XML and ADO.NET
 | |||||||||||
| Chapter 11 - Manipulating XML | |
| bySimon Robinsonet al. | |
| Wrox Press 2002 | |
XML is the glue that binds ADO.NET to the rest of the world. ADO.NET was designed from the ground up to work within the XML environment. XML is used to transfer the data to and from the data store and the application or web page. Since ADO.NET uses XML as the transport in remoting scenarios, data can be exchanged with applications and systems that are not even aware of ADO.NET. Because of the importance of XML in ADO.NET, there are some powerful features in ADO.NET that allow the reading and writing of XML documents. The System.Xml namespace also contains classes that can consume or utilize ADO.NET relational data.
Converting ADO.NET Data to XML
The first example that we are going to look at uses ADO.NET, streams, and XML to pull some data from the Northwind database into a DataSet , load an XmlDocument object with the XML from the DataSet , and load the XML into a listbox. In order to run the next few examples, you need to add the following using statements:
using System.Data; using System.Xml; using System.Data.SqlClient; using System.IO;
Since we will be using XmlDocument , we also need to add the following at the module level:
private XmlDocument doc = new XmlDocument(); Also, for the ADO.NET samples we have added a DataGrid to the forms. This will allow us to see the data in the ADO.NET DataSet since it is bound to the grid, as well as the data from the generated XML documents that we load in the listbox. Here is the code for the first example, which can be found in the ADOSample1 folder:
private void button1_Click(object sender, System.EventArgs e) { //create a dataset DataSet ds = new DataSet("XMLProducts"); //connect to the northwind database and //select all of the rows from products table //make sure your login matches your version of SqlServer SqlConnection conn = new SqlConnection (@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind"); SqlDataAdapter da = new SqlDataAdapter("SELECT * FROM Products",conn);
After we create the SqlDataAdapter , da , and the DataSet , ds , we instantiate a MemoryStream object, a StreamReader object, and a StreamWriter object. The StreamReader and StreamWriter objects will use the MemoryStream to move the XML around:
MemoryStream memStrm=new MemoryStream(); StreamReader strmRead=new StreamReader(memStrm); StreamWriter strmWrite=new StreamWriter(memStrm);
We will use a MemoryStream so that we don't have to write anything to disk, however, we could have used any object that was based on the Stream class such as FileStream . Next, we fill the DataSet and bind it to the DataGrid . The data in the DataSet will now be displayed in the DataGrid :
da.Fill(ds,"products"); //load data into DataGrid dataGrid1.DataSource=ds; dataGrid1.DataMember="products";
This next step is where the XML is generated. We call the WriteXml() method from the DataSet class. This method generates an XML document. There are two overloads to WriteXml() : one takes a string with the file path and name , and the other adds a mode parameter. This mode is an XmlWriteMode enumeration, with possible values:
-
IgnoreSchema
-
WriteSchema
-
DiffGram
IgnoreSchema is used if you don't want WriteXml() to write an inline schema at the start of your XML file; use the WriteSchema parameter if you do want one. We will look at DiffGram s later in the section.
ds.WriteXml(strmWrite,XmlWriteMode.IgnoreSchema); memStrm.Seek(0,SeekOrigin.Begin); //read from the memory stream to an XmlDocument object doc.Load(strmRead); //get all of the products elements XmlNodeList nodeLst=doc.GetElementsByTagName("ProductName"); //load them into the list box foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerText); } private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e) { //when you click on the listbox, //a message box appears with the unit price string srch="XMLProducts/products[ProductName=" + '"'+ listBox1.SelectedItem.ToString() + '"' + "]"; XmlNode foundNode=doc.SelectSingleNode(srch); if(foundNode!=null) MessageBox.Show(foundNode.SelectSingleNode("UnitPrice").InnerText); else MessageBox.Show("Not found"); }
Here is a screenshot, so you can see the data in the list as well as the bound DataGrid :
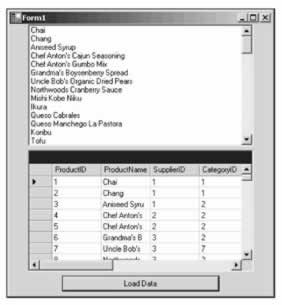
If we had only wanted the schema, we could have called WriteXmlSchema() instead of WriteXml() . This method has four overloads. One takes a string, which is the path and file name of where to write the XML document. The second overload uses an object that is based on the XmlWriter class. The third overload uses an object that is based on the TextWriter class. The fourth overload is the one that we used in the example and is derived from the Stream class.
