Why Use Network Management?
| Devices deployed in networks are increasingly intelligent , so it is interesting to ponder the need for network management. If devices are so smart, then why bother with network management? Can't NEs just self-heal in the event of problems like interfaces going down? Many enterprise networks do not employ NMS ”this may be just a matter of policy or even history. There are a number of reasons why network management is a crucial enterprise and SP component:
A good quality NMS broadens the operator's view of the network. This can help to leverage the increasing intelligence of modern NEs. What Is Network Management?The preceding sections have described some typical large networks now in common use. They have hinted at issues concerning network management, which is now described more fully. Network management provides the means to keep networks up and running in as orderly a fashion as possible. It includes planning, modeling, and general operation. It also provides command and control facilities. Broadly speaking, the functional areas required for effective network management are:
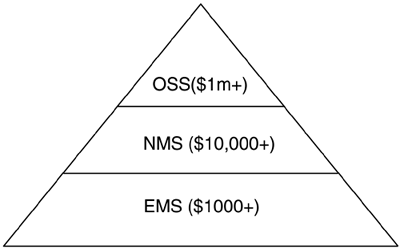
The above points describe what are known as the OSI functional areas of network management, FCAPS , described at length in [Stallings1999]. A good management system should fulfill all the FCAPS areas (many products provide only fault and performance management, leaving the other areas to proprietary means or ancillary products). An important point is that the FCAPS areas are inter-dependent. Fault management has to know about the network configuration in order to provide meaningful reports . The same is true of performance monitoring, particularly for complying with SLAs. Likewise, billing (or accounting) has to have some knowledge of the underlying configuration. Providing all this management capability is a big challenge, especially for large distributed networks containing lots of legacy equipment. Organizations implement their FCAPS functions in interesting ways: Some do all the management inhouse while others outsource it to third parties. Large enterprises can operate a number of different types of networks, such as broadband, IP, and telephony. Each network has to be managed, and in many cases each has its own management system, making overall management complex, error-prone , and potentially very time-consuming . In cases where network management is felt to be too difficult or no longer a core activity, an organization can turn to outsourcing. Outsourcing to a third party can help to alleviate some of the duplication of multiple management systems by connecting the network to a Network Operations Center (NOC). The owner of the NOC then provides billable services in any or all of the FCAPS areas. One merit of using a NOC is that network management costs can become more predictable. However, there are no hard and fast rules about this: An enterprise can also have its own NOC. The use of CPE is another example of outsourcing. Who Produces Network Management Software?Equipment vendors such as Cisco, Nortel, Hewlett-Packard, and Alcatel generally provide SNMP agents on their devices. Separately purchased, integrated management systems are also available from these and many other organizations. These management systems typically run on UNIX or Windows NT/2000 platforms and feature GUIs, object palettes for topology definition, and fairly extensive FCAPS facilities. The Management System PyramidThe owners of large networks tend to functionally separate their software tools, and FCAPS provides a conceptual framework for this. Management systems for large service providers tend to follow a distinct layered structure, illustrated in Figure 1-6 as a pyramid. Figure 1-6. The management system value pyramid. There is good reason ”both technical and financial ”for this functional separation. At the top of the pyramid is the Operational Support System (OSS), which is used for SP business support (feeding into other corporate systems) and overall network support. In passing, we should note that there is some interest in enterprise operational support systems for converged enterprise networks (e.g., AceComm is one vendor in this area). The OSS layer is expensive to develop and deploy. Below the OSS is the NMS, which tends to be used for network- facing operations such as creating, monitoring, and deleting virtual connections ”ATM PVCs and MPLS LSPs, for example. The NMS is generally focused on multiple devices at any given time; in other words, it has a networkwide usage. This is reflected in the value of NMS, which can be priced per network node. Very often, NMS are sold in conjunction with NEs in order to help in quickly bringing up and subsequently maintaining the network. Below the NMS is the EMS, which ”at the bottom of the NMS food chain ”is generally focused on a single device at any given time. Sometimes the EMS is a separate application hosted on an external platform in just the same way as the NMS. This can be the case where devices are:
Vendors of such devices can add an external EMS to extend the device utility. In other cases, the devices themselves host the EMS, allowing device-centered management facilities such as:
The guiding principle is always the same for management systems deployment: It should make the object of attention (NE, network, virtual connections, etc.) easier to use. As we mentioned, the NMS has a networkwide perspective and provides facilities to:
