Managing Enterprise Networks
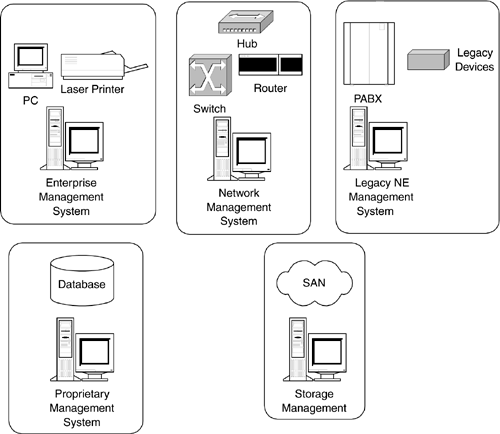
| Why is enterprise network management important? First, it helps keep the overall network running ”end users are kept happy and the business processes are not blocked by downtime. Second, good network management facilities assist in all the lifecycle stages. Third, such facilities should help to reduce the cost of running the network. This last point is particularly important during periods when IT budgets and staff numbers are cut. An important issue concerning enterprise networks is the presence of multiple incompatible management systems. While expensive resources are shared using the underlying network, these resources are generally not centrally managed in a technology-independent fashion. An example of this is the SAN facility shown in Figure 1-1. The individual components of SANs (disk subsystems, network switches, and SAN servers) typically each have a dedicated management system. This substantially adds to the cost of ownership. Gartner Group Research claims that the cost of managing storage is five to seven times the price of purchasing storage [NovellSAN]. Generic enterprise management systems, such as HP OpenView, already exist, but not all of the networked systems (such as in Figure 1-1) have the necessary infrastructure that would allow them to be managed in an integrated fashion. An illustration of this in Figure 1-1 occurs if one of the digital phone cards in the PABX (the Voice Service in Figure 1-1) fails. If the PABX does not emit some type of message to this effect, then the desk phones connected to the card in question will lose service until the problem is fixed. Likewise, if a WAN access switch fails, then the WAN connection may be lost. If there is no integrated NMS in place to detect and signal these types of problems, then service loss will occur until the problems are reported and fixed. It is a central theme of this book that the vendors of as many systems as possible should include SNMP (preferably version 3) management capability as a priority. This would allow for all managed elements to emit traps (or messages) as soon as a problem occurs. The necessary minimal components required for making a system manageable are:
MIBs provide a detailed description of the managed data objects. Typically, the description of each MIB object consists of:
Agents (or entities in SNMPv3) are software components that implement the MIB and map the objects to real data on the NE. It is the agent's job to maintain, retrieve, and modify MIB object instance values. The network manager delegates this important task to the SNMP agent. The agent also emits special messages called notifications to signal the occurrence of important events, such as a device restarting or a network interface going down. Finally, the agent must implement all of this using some preconfigured security scheme ranging from simple passwords to stronger techniques involving authentication and encryption. On the manager side, it is important to be able to manipulate the various agent MIBs. This can be done using scripts or via binary software modules built using various programming languages such as Java/C/C++. In either of these two cases it is often necessary to load the associated agent MIB module files into a management application. An example of this is a MIB browser: an application that allows for MIB objects to be viewed (some browsers allow for MIB object instances to be modified). Most MIB browsers merely require MIB module files to be loaded; that is, they are preconfigured with the necessary SNMP protocol software. Another very important topic is the management of both newly commissioned and legacy NEs. It is rare (particularly during periods of economic recession ) for large networks to have forklift upgrades in which the very latest NEs are deployed in place of legacy devices. Normally, new NEs are added and old ones are replaced . For this reason, one can expect a rich mixture of deployed devices, both old and new. This generally also means a complex set of MIBs deployed across the network. As we'll see, this can result in problems related to the support of backwards compatibility (a little like saving a word- processed document using version 4 and then experiencing problems opening the document with version 3 on your laptop). MIBs provide the managed object definitions (type, structure, syntax, etc.) for the underlying system; for example, a terminal server may implement the following principal managed objects:
To provide baseline SNMP management for a terminal server, the relevant MIB must be consulted for the requisite managed-object definitions. The instance values of these objects can then be looked up using a MIB browser. The SNMP software modules (along with the MIBs) can be integrated into a management system and used to monitor and configure the associated agent. This approach (using SNMP) obviates the need for a proprietary management system. More details on the topic of terminal-server serial-interface MIB objects can be found in Appendix A, "Terminal Server Serial Ports." Later, we'll see that the quality of the MIBs has an important bearing on the manageability of a given NE. Figure 1-2 illustrates a different view of an enterprise network. Figure 1-2. Enterprise management systems. In this diagram, the NEs are grouped alongside their associated management systems. The multiplicity of management systems is one of the reasons why enterprise network management is so difficult. This is what we mean by multiple incompatible management systems: Problems in a device attached to the PABX are not reflected back to the enterprise network manager. Instead, they register by some proprietary means in the legacy NE management system (if one is deployed), and it is up to IT to discover and resolve the problem. Many smaller devices (such as terminal servers) support only a simple text-menu “based EMS or command-line interface (CLI). The absence of SNMP agents (or the deployment of only SNMPv1) on these devices contributes to making them difficult to manage in an integrated, vendor-independent, and centralized fashion. In order to manage enterprise networks as seen in Figure 1-2, it is necessary to learn all of the deployed technologies as well as their proprietary management systems. This is an increasingly tall order. In many organizations, the management facilities consist of simple scripts to configure and monitor devices. While many enterprise network managers may implement ingenious script-based facilities, all such solutions suffer from being proprietary. An added problem is seen when the author leaves the organization ”the requisite knowledge often leaves at the same time. Adoption of standards-based network management technology helps in avoiding this. Standards-based consolidation of management systems can help enterprises to achieve the following:
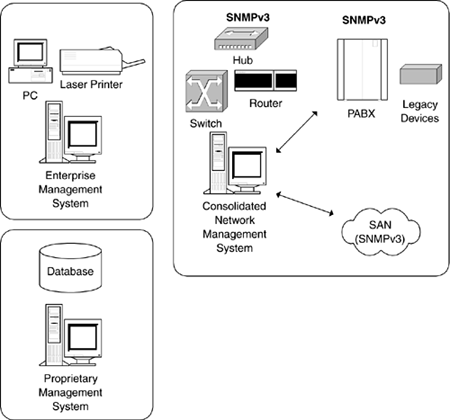
A single (or a reduction in proprietary) management technology in the network contributes to making that network easier (and cheaper) to operate and maintain. It is for this reason that we say as many as possible of the components of enterprise networks should implement SNMPv3 agents (or entities, as they are called). Figure 1-3 illustrates a modified enterprise network with SNMPv3 entities deployed in the SAN, legacy NEs, and in the switch/router/hub NEs. Figure 1-3. Example of consolidated enterprise NMS. If all of the NEs deploy SNMPv3 entities, then it is possible that one or more of the proprietary management systems (in Figure 1-2) can be removed and consolidated into one NMS. Of course, it's not so easy to just add SNMPv3 capability to all of these NEs (particularly the legacy NEs). The point is that it has a substantial benefit. The other enterprise systems in Figures 1-2 and 1-3 (the networked PCs, print servers, and database management system) generally tend not to deploy SNMP for their management and operation. This is largely for historical reasons. Since this book is about network management rather than system management, we do not consider this area any further. However, before moving on, we should say that there are no major reasons why SNMP technology should not be used for managing such systems. ManageabilityFor a number of reasons, not all NEs lend themselves to flexible, integrated, centralized management. This tends to add to the cost of ownership and arises for a range of reasons:
Proprietary management infrastructure may consist of just a simple CLI with no SNMP deployment. It is difficult and costly to incorporate these NEs into an NMS because customized software must be written to send and receive messages to them. NEs that support just SNMPv1 and set operations are generally felt to be a security risk (because the relevant password is transmitted across the network as clear text). As a result, no set operations may be allowed. Configuring such NEs is usually achieved via CLI scripts. While this is a fairly standard approach, it negates some of the benefits of using an NMS, such as security, audit trails, and GUI-based help facilities. Much the same applies for those NEs with SNMPv1 and no set operation support. Configuration must be achieved using non-SNMP methods . Poor implementation of SNMPv3 might consist of low resource allocation (process priority, message buffers, caching, etc.) with the result that the management system regularly gets choked off. This may be seen during periods of high device or network loading (often the time when network management is most needed). Badly written MIBs are the bane of the NMS developer's life. We'll see examples of good MIB design later on, but for now we illustrate this with a simple example of adding a new row