Also, if we wanted to persist the XML document to disk, we would have used something like this:
string file = "c:\test\product.xml"; ds.WriteXml(file);
This would give us a well- formed XML document on disk that could be read in by another stream, or by DataSet , or used by another application or web site. Since no XmlMode parameter is specified, this XmlDocument would have the schema included. In our example, we use the stream as a parameter to the XmlDocument.Load() method.
Once the XmlDocument is prepared, we load the listbox using the same XPath statement that we used before. If you look closely, you'll see that we changed the listBox1_SelectedIndexChanged() event slightly. Instead of showing the InnerText of the element, we do another XPath search using SelectSingleNode() to get the UnitPrice element. So now every time you click on a product in the listbox, a MessageBox appears with the UnitPrice . We now have two views of the data, but more importantly, we can manipulate the data using two different models. We can use the System.Data namespace to use the data or we can use the System.Xml namespace on the data. This can lead to some very flexible designs in your applications, because now you are not tied to just one object model to program with. This is the real power to the ADO.NET and System.Xml combination. You have multiple views of the same data, and multiple ways to access the data.
In the next example we will simplify the process by eliminating the three streams and by using some of the ADO capabilities built into the System.Xml namespace. We will need to change the module-level line of code:
private XmlDocument doc = new XmlDocument(); to:
private XmlDataDocument doc; We need this because we are now going to be using the XmlDataDocument . Here is the code, which can be found in the ADOSample2 folder:
private void button1_Click(object sender, System.EventArgs e) { //create a dataset DataSet ds=new DataSet("XMLProducts"); //connect to the northwind database and //select all of the rows from products table //make changes to connect string to match your login and server name SqlConnection conn=new SqlConnection (@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind"); SqlDataAdapter da=new SqlDataAdapter("SELECT * FROM products",conn); //fill the dataset da.Fill(ds,"products"); //load data into grid dataGrid1.DataSource=ds; dataGrid1.DataMember="products"; doc=new XmlDataDocument(ds); //get all of the products elements XmlNodeList nodeLst=doc.GetElementsByTagName("ProductName"); //load them into the list box //we'll use a for loop this time for(int ctr=0;ctr<nodeLst.Count;ctr++) listBox1.Items.Add(nodeLst[ctr].InnerText); } As you can see, the code to load the DataSet into the XML document has been simplified. Instead of using the XmlDocument class, we are using the XmlDataDocument class. This class was built specifically for using data with a DataSet object.
The XmlDataDocument is based on the XmlDocument class, so it has all of the functionality that the XmlDocument class has. One of the main differences is the overloaded constructor that the XmlDataDocument has. Note the line of code that instantiates the XmlDataDocument ( doc ):
doc = new XmlDataDocument(ds);
It passes in the DataSet that we created, ds , as a parameter. This creates the XML document from the DataSet , and we don't have to use the Load() method. In fact, if you instantiate a new XmlDataDocument object without passing in a DataSet as the parameter, it will contain a DataSet with the name NewDataSet that has no DataTables in the tables collection. There is also a DataSet property that you can set after an XmlDataDocument based object is created.
