CSV to XML: Detail Design
| We're finally ready to start talking about code. In this section I'll go over the design for converting a CSV file to one or more XML documents. We'll also look at the grammar in terms of developing the parsing algorithm. Main ProgramAs discussed in Chapter 6, in order to develop reusable modules that can be linked together into programs and not just cobbled together in scripts, we put the main processing logic in a routine called from a shell main program. Logic for the Shell Main Routine for CSV to XMLArguments: Input CSV File Name Output Directory Name File Description Document Name Options: Validate output Help Validate and process command line arguments IF help option specified Display help message Exit ENDIF Create new CSVSourceConverter object, passing: Validation option Output Directory Name File Description Document Name Call CSVSourceConverter processFile method, passing the Input File Name Display completion message On first glance this type of structure may seem like a bit of overkill. It would be if we were going to process only a single input file. However, it facilitates future enhancements such as accepting a directory as input and converting all the files in the directory. CSVSourceConverter Class (Extends SourceConverter)OverviewThe CSVSourceConverter, then, is the main driver for the actual conversion. Here are its attributes and methods. It inherits all the attributes and methods of its base classes, the SourceConverter and Converter classes (see Chapter 6). Attributes:
Methods:
MethodsConstructorThe constructor method for our CSVSourceConverter object sets up that object, but most importantly it also sets up the CSVRecordReader object. Here's the logic for it. Logic for the CSVSourceConverter Constructor MethodArguments: Boolean Validation Option String Output Directory Name String File Description Document Name Call base class constructor Initialize Partner Array Call loadFileDescriptionDocument using passed File Description Document Name Schema Location URL <- Call File Description Document's getElementsByTagName on "SchemaLocationURL", then getAttribute on "value" IF Schema Location URL is null and Validation is true Throw Exception ENDIF Document Break Column <- Get Document Break Column value from File Description Document Partner Break Column <- Get Partner Break Column value from File Description Document Initialize Saved Partner ID and Saved Document ID Create CSVRecordReader object, passing: File Description Document processFileAfter the initialization performed in the constructor method, the main processing is performed by the CSVSourceConverter's processFile method. This method converts one input CSV file into one or more output XML documents based on the input parameters. Logic for the CSVSourceConverter processFile MethodArguments: String Name of input file Returns: Status or throws exception Output Directory Path <- Base Directory + directory separator Initialize Output Document to null Initialize Sequence Number Row Grammar <- Get RowDescription from Grammar Element via getElementsByTagName, and item[0] from NodeList Open input file Call CSVRecordReader's setInputStream method Record Length _<- Call CSVRecordReader's readRecordVariableLength method DO while Record Length => 0 Call CSVRecordReader's parseRecord method to parse columns into DataCell Array, passing Row Grammar Element Call CSVRecordReader's toXMLType method to convert column contents in DataCell Array to their schema language datatype representation Partner Break <- Call testPartnerBreak IF Partner Break = true Output Directory Path <- Base Directory + Partner ID + directory separator Lookup Partner in Partner Array IF Partner is not in Array Create output directory from Output Directory Path Partner Array <- Add Partner ID ENDIF ENDIF Document Break <- Call testDocumentBreak IF Document Break = true or Output Document is null IF Output Document exists Call saveDocument ENDIF Create new Output Document Create Root Element, using Root Element Name from Grammar, and append to Output Document IF Schema Location URL is not NULL Create noNamespaceSchemaLocation Attribute and append to Root Element ENDIF Increment Sequence Number, and pad with leading zeroes to three digits IF Document Break Column != 0 Output File Path <- Output Directory Path + Root Element Name + Sequence Number + ".xml" ELSE Output File Path <- Output Directory Path + Root Element Name + ".xml" ENDIF Call CSVRecordReader's setOutputDocument method for new Output Document ENDIF Call CSVRecordReader's writeRecord method to write row and column Elements from CSVRecordReader's DataCall Array, passing Root Element of Output Document and Row Grammar Element Record Length <- Call