Section 6.3. Documents
6.3. DocumentsArticles, books, contracts: what is common to them all? How about a song, a weather forecast, a satellite image? Where is the border between data and documents ? In the digital era, at the edges of this family of artifacts, Wittgenstein's wisdom becomes clear. Basic definitions focus on written or printed information that is fixed in form. More sophisticated approaches invoke the centrality of intentionality, embracing a wider circle of less tangible, more mutable expressions of human thought. But all attempts fall short. Like most objects of consequence, the document resists definition; and in this free state, unbound by simple rules, plays an amazing role in our lives. Historically, documents have served as power objects. Receipts and passports prove ownership and identification. Written contracts, charters, certificates, commandments, and constitutions glow with embedded authority. Their legal, moral, and symbolic value sustains our institutions of government, education, and commerce. Modern civilization is unimaginable without these instruments of communication, collaboration, and control. Yet, many have characterized our time as the beginning of the end of documents. Deborah Juhnke, a computer forensics expert, says our "reliance on the document paradigm must change" because from a legal, evidentiary perspective, "the document is dead."[*] And information architect Gene Smith argues "the page is dying as the predominant metaphor for organizing and presenting online information."[
In fact, the document will endure as long as we do, for it is not tied to technology, but like space, time, and hierarchy, is a construct of the human mind. We understand documents. Their familiar design confers ease of use, and their integrated content and structure supports navigation. Documents are the preeminent findable objects. And whether in print or digital form, their success derives largely from their shape. 6.3.1. The Shape of InformationMost declarations of documental demise belie the way we actually unite form, content, and purpose to forge a genre. Technology and medium surely play a role. The affordances of clay, stone, animal skin, plant fiber, and silicon vary widely. And yet, as researchers Kevin Crowston and Marie Williams explain:
Consider the genres that have emerged in the print medium: maps, menus, newspapers, magazines, paperbacks, tri-fold brochures, white papers, and little black books. In theory, all could be printed on standard 8.5 x 11 sheets. We didn't derive these genres from the inherent properties of paper. We designed them for a purpose. Genre responds to use. The unique shape of a receipt helps a user predict value and meaning. What makes us think that XML will suddenly transform information into an amorphous gray goo that flows indiscriminately between containers and channels? We should not be seduced by the siren song of radical reusability whispered in our ears by software vendors. The ability to assemble virtual documents from digital assets on the fly does not render real documents obsolete. Single source publishing works wonders with highly structured content, and simple images, headlines, and legal notices are well-suited to reusability. But most content requires context and structure, and most authors write documents, not chunks. In fact, new genres have already started to appear on the Web, as shown in Figure 6-22: web sites, home pages, sitemaps, FAQs, and blogs are leading indicators of genre shift. And, of course, we've imported and remixed established genres as well. Dictionaries, encyclopedias, and email memos with formal PDF reports attached have all become elements within our evolving genre system in which context can be as meaningful as content. As David Levy notes:
Figure 6-22. Forty-eight genres from 1,000 web pages ("Development of the Genre Concept" by Leen Breure; available at http://www.cs.uu.nl/people/leen/GenreDev/GenreDevelopment.htm)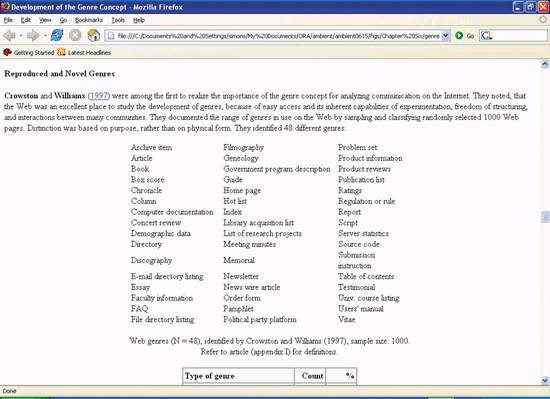 In this sense, digital genre plays a significant role in search and navigation. First, genre supports document findability. Filter by content type, for instance, enables users to limit their search space to press releases, product briefs, or technical reports. Second, genre supports document recognition. Upon viewing a PDF newsletter, users instantly recognize its nature and purpose. Through rapid visual identification, we know when we've found what we need. Third, genre supports navigation within a document. The familiar shape of a scientific document, shown in Figure 6-23, permits rapid scanning. We can review the abstract and then skip right to the results. Interestingly, research has shown that semantics and structure are codependent.[*] Structure contributes to understanding and comprehension, while meaning helps establish a sense of location. Users can tell where they are in a document from the semantic content of individual paragraphs.