Say the following line of code is added after the DataSet.Fill() call:
ds.WriteXml("c:\test\sample.xml", XmlWriteMode.WriteSchema); In this case, the following XML file, sample.xml , is produced in the folder c:\test :
<?xml version="1.0" standalone="yes"?> <XMLProducts> <xs:schema id="XMLProducts" xmlns="" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"> <xs:element name="XMLProducts" msdata:IsDataSet="true"> <xs:complexType> <xs:choice maxOccurs="unbounded"> <xs:element name="products"> <xs:complexType> <xs:sequence> <xs:element name="ProductID" type="xs:int" minOccurs="0" /> <xs:element name="ProductName" type="xs:string" minOccurs="0" /> <xs:element name="SupplierID" type="xs:int" minOccurs="0" /> <xs:element name="CategoryID" type="xs:int" minOccurs="0" /> <xs:element name="QuantityPerUnit" type="xs:string" minOccurs="0" /> <xs:element name="UnitPrice" type="xs:decimal" minOccurs="0" /> <xs:element name="UnitsInStock" type="xs:short" minOccurs="0" /> <xs:element name="UnitsOnOrder" type="xs:short" minOccurs="0" /> <xs:element name="ReorderLevel" type="xs:short" minOccurs="0" /> <xs:element name="Discontinued" type="xs:boolean" minOccurs="0" /> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema> <products> <ProductID>1</ProductID> <ProductName>Chai</ProductName> <SupplierID>1</SupplierID> <CategoryID>1</CategoryID> <QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit> <UnitPrice>18</UnitPrice> <UnitsInStock>39</UnitsInStock> <UnitsOnOrder>0</UnitsOnOrder> <ReorderLevel>10</ReorderLevel> <Discontinued>false</Discontinued> </products> </XMLProducts>
Only the first products element is shown. The actual XML file would contain all of the products in the Products table of Northwind database.
Converting Relational Data
This looks simple enough for a single table, but what about relational data, such as multiple DataTable s and Relations in the DataSet ? It all still works the same way. Let's make the following changes to the code that we've been using (this version can be found in ADOSample3 ):
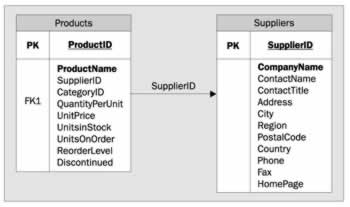
private void button1_Click(object sender, System.EventArgs e) { //create a dataset DataSet ds=new DataSet("XMLProducts"); //connect to the northwind database and //select all of the rows from products table and from suppliers table //make sure your connect string matches your server configuration SqlConnection conn=new SqlConnection (@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind"); SqlDataAdapter daProd=new SqlDataAdapter("SELECT * FROM products",conn); SqlDataAdapter daSup=new SqlDataAdapter("SELECT * FROM suppliers",conn); //Fill DataSet from both SqlAdapters daProd.Fill(ds,"products"); daSup.Fill(ds,"suppliers"); //Add the relation ds.Relations.Add(ds.Tables["suppliers"].Columns["SupplierId"], ds.Tables["products"].Columns["SupplierId"]); //Write the XML to a file so we can look at it later ds.WriteXml("..\..\..\SuppProd.xml",XmlWriteMode.WriteSchema); //load data into grid dataGrid1.DataSource=ds; dataGrid1.DataMember="suppliers"; //create the XmlDataDocument doc=new XmlDataDocument(ds); //Select the productname elements and load them in the grid XmlNodeList nodeLst=doc.SelectNodes("//ProductName"); foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml); } In this sample we are creating two DataTable s in the XMLProducts DataSet : Products and Suppliers . The relation is that Suppliers supply Products . We create a new relation on the column SupplierId in both tables. This is what the DataSet looks like:
By making the same WriteXml() method call that we did in the previous example, we will get the following XML file ( SuppProd.xml ):
<?xml version="1.0" standalone="yes"?> <XMLProducts> <xs:schema id="XMLProducts" xmlns="" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"> <xs:element name="XMLProducts" msdata:IsDataSet="true"> <xs:complexType> <xs:choice maxOccurs="unbounded"> <xs:element name="products"> <xs:complexType> <xs:sequence> <xs:element name="ProductID" type="xs:int" minOccurs="0" /> <xs:element name="ProductName" type="xs:string" minOccurs="0" /> <xs:element name="SupplierID" type="xs:int" minOccurs="0" /> <xs:element name="CategoryID" type="xs:int" minOccurs="0" /> <xs:element name="QuantityPerUnit" type="xs:string" minOccurs="0" /> <xs:element name="UnitPrice" type="xs:decimal" minOccurs="0" /> <xs:element name="UnitsInStock" type="xs:short" minOccurs="0" /> <xs:element name="UnitsOnOrder" type="xs:short" minOccurs="0" /> <xs:element name="ReorderLevel" type="xs:short" minOccurs="0" /> <xs:element name="Discontinued" type="xs:boolean" minOccurs="0" /> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="suppliers"> <xs:complexType> <xs:sequence> <xs:element name="SupplierID" type="xs:int" minOccurs="0" /> <xs:element name="CompanyName" type="xs:string" minOccurs="0" /> <xs:element name="ContactName" type="xs:string" minOccurs="0" /> <xs:element name="ContactTitle" type="xs:string" minOccurs="0" /> <xs:element name="Address" type="xs:string" minOccurs="0" /> <xs:element name="City" type="xs:string" minOccurs="0" /> <xs:element name="Region" type="xs:string" minOccurs="0" /> <xs:element name="PostalCode" type="xs:string" minOccurs="0" /> <xs:element name="Country" type="xs:string" minOccurs="0" /> <xs:element name="Phone" type="xs:string" minOccurs="0" /> <xs:element name="Fax" type="xs:string" minOccurs="0" /> <xs:element name="HomePage" type="xs:string" minOccurs="0" /> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> <xs:unique name="Constraint1"> <xs:selector xpath=".