CSVRecordReader's readRecord method ENDDO IF Output Document is not null Call base class saveDocument method ENDIF Close input file Display completion message with number of documents processed You'll note that we check for a new partner or document after converting to XML formats via the toXML method. We could check before converting to XML, but performing the conversion first ensures that we are working with data that is not only in string format but also normalized by removing leading and trailing whitespace. The testDocumentBreak and testPartnerBreak methods do the checks for us. Note that if no break is specified for new documents, we unconditionally return false for break on new partner. testDocumentBreakThis method tests the value of the document break column to determine whether the current row starts a new document. Logic for the CSVSourceConverter testDocumentBreak MethodArguments: None Returns: Boolean - true if new partner and false if not IF Document Break Column is zero return false ENDIF DocumentID <- Call CSVRecordReader's getFieldValue method passing the Document Break Column number IF DocumentID = Saved Document ID return false ENDIF Saved Document ID <- Document ID Return true testPartnerBreakThis method tests the value of the partner break column to determine whether the trading partner in the current row is different from that of the preceding document. Logic for the CSVSourceConverter testPartnerBreak MethodArguments: None Returns: Boolean - true if new partner and false if not IF Partner Break Column is zero or if Document Beak Column is zero return false ENDIF Partner ID <- Call CSVRecordReader's getFieldValue method passing the Partner Break Column number IF Partner ID = Saved Partner ID return false ENDIF Saved Partner ID <- Partner ID Return true CSVRecordReader Class (Extends RecordReader)OverviewWe can see that most of the detailed work is performed by the CSVRecordReader class. It inherits several attributes and methods from its RecordReader and RecordHandler base classes (see Chapter 6). Here is a summary of its extensions to those classes. We'll review each of the methods. Attributes:
Methods:
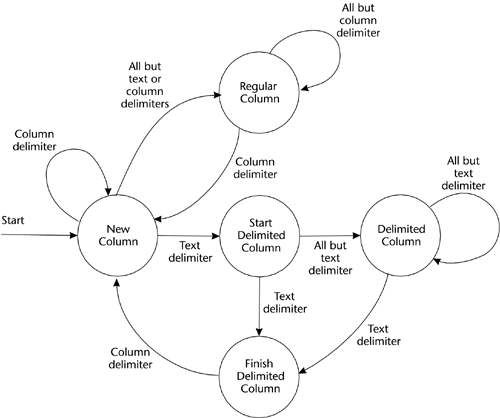
Note : In the Java and C++ implementations we also enumerate class-wide constants for the parsing states used by the parseRecord method. MethodsConstructorHere is the logic for the CSVRecordReader constructor method. Logic for the CSVRecordReader Constructor MethodArguments: DOM Document File Description Document Call RecordReader base class constructor, passing File Description Document Record Terminator <- Get "RecordTerminator" Element's value Attribute from File Description Document Call setTerminator to set the Record Terminator1 and Record Terminator2 Column Delimiter <- Get "ColumnDelimiter" Element's value Attribute from File Description Document Text Delimiter <- Get "TextDelimiter" Element's value Attribute from File Description Document parseRecordThe CSVRecordReader's parseRecord method is where we finally take a more rigorous approach to the grammar of a CSV row. We can borrow several techniques and approaches from compiler construction to develop a good parsing algorithm. Most of those approaches are overkill (and indeed, some programmers may think even this discussion is overkill!), but taking advantage of some of the simpler techniques can go a long way toward keeping us out of trouble. We'll also be using them in the parseRecord method we use for EDI formats, which involves a more complex grammar. The starting point, of course, is the grammar of a CSV row. We reviewed it in BNF earlier in the section. We now need to consider more carefully the characteristics of the grammar of a row. I show it again below so that you don't have to flip back several pages. CSV Row Grammarrow ::= column (column_delimiter column?)* (column_delimiter column?)+ column ::= column_characters_A+ text_delimiter column_characters_B+ text_delimiter column_characters_A ::= All allowed characters except column_delimiter column_characters_B ::= All allowed characters except text_delimiter If we examine the grammar closely, we can see that we can completely determine the meaning of a character, that is, its place in the grammar, simply by considering the characters that precede it. We don't need to do lookahead parsing , that is, examining one or more characters that follow the current character. Our CSV row conforms to the definition of a class of grammars called "regular expressions." This fact makes life a lot easier for us than it might be with more complex grammars. One thing it means is that we can process the grammar with a fairly simple tool known as a finite state automaton . This is an abstract machine that consists