It is important to note that the gap between the EMS and NMS is not always clear cut. Sometimes, an NMS is called upon to process raw device alarms or even to distribute new firmware across a range of devices. The dividing line between EMS and NMS is that most NMS operations tend to simultaneously involve more than one NE. EMS operations tend to center on a single NE. In some cases, an EMS can be developed that runs on a system (such as a PC or UNIX system) external to the NE. The EMS then handles the NE interactions. EMS development for devices without SNMP agents can be quite cumbersome, often involving some type of automated interaction with an NE menu system or CLI. In this, the NE presents its menu options and the EMS emulates a human user and selects the required option, moving to the next menu level. Even with an EMS that interacts with an NE CLI, it is still possible for an NMS to then interact with the EMS. So, even though the EMS is not onboard the NE, this does not concern the NMS. However, the whole scheme tends to be proprietary in nature. In effect, the approach taken is message-based: The EMS directly exchanges messages with the NEs. This approach is not without difficulties: Different versions of firmware may support slight variations in CLI message format or content, making it difficult to formulate a generic approach to such EMS-NE exchanges. Having SNMP on the devices makes EMS development much easier because then the operations are based on standard SNMP message exchanges. As we mentioned earlier, many network operators use a script-based approach to setting up and monitoring devices. This consists of writing large and complex vendor-specific scripts that are then sent to the NEs for batch execution. Clearly, this requires scripts that adhere to a given manufacturer's CLI. This is fine if all network devices support the same CLI (i.e., same vendor and CLI version), but this cannot be guaranteed . SNMP, as part of an NMS, provides a better (standard) mechanism for such operations. In Chapter 6 we will see an example of using an NMS to configure IP interfaces. An NMS offers facilities such as security, script management, and audit trails. Up from the NMS is the OSS layer [Tele2001]. As mentioned earlier, these are very large bodies of software typically deployed in big SP (and some enterprise) networks. OSS provide a variety of business- and network-support functions such as:
Many OSS can use the services of the underlying NMS to do some or all of the following:
In this way, an OSS uses the NMS services in the manner of an API. [7] The TeleManagement Forum (TMF) [TeleMgmtForum] has made great progress in modeling SP operations processes and defining vendor-independent interfaces between OSS and NMS. An example of such a model is the Telecommunications Operations Map (TOM). The TMF has defined Interface Definition Language (IDL) specifications for this purpose. The OSS and NMS both use the IDL for communication.
One consequence of the connection between OSS and NMS is that it is often hard to decide where and how specific management software should be written. For example, an operator might require the ability to create an ATM SPVCC (or an MPLS LSP) connection between two nodes on its network. Should the NMS vendor provide this capability through its NMS GUI or as an IDL API function? Probably both, but it's possible that the GUI version might never be used in an SP environment, so should the vendor provide two solutions when only one is needed? These are heady design questions that have a profound effect on the way in which NMS are both built and used. Other Management TechnologiesSNMP is not the only management technology. Other proprietary systems approaches include:
Microsoft SMS allows system administrators very flexible control of networks of Windows machines. Software applications deployed on host machines can be determined by remotely viewing the local Windows registry (a type of configuration database) on each machine. This can be very useful for verifying on large sites that software licenses have not been exceeded ”too many users installing a given package. SMS also allows software to be distributed to destination machines. This is very useful for updating applications like virus detectors ( indispensable nowadays). Remote operations like this greatly facilitate IT support call centers. A shortcoming of SMS is that it works only on Windows machines. SNMP differs from SMS in one crucial way: SNMP is technology-independent. The only local facilities needed for SNMP management are distributed agents with encapsulated MIBs. Management applications then interact with the agents to monitor and control operation. Telnet refers to a menu-based EMS/CLI style of management. This approach requires the management user to connect to the IP address of a given device using telnet. The device then provides a text menu-based application with which the user interacts. This is useful and is a widely adopted approach for device management. It is generally possible to use telnet to configure devices such as laser printers, routers, switches, and terminal servers. The problem with it is that menu-based management systems are proprietary by their nature and don't easily lend themselves to centralized, standards-based management (as does SNMP). Serial link-based menu systems are very similar to NEs that support telnet. Just the access technology is different. Normally, a serial link-based system includes simple text menus (accessed via a serial interface) that are used for initial configuration. Typical