Section 6.2. The Social Life of Metadata
6.2. The Social Life of MetadataTraditionally, librarians and archivists have used the term metadata for "descriptive information used to index, arrange, file, and improve access to a library's or museum's resources."[*] This use derives from the Greek prefix meta, which translates as "with, among, after, or behind." In this sense, metadata accompanies but is not essential to the data itself. The classic example is the card catalog, which employs metadata to enable title, author, and subject access to a library's physical collection of materials. This use dates back to 650 B.C. in Ninevah, when king Assurbanipal constructed a palace library of over 30,000 clay tablets with a crude subject catalog and descriptive bibliography. Of course, broadly defined, metadata is as old as language itself. When we assign names to individuals, places, and possessions, we are tagging those objects with metadata. A library card catalog, shown in Figure 6-2, is a vast collection of metadata.
Metadata has many forms and purposes. Administrative metadata supports document management and workflow. Structural metadata enables single source publishing and flexible display of content. And descriptive metadata permits access and use. Put simply, we employ a word or phrase to describe the subject of a document for the purposes of retrieval. We try to concisely encapsulate its aboutness now to support findability later. It is metadata's ability to help people find what they need that has driven a resurgence of interest, from the ontologies of the Semantic Web to the folksonomies of social software. Despite reaching for different solutions, these Figure 6-2. A traditional library card catalog communities face similar problems. They are using new tools to grapple with the ancient challenges of language, representation, and classification. Unfortunately, they often fail to learn from the past and from one another. These groups rarely talk to one another, and when they do, they speak in different tongues. The state of debate about structure and semantics in cyberspace is reminiscent of the ill-fated Tower of Babel, shown in Figure 6-3. Hopefully, we can use metadata as a boundary object, to foster translation, build shared understanding, and encourage real social progress. Figure 6-3. "The Tower of Babel" by Pieter Brueghel the Elder (Kunsthistorisches Museum, Wein oder KHM, WLEN) 6.2.1. TaxonomiesThe history of metadata is inextricably interwoven with hierarchy, for the organization of ideas and objects into categories and subcategories is fundamental to human experience. We classify to understand. Tree structures, like the one in Figure 6-4, lie at the roots of our consciousness. It is impossible to conceive of intelligence without the parent-child relationship. Figure 6-4. A simple taxonomy In a formal taxonomy, a single root node sits atop the hierarchy. Properties flow from class to subclass through the principle of inheritance. Each object and category is assigned a single location within the taxonomy. We live at an address within a nested hierarchy of streets, cities, states, and countries. We exist as Homo sapiens within the taxa of domain, kingdom, phylum, subphylum, class, order, family, genus, and species. Of course, the world doesn't always cooperate with this Platonic approach to classification. Fish with lungs. Mammals that lay eggs. Documents about multiple topics. Words with many meanings. Meanings with many words. Reality confounds mutually exclusive classifications, and so we find ourselves debating which existing category works best or defining new categories to allow a perfect fit. Lumpers and splitters have been haggling over the Linnaean taxonomy of living things for the past few centuries.[*]