Figure 6-23. The shape of a scientific document (image from http://www.ischool.utexas.edu/~adillon/publications/journey.html)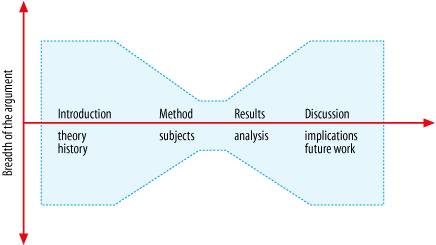 For all these reasons, genre hasn't expired after a decade of web design, and it won't die at the hands of handhelds either. But mobile devices will catalyze further genre shift, as we develop novel forms to fit tiny screens that wander. As Peter Merholz explains "you can't just take any web page, and expect it to work within any device."[
6.3.2. Antelopes as Boundary ObjectsThe next few years will force us to revisit our conception of the document. For even as we struggle to make sense of digital genre, ubicomp will inject growing numbers of physical objects into the category of document. This notion of object as document is nothing new.[
The librarian and documentalist, Suzanne Briet, addressed this extension of meaning in a 1951 manifesto in which she asserts a document is "...evidence in support of a fact...any physical or symbolic sign, preserved or recorded, intended to represent...or to demonstrate a physical or conceptual phenomenon."[
|
 ] "What is a Document?" by Michael Buckland. Available at http://www.sims.berkeley.edu/~buckland/whatdoc.html.
] "What is a Document?" by Michael Buckland. Available at http://www.sims.berkeley.edu/~buckland/whatdoc.html.[*] Adapted from "What is a Document?" by Michael Buckland.
As Michael Buckland explains, Briet's rules for defining when an object becomes a document are not entirely clear, but we can infer several criteria from her discussion:
Intention
Intended to be treated as evidence
Process
Processed or made into a document
Perception
Perceived as a document
Indexing
Organized within a collection of evidence
Both Otlet and Briet were trying to include the natural objects and artifacts of zoos, museums, and libraries, without admitting the entire world into the category of document. It's interesting to review their classifications through the lens of today's technology. Let's consider Briet's antelope, for instance. What if we leave the antelope in the wild, but embed an RFID tag or attach a GPS transponder or assign it a URL? What if our antelope is indexed by Google? What if we can view it via a network of video cameras?
This is not simply an exercise in semantics, for whether we use the word "document" or not, we have already begun adding documental qualities to people, places, and objects. As Bruce Sterling notes, in reference to the "smart object" known as Rafael Macedo de la Concha, Mexico's attorney general who had RFID tags implanted in his arm (and the arms of his staff) in a bid to fight corruption through better tracking and authentication:
It's his brain that makes him smart. It's the chip that makes him an object: cataloged, searchable, and locatable in space and time.[*]
[*] "Dumbing Down Smart Objects" by Bruce Sterling. Wired Magazine, October 2004. Available at http://www.wired.com/wired/archive/12.10/view.html?pg=4.
We're creating a whole new taxonomy of findable objects, and our understanding of the boundary objects we call documents will serve us well in these uncharted territories.
6.3.3. The End of Data
Despite this revolution at the document core, we should not focus solely on the center, for as one might expect of a boundary object, there's serious action at the edges. We're talking about the blurring at the borders between data and metadata, a phenomenon with great relevance to findability. As usual, Mr. Weinberger is on top of this trend. He writes:
There used to be a difference between data and metadata. Data was the suitcase and metadata was the name tag on it....Data was the contents of the book and metadata was the Dewey Decimal number on its spine....[Now], all data is metadata....Data is all surface and no insides. It's all handles and no suitcase. It's a folder whose content is just another label. It's all sticker and no bumper.[
]
] "The End of Data?" by David Weinberger. Available at http://www.hyperorg.com/backissues/joho-oct15-04.html#data.
Amazon .com serves as the archetype for this intertwingling. A book listed on Amazon is far more than the words between its covers. Each record is saturated with a rich blend of semantic and social metadata designed to help you find the book you need. Formal bibliographic notations and subject classifications coexist with popularity, reputation, co-citation analysis, collaborative filtering, and customer reviews. And with Search Inside the Book?, Amazon has turned the page into metadata. Every word is a keyword. Each text is linked to others by a common turn of phrase. Every book enjoys membership in an infinite number of categories in this n-dimensional bookstore that boggles the mind.
But Amazon's novel use of data and metadata for navigation and competitive advantage is only the tip of the iceberg. Bruce Sterling hints at the future in his vision of the location-aware, history-enriched, auto-Googling objects he calls spimes.[*] This idea of history-enriched digital objects draws from the physical world, where dog-eared books, padded doorframes, and worn stairs make interaction history visible.
[*] "When Blobjects Rule the Earth" by Bruce Sterling. SIGGRAPH, Los Angeles, August 2004. Available at http://www.boingboing.net/images/blobjects.htm.
Wear is an emergent property of physical objects that has barely been tapped online. In fact, the markers of previous use have been largely ignored in information science. There is an exception in the rich tradition of "provenance" in archives and record management that emphasizes context over contentarchivists seek to identify the office of origin and the chain of custody, and strive to preserve the "sanctity of original order"maintaining documents as they were originally arranged.[ ] But these archival arrangements have been applied towards evidential value and scholarly understanding, not findability.
] But these archival arrangements have been applied towards evidential value and scholarly understanding, not findability.
] "The Principle of Provenance and Modern Archival Systems by Megan Winget. Available at http://www.unc.edu/~winget/research/provenance.pdf.
