What Is a Tree-Based XML Parser?
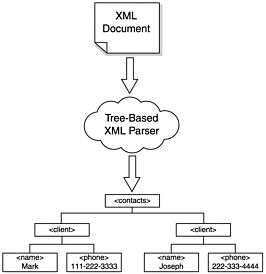
| During the last chapter, we discussed event-based XML parsers. An event-based XML parser defines subroutines that are triggered whenever the XML parser encounters a particular construct.This chapter discusses an alternative to event-based XML parsing called tree-based XML parsing. A tree-based XML parser takes a different approach to the task of parsing an XML document. Contrary to the passive event-based approach where the application defines event handlers and waits for the handler to be triggered, the tree-based approach to XML parsing is more active. In the tree-based approach, the entire XML document is parsed and the entire document is stored in memory in a structure similar to a tree. To access a particular portion of the XML document, the application must actively retrieve it. As you can see, this is the opposite approach to an event-based parser where an event handler would need to be defined and would then wait until the parser encountered the corresponding construct. As an example of how a tree-based parser works, let's assume that your client contacts are stored in an XML document such as this: <?xml version="1.0" encoding="UTF-8"?> <contacts> <client> <name>Mark</name> <phone>111-222-3333</phone> </client> <client> <name>Joseph</name> <phone>222-333-4444</phone> </client> </contacts> The tree-based parser would take the XML document as input and generate a tree structure in memory that contains the data. Figure 4.1 shows a high level view of a tree-based parser. As you can see, the parser takes an XML document as input and generates a tree structure containing the contents of the XML elements. Figure 4.1. Notional tree-based XML parser. Tree-based XML parsers have a few differences from event-based parsers, which can be considered advantages (depending on your situation). First, a program built using a tree-based XML parser module is usually smaller in size than a program built with an event-based parser. This is due to the fact that you don't have to generate event handlers to extract the information from the XML data. Also, you don't need to store information extracted from the XML data for later processing (the tree-based parser stores the data for you). Second, tree-based parsers provide random access to the XML data. Let's say you need to access the last element in an XML document. Using an event-based parser, you'll need to handle events for every element in the document, searching for the element in which you're interested. If you're looking for a particular element with a tree-based parser, you can directly access the element as soon as the XML document has been parsed. |