So, aided by the flexibility of digital information systems, we have adapted our strategies to accommodate reality. We permit disciplined polyhierarchy, allowing a limited set of objects and classes to be cross-listed in multiple categories, as shown in Figure 6-5. We embrace faceted classification, shown in Figure 6-6, using multiple fields or "facets" to describe the objects within our collections. First defined in the 1930s by Indian librarian S.R. Ranganathan, faceted classifications have Figure 6-5. Polyhierarchy in Medline flourished in digital domains, where objects can exist simultaneously in many locations. On the Web, we rely on this relational approach to accommodate navigation that varies by user and task. Rather than stuffing content into mutually exclusive buckets, we apply structural and semantic metadata. Figure 6-6. Single hierarchy versus multiple (faceted) hierarchies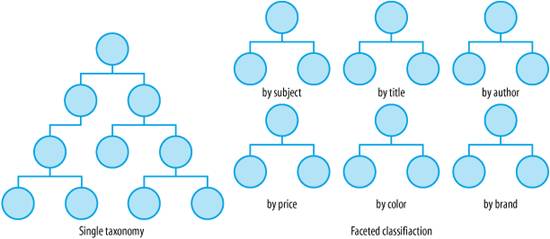 And, we develop controlled vocabularies to manage the ambiguity of language. For our preferred terms, we define equivalence relationships to handle synonyms (variant terms that are equivalent for the purposes of retrieval) and we specify associative relationships to support see also links (often used for cross-sell and up-sell) that lead beyond hierarchy, creating structures like those shown in Figure 6-7. Figure 6-7. Thesaurus terms and relationships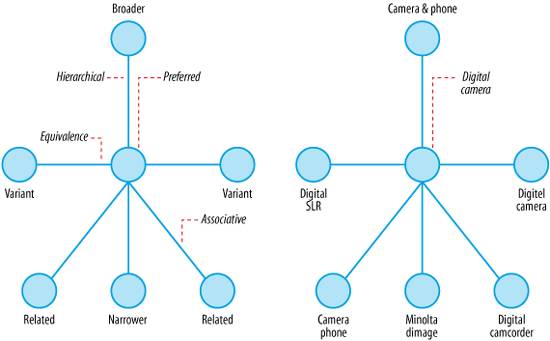 Finally, as information architects, we recognize that by designing these structures, we are not just enabling findability. Classification systems also facilitate understanding, influence identity, and claim authority. Product taxonomies, brand architectures, and enterprise vocabularies are intimately connected to strategy and competitive advantage, as shown in Figure 6-8. And by advancing a particular worldview, all subject taxonomies are inherently political, though not all are as overt or funny as that shown in Figure 6-9. Figure 6-8. Faceted taxonomies at Forrester Research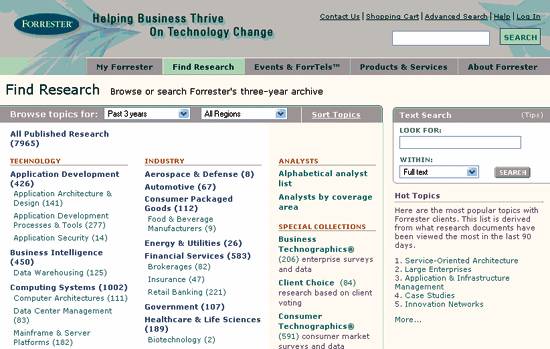 As George Lakoff argues, "There is nothing more basic than categorization to our thought, perception, action, and speech." As we explore the potential of the Semantic Web, we should not leave these lessons of taxonomies hidden in the history of metadata. Figure 6-9. The subject taxonomy of Harpers Magazine (for the story behind the taxonomy, see "A New Website for Harper's Magazine" by Paul Ford at http://www.ftrain.com/AWebSiteForHarpers.html) 6.2.2. OntologiesBut, that's not to say there isn't value in a fresh approach that puts digital objects, computers, and the Internet at the center. After all, it's inevitable that controlled vocabulary standards such as Z39.19, which was first published in 1974, carry some atomic baggage into the time of bits.[*] In contrast, Semantic Web standards are born digital, developed by people with an intimate understanding of code and networks. And to their credit, these folks recognized the mission critical nature of taxonomies from the very beginning. Of course, the classic hierarchical model was overly limiting in a world of bits, so they decided to support the value-added model of ontologies:
Today, the most visible applications of this model are found in Resource Description Framework (RDF), a W3C standard for describing and exchanging metadata. The structure of any expression in RDF is a collection of triples, each consisting of a subject, a predicate, and an object. They are used to make assertions that particular things have properties with certain values. These triples are specified with XML tags. Each is identified by a Universal Resource Identifier (URI) so definitions are unique and widely accessible. This triple storage model , shown in Figure 6-10, provides a powerful and flexible way of defining entities and the relationships between those entities. Figure 6-10. The RDF graph data model of triples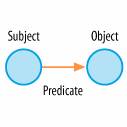 For instance, we can define a formal hierarchical relationship as follows:
But we can just as easily specify equivalence and associative relationships:
In fact, using this model, we can venture beyond the generic associative relationships of traditional thesauri. Triples permit an infinite array of typed relationships. This is an exciting quality of XML and RDF. Support for taxonomies, controlled vocabularies, faceted classifications, and rich semantic relationships is built into the infrastructure. It's an information architect's dream. Even better, findability is part of the stated goal. TBL explains that ontologies can be used "to improve the accuracy of Web searchesthe search program can look for only those pages that refer to a precise concept instead of all the ones using ambiguous keywords."[*] And Tim Bray, coauthor of the XML specification, positions RDF encoding of metadata as "the right way to find things."[