devices for these facilities include small terminal servers. Often, these devices do not have an IP address, and the user configures one via the menu system. Connecting the device to an appropriately configured PC serial port facilitates this. Again, by its nature this is proprietary. DMI was developed by the Desktop Management Task Force and is completely independent of SNMP. Its purpose is the management of desktop environments, and it includes components similar to those of SNMP, such as DMI clients (similar to SNMP managers), DMI service providers (similar to SNMP agents), the DMI management information format (similar to the MIB), and DMI events (similar to SNMP notifications). Network Convergence and Aggregate ObjectsThe provision of services such as Metro Ethernet and layer 3 VPNs is prsenting an interesting network management challenge. Not only are new services being deployed, SP (and to some extent, enterprise) network cores are migrating to layer 3. Managing these converged networks in a scalable, end-to-end fashion is a necessity, especially when competitive SLAs are sold to end users. The service sold to the user may consist of Ethernet (with different priorities supported for specific traffic types), cross-connected into an MPLS core. Modeling this for network management support requires the use of what we call aggregate objects. Aggregate objects are comprised of a number of related managed objects. Examples are VLANs, VPNs, and cross-connect technologies (e.g., Ethernet over MPLS). As the range of technologies and services deployed on networks continues to grow, aggregate objects are becoming increasingly important. We'll see this in Chapter 8 when we discuss LSP creation. Figure 1-4 introduced us to VLANs. From a network management perspective, VLANs are aggregate objects made up of:
Generally, there are two ways for an NMS to build up a picture of a VLAN:
Manual creation requires a combination of human input and network-side provisioning. The user selects the switches required for the VLAN and adds the VLAN members . Provisioning software in the NMS then updates the appropriate MIBs. This is the textbook way of operating networks, but in reality networks may tend to change quite often. NMS DiscoveryIn many cases, changes are made to individual switches via the EMS (usually via the onboard CLI) and unless the user manually updates the NMS, then the EMS-NMS pictures may differ . This is where an NMS feature called network discovery is important. Network discovery is the process by which an NMS uses SNMP (and also ICMP) to read, process, and store the contents of designated MIB tables. In this way, the NMS picks up any changes made via the EMS. This process of ongoing discovery and update is an important aspect of managing large networks. Network discovery also picks up the details of both simple objects and complex aggregate objects. Not all NMS products provide automatic network discovery, because it introduces traffic into the managed network. Also, the workflows of the operator may (manually) provide the same service with no need for an automated solution. We will tend to assume that an automated network discovery function exists. So (using either manual or automatic network discovery), we now have our picture of the network and its higher level constructs (including aggregate objects such as VLANs and VPNs). Having a clear picture of the network objects leaves the operator free to effectively manage the network. What kinds of things can the operator expect to happen to the network? Links and interfaces can go down; for example, if Link 1 in Figure 1-4 goes down, then VLAN 3 will become isolated from the enterprise network. The NMS (not shown in Figure 1-4) should receive a notification from the network that the link has gone down. The NMS then has to cross-reference the notification with the associated aggregate object (in this case VLAN 3) and infer that VLAN 3 is no longer connected to the network. The NMS should indicate the problem (usually in a visual fashion, such as via a GUI color change) to the operator and possibly even suggest a fix. Similarly, if an NE in one VLAN becomes faulty ”for example, if a NIC starts to continually broadcast frames ”then the NMS should figure this out (by looking at interface congestion indicators) and reflect it back to the user. The user can then resolve the problem. The Goal of an NMSThis mechanism of important events occurring in the network and the NMS (and operator) racing to figure out what happened is crucial to understanding NMS technology. The difference between the NMS picture of the network and the real situation in the network must be kept as small as possible. The degree of success attributed to an NMS is directly related to this key difference. This is an important NMS concept that we will refer to frequently. NotificationsWe use the term notification to mean any one of three different things:
An event is an indication from the network of some item of interest to the NMS, for example, a user logging into an NE CLI. A fault is an indication of a service-affecting network problem, such as a link failure. The NMS must respond as quickly as possible to a fault, even suggesting some remedial action(s) to the operator. An alarm is an indication that a potentially service- affecting problem is about to occur, perhaps an interface congestion-counter threshold that has been exceeded. Clearly, in most cases, faults should be processed by the NMS ahead of events and alarms. |
EAN: 2147483647
Pages: 150