to a table indexed by an integer value. To add a new row to this table, a new index value is required. Often, MIB tables do not implement a simple integer object to store the value of the next free index. This may require a full (expensive) walk of the table in order to calculate the next free index. This is inconvenient when the table is small (less than 100 entries), but when the table is big (many thousands of entries), a MIB walk becomes an expensive option because of the number of agent operations and the associated network traffic. The inclusion of a specific index object to facilitate new row addition can greatly assist the management system. We will see all of these considerations in action later on. In summary, an NE is considered to have good manageability if it supports a well-implemented SNMPv3 agent and a high-quality MIB. Operating and Managing Large NetworksRunning networks such as the ones described above is difficult. The growing range of services offered to end users means that traffic levels are always increasing. Deploying more bandwidth can offset rising traffic levels but, unfortunately , the nature of this traffic is also changing as the associated applications become more resource-intensive and mission-critical. This is seen in Figure 1-1 with LAN-based voice, video, and data applications, which (except for data applications) impose stringent timing requirements on the network. Some way of guaranteeing network transport (and NE) availability is needed, and best-effort IP service in the long run is probably insufficient for large, distributed enterprises. This is one of the biggest challenges facing all network operators ”how to provision bandwidth- intensive , time-constrained applications on layer 3 networks. Many enterprises and SPs have used overengineering of the network core bandwidth to cater to increased traffic levels. This is ultimately not scalable, and later on we examine the solution MPLS offers to hard-pressed network operators. It is increasingly important for the network to provide defined quality of service levels for traffic. Some important aspects of enterprise network management are:
We will cover many of these topics. In the next sections we look at those OSI network layers of greatest relevance for the forthcoming discussions. Layers 2, 3, and 2.5Reference is made throughout this book to layer 2 and 3 devices [Puzmanova2001]. Some confusion seems to surround the use of these terms both in the industry and in the literature. Issues affecting layers 2 and 3 on enterprise networks are a recurring theme throughout this book. Our use of the terms layer 2 and layer 3 follows the guidelines of the OSI model. A layer 2 device is one that operates no higher than the data-link layer ”for example, ATM, Frame Relay (FR), and Ethernet switches. The basic unit of transmission at layer 2 is the frame (or cell for ATM). A layer 3 device operates at the network layer and deals only in packets. An example of a layer 3 device is an IP router. Layer 2.5 is a special mode of operation where some of the advantages of layer 2 are leveraged at layer 3. The different layers are described in the following sections. Layer 2 and VLANsFigure 1-4 illustrates the core of a fictitious enterprise network operated exclusively using ATM/MPLS multiservice switches. This is a layer 2 network that is logically divided into VLANs (well described in [Tanenbaum2003]). VLANs, as we noted earlier, are broadcast domains that allow communication between member devices as if they were all on the same physical LAN segment. The switches in Figure 1-4 serve to partition the VLANs by forwarding only appropriately addressed frames . In an effort to improve convergence time, some switches support, on a per-VLAN basis, the spanning tree algorithm (the means by which loops are avoided [Tanenbaum2003]). Spanning Tree Protocol is usually implemented across all LANs, not just VLANs. If it is implemented on a per-VLAN basis, it improves convergence. The constituents of any of the VLANs in Figure 1-4 can include a number of machines; for example, VLAN 2 consists of 55 PCs, three servers, two printers, and four workstations. Layer 2 broadcasts originating inside any of the VLANs do not cross the boundary of that VLAN. One possible configuration is to allocate a specific VLAN for each layer 3 protocol ”for example, IPX in VLAN 1 and IP in the other VLANs. Since VLAN 1 has nodes that understand only IPX, there is no reason for pushing IP traffic into it. Likewise, the nodes in the other VLANs might not understand IPX, so there is no reason for pushing IPX traffic into them. Only layer 3 traffic that needs to exit a VLAN crosses the boundary (via routing) of its container VLAN. The merit of a VLAN arrangement is that traffic between the constituent devices does not pass needlessly into the other VLANs. Also, if one of the VLANs fails (or if a node inside that VLAN becomes faulty), then the other VLANs can continue to operate. This allows for a more scalable and flexible network design than using IP routers in conjunction with Ethernet segments. Typically, the hosts in each of the VLANs support layer 3 routing capabilities (e.g., IP, IPX). This is required for communication outside the VLAN boundary. Each such host supports layer 3 routing tables with at least one entry pointing to an external router. The latter may be implemented on the local switch (A or B in Figure 1-4) and serves to direct outgoing and incoming IP traffic across the VLAN boundary. To illustrate this, Table 1-1 depicts an excerpt from a routing table from one of the 55 PCs in VLAN 2. The data in Table 1-1 is obtained by using the netstat “r command from within a DOS console. Table 1-1. IP Routing Table for a Host PC in VLAN 2
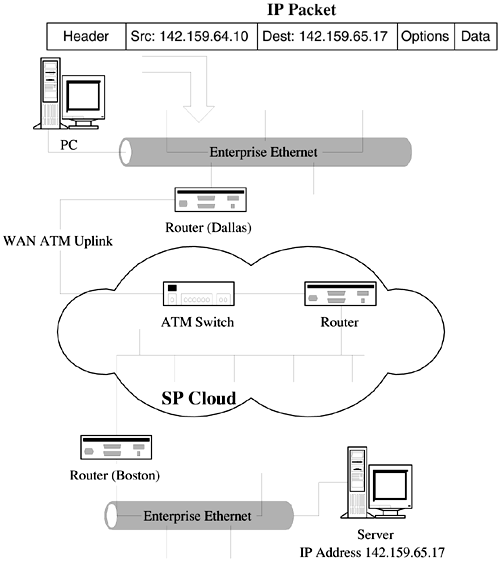
Table 1-1 illustrates two routing table entries: one for the loopback address and the other for the default gateway. Any packets addressed to the loopback address are sent back to the sender. So, if you ping 127.0.0.1, your host machine (i.e., the sender) will reply. The second entry in Table 1-1 is for the default gateway. This is the IP address of last resort (Internet core routers do not have default gateway entries), that is, the address to which packets are sent for which no other destination can be found. In Figure 1-4 this address (142.159.65.17) would be located on Switch A. It is by this means that hosts in VLAN 2 can exchange messages with entities outside their VLAN boundary. Appendix B includes examples of using some of the Windows NT/2000 networking utilities. Another important point about VLANs is that the backbone network (between switches A and B) may be implemented using ATM. If this is the case, then the backbone may implement ATM LAN Emulation (LANE). This serves to make the ATM network behave like a LAN. The backbone can also run MPLS. Greater flexibility again is afforded by the use of IEEE 802.1Q VLANs. In this technology, the 802.1 Ethernet frame headers have a special 12-bit tag for storing a VLAN ID number. This allows for traffic to flow between different VLANs. It is also possible to use another tag in the 802.1 header for storing priority values; this is the IEEE 802.1p tag ”a 3-bit field. This allows different types of traffic to be marked (with a specific priority number) for special treatment. Traffic that must pass across the ATM/MPLS backbone is destined for another VLAN (e.g., VLAN X in Figure 1-4). This traffic can be transported using either ATM or MPLS. ATM cells are presented at interface p of ATM Switch A. An ATM Switched (Soft or Smart) Permanent Virtual Channel Connection (SPVCC) has been created between switches A and B. This virtual circuit traverses the ATM/MPLS cloud between switches A and B. An SPVCC is a signaled virtual circuit, which forms a connection between interfaces on a number of switches. An SPVCC is conceptually similar to a time-division multiplexing (TDM) phone call: An end-to-end path is found, bandwidth is reserved, and the circuit can then be used. The SPVCC in Figure 1-4 starts at interface p on Switch A, travels across the intermediate link, and terminates at interface q on Switch B. This bidirectional virtual circuit transports traffic across the backbone between switches A and B. An important point about circuits that traverse the backbone is that some switches allow the mapping of IEEE 802.1p values to specific circuits. This allows for quite fine-grained quality of service across the backbone. The SPVCC is a layer 2 connection because the constituent switches have only layer 2 knowledge of the traffic presented on their ingress interfaces. The layer 2 addressing scheme uses a label made up of two components: the Virtual Path Identifier (VPI) and Virtual Channel Identifier (VCI) pair. Each switch does a fast lookup of the label and pushes the traffic to the associated egress interface. The switches have no idea about the underlying structure or content of the traffic, which can be anything from telephony to IP packets. As indicated in Figure 1-4, the virtual circuit can also be realized using MPLS label switched paths (LSPs). Such LSPs carry layer 2 traffic encapsulated using MPLS labels (more on this later). The layer 2 technology that we describe has the following general characteristics:
The SPVCC/LSPs in Figure 1-4 represent our first example of virtual circuits. The different categories of traffic (TDM, IP, etc.) presented at interface p can be transported across appropriate virtual circuits. These circuits can be provisioned with different quality of service (more on this later) characteristics to ensure that the traffic receives specific forwarding treatment. So, far, we've only hinted at some of the elements of MPLS but it will be seen that many of the advantages of layer 2 technologies can be obtained at layer via MPLS. Layer 3Figure 1-5 illustrates an IP network with an intermediate WAN that crosses an SP network. A client PC in Dallas has some IP data to send to a server in Boston, and the traffic is carried to the destination via the SP network. Each router along the path performs a lookup of the destination IP address (142.159.65.17) and forwards the packet to an appropriate output interface. Figure 1-5. An IP network. One of the other major differences between layer 2 and IP is that the latter cannot reserve either resources (such as bandwidth) or paths ahead of time. Even with static routes installed, a full IP address lookup is required at each router, and the direction that the packet takes can change at each hop (for example, if a static route goes down). So, IP packets from a given source can travel over different routes at different times, and ordering is not guaranteed . The TCP protocol gets over some of these problems, but TCP can't reserve bandwidth and full address lookups are still required at each hop. Layer 2.5 (or Sub-IP)A further possibility exists for transporting layer 3 traffic: MPLS. MPLS operates at what is often called layer 2.5, that is, not quite layer 3 but also higher than layer 2. MPLS operates by adding a fixed-length (4-byte shim header) label to the payload, which includes an unstructured 20-bit label. This label is then used in forwarding the encapsulated packet. The label is structured for compatibility with ATM VPI/VCI addressing and allows for ATM [4] switches to be upgraded to MPLS. MPLS can also be deployed on routers and brings numerous benefits to IP networks:
One disadvantage of MPLS is that all nodes in the path must run the MPLS protocols ”an additional burden on network operators. Traffic engineering is often called the MPLS killer app because it permits connection-oriented operation of IP networks. Incoming IP traffic can be redirected to a higher or lower bandwidth path. Apart from traffic engineering, an emerging function of MPLS is the generic transport of legacy layer 2 services, such as ATM, FR, TDM, and Ethernet. This is an effort to provide a standards-based migration path for network operators who do not want to fully deploy MPLS throughout their networks. In other words, the legacy services continue to be deployed, but they are transported across a fully or partially deployed MPLS core. Ports and InterfacesThe terms port and interface are often used interchangeably. In this book they have a specific meaning. Ports are taken to be underlying hardware entities, such as ATM or Ethernet ports. Interfaces exist at a higher level of abstraction and are configured on top of ports. This is similar to the way an Ethernet port on a PC is configured to run IP. Interfaces are sometimes referred to as logical ports. Examples of interfaces are:
In many cases, the user must manually configure interfaces. The key difference is that ports work out of the box, whereas interfaces generally do not. A lot of action takes place at interfaces ”for example, quality of service (QoS) imposition in a DiffServ domain. QoS is a scheme by which traffic is marked prior to or at the entry point to a network. Each node traversed by the traffic then examines (and possibly updates) the marked values. The function of the traffic markings is a signal to the network nodes to try to provide the indicated level of service. Required service levels differ depending on the traffic type; for example, VoIP traffic has specific timing requirements that are more stringent than those for email. The point is that network node interfaces are an integral part of the provision of the QoS scheme. We will see more on this later. Many SPs provide customer premises equipment (CPE) as part of an enterprise service. CPE is a term that describes some type of switch or router owned by the service provider but located on the customer premises. Examples of CPE devices are seen in Figure 1-5, such as "Router (Boston)". The CPE provides access to the SP network from within the enterprise network. Typically, the CPE provides access to services such as Metro Ethernet, VPN, ATM, FR, and TDM. All of these tend to take the form of one or more ports on a CPE device. Depending on the service purchased, CPE management may be executed either by the service provider, the enterprise, or some combination of the two. In Chapter 6, "Network Management Software Components," Figure 6-8 illustrates some issues concerning the automatic configuration of IP interfaces. In Chapter 8, "Case Study: MPLS Network Management," Figure 8-3 illustrates a MIB table that provides details of MPLS interfaces on a given NE. One use for the MPLS interface table is selecting MPLS-specific interfaces in an NMS. Selected interfaces can then be used for inclusion in LSPs. |
EAN: 2147483647
Pages: 150