Librarians were quick to see the value. In 1995, the Online Computer Library Center (OCLC) held a joint workshop with the National Center for Supercomputing Applications (NCSA) in Dublin, Ohio to discuss how to use semantic metadata to improve search and retrieval on the Web. These discussions eventually led to the creation of the Dublin Core Metadata Standard, which defines a simple element set for describing networked resources.[
Figure 6-11. Dublin Core in RDF triples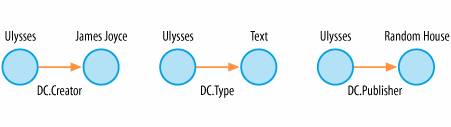 In short, we've got a robust XML infrastructure and a metadata standard carefully crafted to be simple, extensible, and widely applicable across domains. This is an amazing foundation upon which to build applications and leverage vocabularies. So, why have the Semantic Web, RDF, and Dublin Core failed to change the world? Why are they not an integral component of every web project? Why is there a sense of unmet expectations? Some blame the complexity of RDF syntax. Some fault the lofty visions of early evangelists. Others charge the widespread misunderstanding of scope, arguing for a sole focus on machine-machine rather than human-machine or human-human interaction. There is validity to all these claims, and yet the full explanation runs wider and deeper. First, the vast majority of information systems do not warrant the application of structured metadata and controlled vocabularies. Our primary organizing principles are epitomized by piles and files. We pile stuff on our desks and tables and floors, linear graphs in reverse chronological order. And we file stuff in cabinets and folders and directories, simple taxonomies instantiated analogously in atoms and bits. In fact, many of the world's largest corporate web sites still rely primarily on the rudimentary hierarchical model of buckets within buckets. Most of the world will never be ready for the Semantic Web. And we're still waiting for the few that constitute the rest to catch up. Second, and closely related, the design of shared classification systems is surprisingly complex, messy, and expensive. In this sense, it is appropriate that the architects of the Semantic Web chose the term ontology, which in philosophy refers to the branch of metaphysics that studies the nature of reality and the basic categories of existence. What does it mean to exist? What are objects? What attributes are core? This novel vision of knowledge representation is rooted in the ancient theory of Socrates, Plato, and Aristotle. It is this legacy of deductive reasoning and syllogisms that drew Clay Shirky's fire. But as the philosopher Ludwig Wittgenstein argued, the root cause of these ontological challenges lies not only in semantics but also in the underlying logic of classification:
With this simple question, Wittgenstein exposes the fallacy of rules-based definition, and leads us toward the articulation of modern prototype theory best presented in Lakoff's Women, Fire, and Dangerous Things. In short, most categories we employ in everyday life are defined by fuzzy cognitive models rather than objective rules. In the vein of family resemblance, members may be related without sharing any common property. Consequently, we have membership gradience and centrality: some categories have degrees of membership, and some members are better examples than others. As Lakoff attests, the ways we categorize are rooted in language and culture. In fact, the title of his book was inspired by the Australian aboriginal language Dyirbal, which has a category, Balan, that includes women, fire, and dangerous things. It also includes birds that are not dangerous, as well as exceptional animals, such as the platypus, bandicoot, and echidna. In the vocabulary of high tech, localization requires classification as well as translation. In addition, the design of taxonomies and ontologies is inherently political and moral. As Geoffrey Bowker and Susan Leigh Star explain in Sorting Things Out:
There are many ways to label and organize any collection of information. Is Taiwan a country? Is a tomato a vegetable? Where's the line between terrorist and freedom fighter? Do we really care about the subtle distinctions between Syrah, Merlot, and Pinot Noir? Aren't they all just red wines? It depends who you ask. Very few domains are exempt from this complexity of grouping and granularity. Machines may talk precisely with one another, but humans must supply the vocabulary and ultimately derive the value. At the end of the day, the Web, semantic or otherwise, is about human cooperation. Markets are conversations. Hyperlinks subvert hierarchy. The Web is alive. Or at least that's the story you'll hear from the swarms of social software buffs buzzing around the blogosphere. 6.2.3. FolksonomiesSince mob indexing emerged from the ether of social software, it's worth exploring this broad sociotechnical phenomenon before focusing on folksonomies . The notion of people using computers to collaborate can be traced back to 1945 and the memex of Vannevar Bush, which allowed people to share "trails" in hypertext.[
But it wasn't until 2002 that the term came into common usage, sparked by a "Social Software Summit " organized by our friend Clay Shirky, who subsequently published his definition in a brilliant article entitled "Social Software and the Politics of Groups":
While Clay deserves credit as a catalyst, the sublime concentration of reactants made a phase transition inevitable. Blogs, comments, trackback, referrer logs, backward links, PageRank, Daypop, Slashdot, Technorati, Ryze, Friendster, LinkedIn, Wikipedia: an amazing wealth of lightweight tools for personal publishing, interaction, social feedback, conversation discovery, and reputation management had appeared seemingly overnight. Arguably, we had seen some of this before in communities like Usenet and The WELL. But at the dawn of the 21st century, the sheer scale and emergent richness of social software on the World Wide Web launched us past the proverbial tipping point. As one individual commented on David Weinberger's blog:
There's tremendous excitement and activity at this intersection of social networks and information technology. Millions of bloggers swap memes in exchange for karma, whuffie, and other tokens of a reputation economy. Novel forms of discourse emerge as we experiment with Wi-Fi-enabled back-channel communications in classrooms and conferences. New toys and tools bubble to the surface with insurgent alacrity: the social bookmarks of del.icio.us, the popular photo sharing tags of Flickr. It is amidst this woof and warp of social software that folksonomies arrived. On an information architecture mailing list, Gene Smith noted the growing use of user-defined labels and tags to organize and share information, and asked "Is there a name for this kind of informal social classification?" After a brief discussion, Thomas Vander Wal replied:
And so, the neologism that unites folks and taxonomy was born modestly, with a question. But upon entering the blogosphere, this word took on a life of its own, eschewing its humble origins for the glamour of David Sifry's Technorati revolution:
Even worse, this naughty ingrate of a word aligned itself with Clay Shirky in open rebellion against its parents. In a debate with Lou Rosenfeld, Shirky argued:
Ouch! First he slams the Semantic Web. Then he desecrates information architecture. For a social software apostle, Clay comes across as a bit anti-social. Someone should tell him it's against the rules to use boundary objects as weapons. Anyway, let's get back to this business of free tagging, mob indexing, collaborative categorization, ethnoclassification, or whatever you want to call it. The core idea is simple. Users tag objects with keywords, with the option of multiple tags, shown in Figure 6-12. Figure 6-12. Multiple tags per object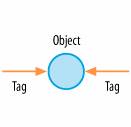 The tags are shared and become pivots for social navigation. Users can move fluidly between objects, tags, authors, and indexers. Things get interesting when many people apply different tags to the same object and when many people apply the same tag to different objects. Let's try an example. The information architect, Jesse James Garrett, wrote an article entitled "Ajax: A New Approach to Web Applications."[*] A couple of months later, 1,646 people had bookmarked this article with del.icio.us, as shown in Figure 6-13. Which, first of all, tells us it's a pretty popular article.