of a number of states and specifies the input that causes the machine to move from one state to another. Such machines are easy to depict with state transition diagrams. Once diagrammed it is straightforward to develop a parsing algorithm. Figure 7.1 shows the state transition diagram for parsing a CSV row. Figure 7.1. State Transition Diagram for Parsing a CSV Row In this diagram the circles show the various states and the arrows show the characters in the row that cause the movement between states. Generally, the states correspond to the nonterminal symbols in the CSV row grammar described above, and the transitions correspond to the terminal symbols in the grammar, that is, the characters in the row. However, we have added the transitional states of New Column, Start Delimited Column, and Finish Delimited Column. These all correspond to the delimiter characters. Those familiar with finite state automatons will note that this is not a fully specified state machine in two regards. We don't have a final accepting state; the machine simply terminates at the end of the CSV row. Also, we don't show transitions to a so-called "dump" state where we terminate due to unexpected input. For example, if we have just scanned the closing text delimiter of a delimited column and entered the Finish Delimited Column state, anything other than the column delimiter is invalid input and will move us into the dump state. Now, to turn this grammar and the state machine into not only a parsing approach but also a processing algorithm, we only need to add the actions that are performed during each state. This is simple since we're going to perform only two actions. First we save the input character to the DataCell object by calling the CSVRecordReader's saveCharacter method upon entering (or reentering) the Regular Column and Delimited Column states. Then we increment the column number each time we reenter the New Column state. Note that the algorithm includes "other" cases for unexpected input that correspond to moving to the dump state. Logic for the CSVRecordReader parseRecord MethodArguments: None Returns: Error status or throw exception Column Number <- 1 Column Grammars NodeList <- call Row Grammar Element's getElementsByTagName on "ColumnDescription" GrammarsIndex <- -1 Parsing State <- New Column DO until end of input record or Parsing State is Error Input Character <- Next character from input record DO CASE of Parsing State New Column: DO CASE of Input Character Column Delimiter: Increment Column Number BREAK Text Delimiter: Parsing State <- Start Delimited Column BREAK other: Call saveCharacter Parsing State <- Regular Column BREAK ENDDO BREAK Regular Column: DO CASE of Input Character Column Delimiter: Parsing State <- New Column Increment Column Number BREAK other: Call saveCharacter BREAK ENDDO BREAK Start Delimited Column: DO CASE of Input Character Text Delimiter: Parsing State <- Finish Delimited Column BREAK other: Call saveCharacter Parsing State <- Delimited Column BREAK ENDDO BREAK Delimited Column: DO CASE of Input Character Text Delimiter: Parsing State <- Finish Delimited Column BREAK other: Call saveCharacter BREAK ENDDO BREAK Finish Delimited Column: DO CASE of Input Character Column Delimiter: Parsing State <- New Column Increment Column Number BREAK other: Parsing State <- Error BREAK ENDDO BREAK ENDDO ENDDO IF Parsing State = Error Return error ENDIF Return success saveCharacterThe saveCharacter method is fairly straightforward. We create a new DataCell object if we're not currently processing one. We then save the input character to the DataCell's buffer. Logic for the CSVRecordReader saveCharacter MethodArguments: Character Input Character Returns: Integer GrammarIndex IF Parsing State is not Regular Column or Delimited Column Increment Grammar Index Grammar Column Number <- Call Column Grammar NodeList item(Grammar Index) getAttribute on "FieldNumber", and convert to integer DO while Grammar Column Number < Column Number Increment Grammar Index IF Column Grammar NodeList item(Grammar Index) is null return error ENDIF Grammar Column Number <- Call Column Grammar NodeList item(Grammar Index) getAttribute on "FieldNumber", and convert to integer ENDDO IF (Grammar Column Number > Column Number) return error ENDIF call RecordHandler's createDataCell method ENDIF Call DataCell Array[Highest Cell] putByte method to append Input Character to DataCell buffer Except for the new DataCell derived classes we'll develop in a later section in this chapter, this wraps up the design of our utility to convert from CSV files to XML documents. We'll next go over the design of the XML to CSV converter. Believe it or not, it is quite a bit simpler. |
EAN: 2147483647
Pages: 181