GENERIC MULTI-AGENT WEB ARCHITECTURE
Several authors have proposed multi-agent approaches in different domains to deal with web information (see Camacho et al., 2002b; Decker et al., 1997; Knoblock et al., 2000), some general conclusions could be summarized from those works to describe a possible generic multi-agent architecture, which could be used to implement adaptable and robust web systems. Figure 1 shows a schematic representation of this architecture. The architecture is built using a three-layer model. The functionality of those layers can be summarized in:
-
User ’ System Interaction . This layer usually provides a set of agents that is able to deal with the users. These agents (UserAgents, IntefaceAgents, etc.) could use different techniques, such as learning (see Howe & Dreilinger, 1997; Lieberman, 1995), to facilitate the communication between the users and the whole system. In the past few years , this interaction has sparked interest in Human-Computer Interaction (Lewerenz, 2000).
-
User Agents ’ Task Agents . This layer is usually built by a set of specialized agents which achieve a specific goal. We call these specialized agents Task Agents, although different architectures refer to them as Middle Agents, Execution Agents, Planning or Learning Agents, etc. Several models of MAS require that the control agents necessary for the system to work correctly be in this layer (usually named as ANS agents, AMR, Control Agents, etc.). Characteristics of this layer, i.e., coordination, organization, cooperation, negotiation, etc., are widely studied (see Nwana, 1996; Rosenschein, 1985; Sycara, 1989).
-
Middle Agents ’ Web Agents . This layer involves agents, such as Information Agents, Web Agents, SoftBots, Crawlers (Selberg & Etzioni, 1997), and Spiders (Chen et al., 2001), which specialize in accessing, retrieving and filtering information from the Web. These types of agents retrieve entire pages or specific parts of those pages (usually the information belongs to <meta> tags). These agents could be characterized because they are able to access different web servers, extract some information, filter that information, and finally store the retrieved document. These agents usually use one or more wrappers (see Kushmerick, 2000; Sahuguet & Azavant, 2001; Serafini & Ghidini, 2000) to wrap the web source and retrieve the available information.
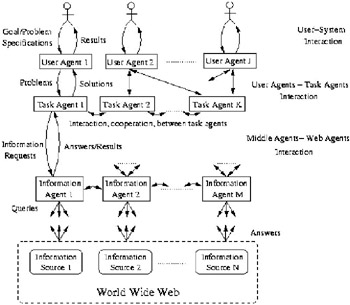
Figure 1: Generic Web Multi-Agent Based Architecture
The multi-agent approaches that deal with web information have several advantages and disadvantages. They are summarized as follows :
Advantages of a Multi-Agent Approach:
-
These systems have better adaptability when unexpected problems in web servers occur. It is easy to add new agents specialized in new web sources.
-
The software maintenance is usually simpler than the traditional monolitic applications because the whole system can be split into several simple elements.
-
These systems are more robust (have a better fault tolerance) because, if some of the agents are down, the whole system could still work.
Disadvantages of a Multi-Agent Approach:
-
It is more complex to design the system than a single-agent approach because it is necessary to design the different relations between the agents; new problems, such as coordination, control, or organization, need to be performed to obtain a complete operative system.
-
These systems could cause new problems, e.g., the coordination or cooperation among the agents that the engineer could need to solve. These new problems arise from the utilization of multi-agent techniques that could be avoided in a monolitic approach.
-
The increasing number of elements (agents) involved in achieving the goal set by the user increases the number of communication messages between the agents. The communication process could be a serious obstacle to a good performance by the whole system.
However, if the main goal is to obtain robust, adaptable, and fault-tolerant web-based systems, we believe that the multi-agent based approach is a suitable one, which provides many important advantages in obtaining the desired systems.
Characteristics to Implement Robust MAS-Web Systems
From the previous generic MAS architecture, three important aspects for characteristics ( related to the layers shown in Figure 1) need to be performed to achieve the desired goal:
-
It is necessary to provide a flexible and user-friendly user agent to adapt the behavior of the system to the needs of the user.
-
The agent and multi-agent model used to implement the final system is a critical aspect. To build the system, it is possible to use several frameworks and toolkits, such as Jade (Bellifemine et al., 1999), JATLite (Petrie, 1996), ZEUS (Collis et al., 1998), etc. These frameworks allow to the engineers to reuse libraries and agent templates to facilitate the design and implementation phases. The selection of the agent and multi-agent architecture will be an important aspect in the implementation of the system.
-
For any system that uses web sources, the problems of accessing, retrieving, filtering, representing and, finally, reusing this information need to be overcome .
This chapter addresses the latter characteristic. The first two characteristics will not be analyzed . The process of knowledge extraction is difficult, but it is an essential characteristic for any system that needs to solve problems using web knowledge.
EAN: N/A
Pages: 171