//suppliers" /> <xs:field xpath="SupplierID" /> </xs:unique> <xs:keyref name="Relation1" refer="Constraint1"> <xs:selector xpath=".//products" /> <xs:field xpath="SupplierID" /> </xs:keyref> </xs:element> </xs:schema> <products> <ProductID>1</ProductID> <ProductName>Chai</ProductName> <SupplierID>1</SupplierID> <CategoryID>1</CategoryID> <QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit> <UnitPrice>18</UnitPrice> <UnitsInStock>39</UnitsInStock> <UnitsOnOrder>0</UnitsOnOrder> <ReorderLevel>10</ReorderLevel> <Discontinued>false</Discontinued> </products> <suppliers> <SupplierID>1</SupplierID> <CompanyName>Exotic Liquids</CompanyName> <ContactName>Charlotte Cooper</ContactName> <ContactTitle>Purchasing Manager</ContactTitle> <Address>49 Gilbert St.</Address> <City>London</City> <PostalCode>EC1 4SD</PostalCode> <Country>UK</Country> <Phone>(171) 555-2222</Phone> </suppliers> </XMLProducts>
The schema includes both DataTable s that were in the DataSet . In addition, the data includes all of the data from both tables. For the sake of brevity, we only show the first suppliers and products records here. As before we could have saved just the schema or just the data by passing in the correct XmlWriteMode parameter.
Converting XML to ADO.NET Data
Let's say that you have an XML document that you would like to get into an ADO.NET DataSet . You would want to do this so you could load the XML into a database, or perhaps bind the data to a .NET data control such as DataGrid . This way you could actually use the XML document as your data store, and could eliminate the overhead of the database altogether. If your data is reasonably small in size , then this is an attractive possibility. Here is some code to get you started ( ADOSample4 ):
private void button1_Click(object sender, System.EventArgs e) { //create a new DataSet DataSet ds=new DataSet("XMLProducts"); //read in the XML document to the Dataset ds.ReadXml("..\..\..\prod.xml"); //load data into grid dataGrid1.DataSource=ds; dataGrid1.DataMember="products"; //create the new XmlDataDocument doc=new XmlDataDocument(ds); //load the product names into the listbox XmlNodeList nodeLst=doc.SelectNodes("//ProductName"); foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml); } It is that easy. We instantiate a new DataSet object. Then we call the ReadXml() method, and you now have XML in a DataTable in your DataSet . As with the WriteXml() methods , ReadXml() has an XmlReadMode parameter. ReadXml() has a couple more options in the XmlReadMode too. This table describes them:
| Value | Description |
|---|---|
| Auto | Sets the XmlReadMode to the most appropriate setting. If data is in DiffGram format, DiffGram is selected. If a schema has already been read, or an inline schema is detected , then ReadSchema is selected. If no schema has been assigned to the DataSet , and none is detected inline, then IgnoreSchema is selected. |
| DiffGram | Reads in the DiffGram and applies the changes to the DataSet . DiffGrams are described later in the chapter. |
| Fragment | Reads documents that contain XDR schema fragments , such as the type created by SQL Server. |
| IgnoreSchema | Ignores any inline schema that may be found. Reads data into the current DataSet schema. If data does not match DataSet schema it is discarded. |
| InferSchema | Ignores any inline schema. Creates the schema based on data in the XML document. If a schema exists in the DataSet , that schema is used, and extended with additional columns and tables if needed. An exception is thrown if a column exists, but is of a different data type. |
| ReadSchema | Reads the inline schema and loads the data. Will not overwrite a schema in the DataSet , but will throw an exception if a table in the inline schema already exists in the DataSet . |
There is also the ReadXmlSchema() method. This will read in a standalone schema and create the tables, columns, and relations accordingly . You would use this if your schema is not inline with your data. ReadXmlSchema() has the same four overloads: string with file and path name, Stream -based object, TextReader -based object and an XmlReader -based object.