Figure 6-13. Popular links on del.icio.us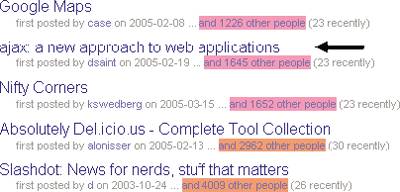 But more importantly, we can see who used which tags to describe the article. And we can follow those links to discover more about these topics and the people behind them. We can find other articles about webdev, programming, xml, ria, javascript, or flash, and even learn what other people plan to "read_later," shown in Figure 6-14. And, we can discover who else is interested in Ajax. In a sense, the object serves as a seed for emergent community. Figure 6-14. Links to Jesse's article on del.icio.us Similarly, we can view a list of other articles or objects that have been tagged with the keyword "ajax." This helps us find other people who are talking about this topic, sometimes from a very different point of view, as shown in Figure 6-15. Figure 6-15. Objects tagged with keyword "ajax" In this way, tags serve as threads that weave a disparate collection of objects together, as shown in Figure 6-16, creating an emergent category that's defined from the bottom up: a folksonomy. And, what's great is that we didn't have to pay (or wait for) librarians, ontologists, or other members of the "well-designed metadata crowd" to impose a top-down hierarchy. Folksonomies flourish in the cornucopia of the commons without noticeable cost. They introduce a wonderful element of serendipity into web navigation, and serve as leading indicators of interest and activity. A hot tag Figure 6-16. Multiple objects per tag suggests a meme on the move, and a picture tells a thousand words. These days, it seems everybody's reading the Flickr tea leaves.[*]
Forget about ontologies and taxonomies. Folksonomies are the future. As David Weinberger puts it, "The old way creates a tree. The new rakes leaves together." And I have to agree with David. The metaphor is perfect. Because we know what happens to the beautiful piles of leaves we shuffle through each autumn. They rot. And they return to the ground, to become food for trees, which come in myriad shapes and sizes, and offer great value, and live for a very long time. Folksonomies are great for surfing what Technorati calls the World Live Web?. They are an amazing new tool for trendspotting and for revealing desire lines. And as personal bookmark tools, they're not bad for keeping found things found. But when it comes to findability, their inability to handle equivalence, hierarchy, and other semantic relationships causes them to fail miserably at any significant scale. If forced to choose between the old and new, I'll take the ancient tree of knowledge over the transient leaves of popularity (shown in Figure 6-17) any day. But that's the beauty of the boundary object we call metadata. We don't have to choose. Ontologies, taxonomies, and folksonomies are not mutually exclusive. In many contexts, such as corporate web sites, the formal structure of ontologies and taxonomies is worth the investment. In others, like the blogosphere, the casual serendipity of folksonomies is certainly better than nothing. And in some contexts, such as intranets and knowledge networks, a hybrid metadata ecology that combines elements of each may be ideal. This potential synergy extends beyond the genius of the AND into the concept of pace layering, perhaps best articulated by Stewart Brand. In his books How Buildings Learn and The Clock of the Long Now, Stewart explores the notion that buildings, and society as a whole, are constructs of several layers, shown in Figures 6-18 and 6-19, each with a unique and suitable rate of change. Figure 6-17. The leaves of Flickr Figure 6-18. Pace layering in buildings (adapted from How Buildings Learn by Stewart Brand. Penguin Books [1995])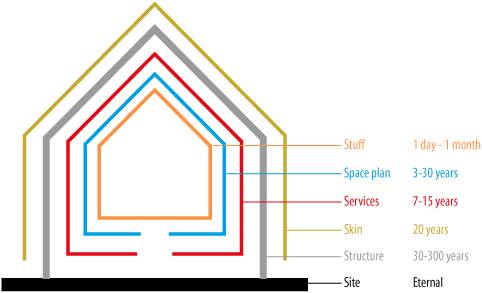 The slow layers provide stability. The fast layers drive innovation. The independence of speed between layers is a natural and healthy result of evolution. Imagine the alternative. How about commerce moving at the pace of government? Remember the Soviet Union? Figure 6-19. Pace layering in society (adapted from The Clock of the Long Now by Stewart Brand, Basic Books [2000])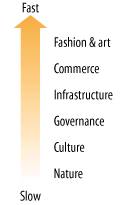 For quite some time, I have believed this concept of pace layering holds great promise within the narrower domain of web design. In this discussion of metadata, the potential for a unifying architecture is self-evident. Semantic Web tools and standards create a powerful, enduring foundation. Taxonomies and ontologies provide a solid semantic network that connects interface to infrastructure. And the fast-moving, fashionable folksonomies sit on top: flexible, adaptable, and responsive to user feedback. And over time, the lessons learned at the top are passed down, embedded into the more enduring layers of social and semantic infrastructure. This is the future of findability and sociosemantic navigation: a rich tapestry of words and code that builds upon the strange connections between people and content and metadata. 