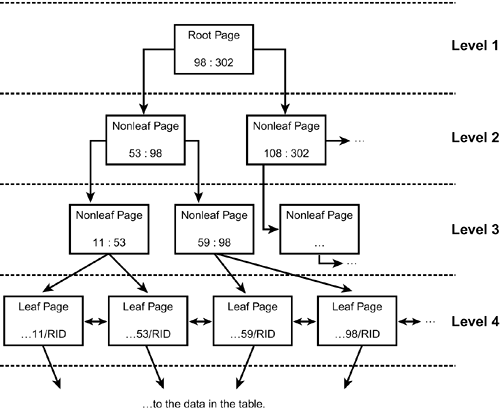 There are 3 types of index data pages needed to form the internal index structure used by DB2: root, nonleaf, and leaf pages. The root page is the starting point of the search through an index. It is always at the top of the index structure and physically it is stored as the third page in the index space (after the header page and the space map page). Entries are made up of the key and RID of the highest key value contained in each page on the level below it. A RID is an internal pointer that uniquely identifies each row to DB2. The RID is made up of:
So, DB2 index entries are made up of a key and a RID. But when multiple rows exist with the same key value, the index entry will contain a single key followed by chain of RIDs. Nonleaf pages are index pages that point to other index pages. When the number of levels in an index reaches 3, the middle level will be this type of page. Prior to the index reaching 3 levels, there are no nonleaf pages in the internal index structure (just a root page that points to leaf pages). Entries in nonleaf pages are made up of the key and RID of the highest key value contained in each page on the level below it. Leaf pages contain key/RID combinations that point to actual user data rows. Let's clarify these points by examining the simplified index structure in Figure 6.1 a little more closely. Suppose we wanted to find a row containing the value 59 using this index. Starting at the top we follow the left path because 59 is less than 98. Then we go right because 59 falls between 53 and 98. Then we follow the link to the leaf page containing 59. Leaf pages are at the bottom-most level of an index (level four in this case). Each leaf page contains indexed values followed by one or more RIDs. More details on the structure and makeup of DB2 indexes, including index page layouts, is provided in Chapter 20, "DB2 Behind the Scenes." |
| < Day Day Up > |
EAN: 2147483647
Pages: 388