To show that the data tables are getting created properly, let's load the XML document that contains the Products and Suppliers tables that we used in an earlier example. This time however, let's load the listbox with the DataTable names and the DataColumn names and data types. We can look at this and compare it back to the original Northwind database to see that all is well. Here is the code that we will use, which can be found in ADOSample5 :
private void button1_Click(object sender, System.EventArgs e) { //create the DataSet DataSet ds=new DataSet("XMLProducts"); //read in the XML document ds.ReadXml("..\..\..\SuppProd.xml"); //load data into grid dataGrid1.DataSource=ds; dataGrid1.DataMember="products"; //load the listbox with table, column and datatype info foreach(DataTable dt in ds.Tables) { listBox1.Items.Add(dt.TableName); foreach(DataColumn col in dt.Columns) { listBox1.Items.Add( '\t' + col.ColumnName + " - " + col.DataType.FullName); } } } Note the addition of the two foreach loops . The first loop is getting the table name from each table in the Tables collection of the DataSet . Inside the inner foreach loop we get the name and data type of each column in the DataTable . We load this data into the listbox, allowing us to display it. Here is a screenshot of the output:
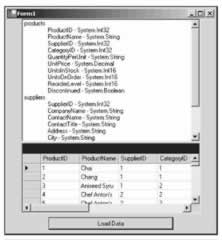
Looking at the listbox you can check that the DataTables were created with the columns all having the correct names and data types.
Something else you may want to note is that since the last two examples didn't transfer any data to or from a database, no SqlDataAdapter or SqlConnection was defined. This shows the real flexibility of both the System.Xml namespace and ADO.NET: you can look at the same data in multiple formats. If you need to do a transform and show the data in HTML format, or if you need to bind to a grid, you can take the same data, and with just a method call, have it in the required format.
Reading and Writing a DiffGram
A DiffGram is an XML document that contains the before and after data of an edit session. This can include any combination of data changes, additions, and deletions. A DiffGram can be used as an audit trail or for a commit/rollback process. Most DBMS systems today have this built in, but if you happen to be working with a DBMS that does not have these features or if XML is your data store and you do not have a DBMS, you can implement commit/rollback features yourself.
Let's see some code that shows how a DiffGram is created and how a DataSet can be created from a DiffGram (this code can be found in the ADOSample6 folder).
The beginning part of this code should look familiar. We define and set up a new DataSet , ds , a new SqlConnection , conn , and a new SqlDataAdapter , da . We connect to the database, select all of the rows from the Products table, create a new DataTable named products , and load the data from the database into the DataSet :
private void button1_Click(object sender, System.EventArgs e) { //new DataSet DataSet ds=new DataSet("XMLProducts"); //Make connection and load products rows SqlConnection conn=new SqlConnection (@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind"); SqlDataAdapter da=new SqlDataAdapter("SELECT * FROM products",conn); //fill the DataSet da.Fill(ds,"products"); //edit first row ds.Tables["products"].Rows[0]["ProductName"]="NewProdName"; In this next code block we do two things. First, we modify the ProductName column in the first row to NewProdName . Second, we create a new row in the DataTable , set the column values, and finally add the new data row to the DataTable .
//add new row DataRow dr=ds.Tables["products"].NewRow();; dr["ProductId"]=100; dr["CategoryId"]=2; dr["Discontinued"]=false; dr["ProductName"]="This is the new product"; dr["QuantityPerUnit"]=12; dr["ReorderLevel"]=1; dr["SupplierId"]=12; dr["UnitPrice"]=23; dr["UnitsInStock"]=5; dr["UnitsOnOrder"]=0; ds.Tables["products"].Rows.Add(dr);
The next block is the interesting part of the code. First, we write out the schema with WriteXmlSchema() . This is important because you cannot read back in a DiffGram without the schema. WriteXml() with the XmlWriteMode.DiffGram parameter passed to it actually creates the DiffGram . The next line accepts the changes that we made. It is important that the DiffGram is created before calling AcceptChanges() , otherwise there would not appear to be any modifications to the data.