6.2.4. NetworksA network is composed of nodes connected by links: islands linked by bridges, markets by trade routes, computers by phone lines, nerve cells by axons, and people by relationships. Figure 6-20 shows a very simple network. Networks play a powerful role in our lives. They influence where we go and who and what we find. This is the invisible thread that connects semantic and social networks , and has us seeking findability insights in the wilds of social network analysis. Figure 6-20. A simple graph or network The study of interaction between people often reveals patterns that are interesting from a findability perspective. For instance, in the example shown in Figure 6-21, we can measure:
Figure 6-21. Kite network diagram (from "Social Network Analysis" by Peter Morville; available at http://semanticstudios.com/publications/semantics/000006.php)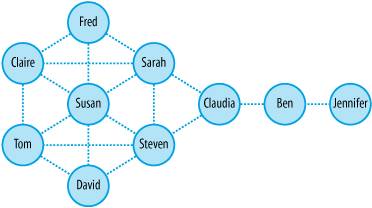 These metrics can be applied at the level of individuals, organizations, and industries. They can also be applied to computer networks to optimize topology and to information systems to improve findability. For the "boundary spanner" in this example could just as easily be a document found in a library or through a Google search. Nodes can be people or content, and can serve as end or path, data or metadata. Articles, books, and blogs are not simply destinations, for they often serve as inverse queries that draw users to authors. We write, not just to communicate, but to enhance our own personal findability. Another interesting pattern in social networks is the "small world" phenomenon that's been popularized by the phrase "six degrees of separation." And, in this sense, the Web is also a small world. A research study conducted in 1998 that estimated a publicly indexable Web of 800 million nodes, suggested that "any document is on average only nineteen clicks away from any other."[*] However, as Albert-Laszlo Barabasi explains:
According to Barabasi's calculations, if it took only a second to check a document, it would take over 300 million years to find all documents that are 19 clicks away. Small worlds don't resolve findability. We can gain more insight by understanding power laws. Remember Zipf Distributions? In self-organizing networks like human society and the Internet, many small events coexist with a few large events. On the Web, a few major hubs enjoy huge quantities of inbound links, while most web sites are barely visible in the eyes of popularity-sensing algorithms like PageRank. Of course, it's not just sites that suffer in the Siberia of the Long Tail. This is where many of the searches reside as well. Linking supply and demand in the Long Tail is a great challenge and opportunity. As Chris Anderson notes, the typical Barnes & Noble carries 100,000 titles. Yet a quarter to a third of Amazon's book sales come from outside its top 100,000 titles.[
But their success provides little consolation to the owners and authors of invisible nodes in the network. Consider, for instance, the Italian entrepreneur who asked me for help. He had paid a design firm to build a web site for his company. Several months later, he discovered that his site was unfindable. Even a query on the exact name of his company failed to return his site in Google. At first glance, the site was attractive enough, but a quick look under the hood revealed the problem. The text had been rendered as images in a quest for typographical control: desirability at the expense of findability. In this simple example lies an important lesson. On the Web, the journey often begins with the destination. The user's keyword entered into a search engine must connect with a keyword in your web site, or the visit is over before it has begun. For this reason, it's worth looking more closely at the node at the end of the road we call the document. |
 ]
] ] "What is RDF?" by Tim Bray. Available at http://www.xml.com/lpt/a/2001/01/24/rdf.html.
] "What is RDF?" by Tim Bray. Available at http://www.xml.com/lpt/a/2001/01/24/rdf.html. ] This metadata schema can be encoded in HTML, XML, and RDF. It fits perfectly with the triple storage model, as shown in Figure 6-11.
] This metadata schema can be encoded in HTML, XML, and RDF. It fits perfectly with the triple storage model, as shown in Figure 6-11.EAN: 2147483647
Pages: 87