For now, the Web is the preeminent sandbox for exploring how interaction history can support social navigation. Popularity and reputation are the most common metrics, and an assortment of high-profile examples illuminate the possibilities:
Google uses the quality and quantity of inbound links as part of a multi-algorithmic solution to derive popularity, reputation, and ultimately relevance.
Technorati lists the Top 100 "most authoritative" blogs ranked by the number of sources that link to each blog.
Newsmap, shown in Figure 6-24, presents a visual representation of Google News that blends hand-picked sources with popularity algorithms to determine "relevance."
The New York Times presents a ranked list of the most emailed articles.
Wikipedia allows us to view a list of the most edited articles, thereby showcasing the more controversial people and topics of our time.
CNET's Download.com lists the most frequently downloaded software.
Amazon converts popular paths in the clickstream into "customers who viewed this item also viewed these items."
Epinions lets users rate products and rate the raters, a system that enables repeat visitors to construct a personal "web of trust."
eBay's auction system relies on reputations for ranking buyer and seller honesty.
Slashdot's metamoderation and "karma" metric define whose articles get read.
Flickr showcases the all time most popular tags, as well as the hot tags in the last 24 hours and over the last week.
And, many home pages list the "most popular" or "most visited" pages for their web sites. What's amazing is how effectively all of this popularity and reputation metadata contributes to widely acceptable definitions of relevance.
Figure 6-24. Newsmap
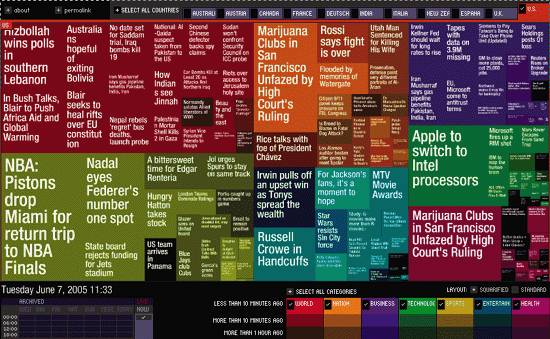
With respect to findability, we're comfortable trusting the wisdom of crowds. And this popularity metadata not only influences which data we find but our respect for that data as well. As studies have shown, "the findability of information biases its perceived quality."[*] Herein lies the dark side to this tyranny of popularity. The rich get richer, or as Barabasi puts it:
[*] "Manifesto for the Reputation Society" by Hassan Masum and Yi-Cheng Zhang in First Monday (2004). Available at http://www.firstmonday.org/issues/issue9_7/masum/.
In real networks linking is never random. Instead, popularity is attractive. Webpages with more links are more likely to be linked to again....Network evolution is governed by the subtle yet unforgiving law of preferential attachment.[
] Barabasi, p. 86.
Of course, the sphere of contextual metadata extends well beyond popularity. Information about who created or edited a document, and what changes were made when by whom, can add value to the document itself. Increasingly, this bundle of data and metadata is an entity in its own right, with practical and legal substance. And, as we venture beyond the Web, spatial and temporal metadata will gain resonance. Some foundational work exists in the domain of personal information management. In the 1980s, Thomas Malone's office organization research showed the method behind the madness of our piles and files, and in particular the role of spatial location in finding and reminding.[] And more recently, researchers at Stanford and Microsoft have explored the application of timelines, temporal landmarks, and spatial memory for document management and retrieval.aboutness.
[
[§] "Milestones in Time: The Value of Landmarks in Retrieving Information from Personal Stores." Available at http://research.microsoft.com/~sdumais/SISLandmarks-Interact2003-final.pdf. Also, "Data Mountain: Using Spatial Memory for Document Management." Available at http://www.microsoft.com/usability/UEPostings/p153-robertson.pdf.
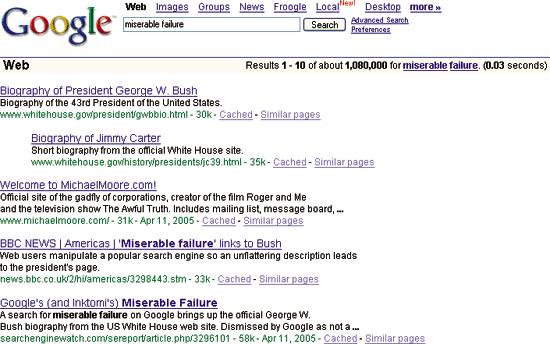
We see this already in the phenomenon of Googlebombing .[**] A search on "miserable failure" returns George W. Bush's presidential biography as the top hit, as demonstrated in Figure 6-25. Now, I can assure you, neither keyword appears within the biography itself. With respect to aboutness, the social campaign of linking overwhelms the semantic content of the page.
[**] Googlebombing is an attempt to influence search result rankings on Google through a concerted campaign of linking a keyword or phrase to a particular target URL. To learn more, see http://en.wikipedia.org/wiki/Googlebomb.
This reflects a fundamental shift in power from author to reader and from authority to popularity that is only just beginning to make waves outside the blogosphere. It will be interesting to follow the fast-developing story of this quiet, global revolution.
Figure 6-25. A famous example of Googlebombing
EAN: 2147483647
Pages: 87