//Write the Schema ds.WriteXmlSchema("..\..\..\diffgram.xsd"); //generate the DiffGram ds.WriteXml("..\..\..\diffgram.xml",XmlWriteMode.DiffGram); ds.AcceptChanges(); //load data into grid dataGrid1.DataSource=ds; dataGrid1.DataMember="products"; //new XmlDataDocument doc=new XmlDataDocument(ds); //load the productnames in the list XmlNodeList nodeLst=doc.SelectNodes("//ProductName"); foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml); }
In order to get the data back into a DataSet , we can do the following:
DataSet dsNew=new DataSet(); dsNew.ReadXmlSchema("..\..\..\diffgram.xsd"); dsNew.XmlRead("..\..\..\diffgram.xml",XmlReadMode.DiffGram);
Here we are creating a new DataSet , dsNew . The call to the ReadXmlSchema() method creates a new DataTable based on the schema information. In this case it would be a clone of the products DataTable . Now we can read in the DiffGram . The DiffGram does not contain schema information, so it is important that the DataTable be created and ready before you call the ReadXml() method.
Here is a sample of what the DiffGram ( diffgram.xml ) looks like:
<?xml version="1.0" standalone="yes"?> <diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1"> <XMLProducts> <products diffgr:id="products1" msdata:rowOrder="0" diffgr:hasChanges="modified"> <ProductID>1</ProductID> <ProductName>NewProdName</ProductName> <SupplierID>1</SupplierID> <CategoryID>1</CategoryID> <QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit> <UnitPrice>18</UnitPrice> <UnitsInStock>39</UnitsInStock> <UnitsOnOrder>0</UnitsOnOrder> <ReorderLevel>10</ReorderLevel> <Discontinued>false</Discontinued> </products> ... <products diffgr:id="products78" msdata:rowOrder="77" diffgr:hasChanges="inserted"> <ProductID>100</ProductID> <ProductName>This is the new product</ProductName> <SupplierID>12</SupplierID> <CategoryID>2</CategoryID> <QuantityPerUnit>12</QuantityPerUnit> <UnitPrice>23</UnitPrice> <UnitsInStock>5</UnitsInStock> <UnitsOnOrder>0</UnitsOnOrder> <ReorderLevel>1</ReorderLevel> <Discontinued>false</Discontinued> </products> </XMLProducts> <diffgr:before> <products diffgr:id="products1" msdata:rowOrder="0"> <ProductID>1</ProductID> <ProductName>Chai</ProductName> <SupplierID>1</SupplierID> <CategoryID>1</CategoryID> <QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit> <UnitPrice>18</UnitPrice> <UnitsInStock>39</UnitsInStock> <UnitsOnOrder>0</UnitsOnOrder> <ReorderLevel>10</ReorderLevel> <Discontinued>false</Discontinued> </products> </diffgr:before> </diffgr:diffgram>
Notice how each DataTable row is repeated, and that there is a diffgr:id attribute for each < products > element (we've only shown the first and last of the < products > elements in order to save space). diffgr is the namespace prefix for urn:schemas-microsoft-com:xml-diffgram-v1 . For rows that were modified or inserted, ADO.NET adds a diffgr:hasChanges attribute. There's also a < diffgr:before > element after the < XMLProducts > element, which contains a < products > element indicating the previous contents of any modified rows. Obviously the inserted row didn't have any previous contents, so this doesn't have an element in < diffgr:before >.
After the DiffGram has been read into the DataTable , it is in the state that it would be in after changes were made to the data but before AcceptChanges() is called. At this point you can actually roll back changes by calling the RejectChanges() method. By looking at the DataRow.Item property and passing in either DataRowVersion.Original or DataRowVersion.Current , we can see the before and after values in the DataTable .
If you keep a series of DiffGram s it is important that you are able to reapply them in the proper order. You probably would not want to try to roll back changes for more then a couple of iterations. You could, however use the DiffGram s as a form of logging or for auditing purposes if the DBMS that is being used does not offer these facilities.
EAN: 2147483647
Pages: 244