Indexes
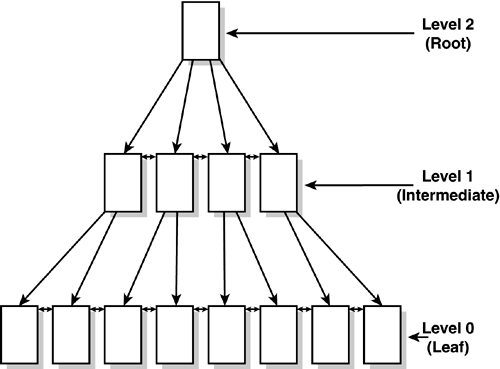
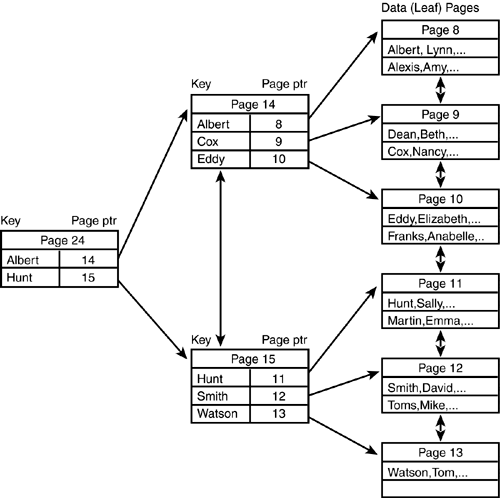
| When running a query against a table with no indexes, SQL Server has to retrieve every page of the table, looking at every row on each page to find out whether the row satisfies the search arguments. SQL Server has to scan all the pages because there's no way of knowing whether any rows found are the only rows that satisfy the search arguments. This search method is referred to as a table scan. For a heap table, a table scan is performed by traversing the IAM pages for the table and reading the pages within the extents allocated to the table in sequential order. For a table scan on a clustered table, SQL Server looks up the location of the root page of the clustered index (found in the root column in sysindexes where the indid is 1 ) and then finds its way to either the first or last page of the table, depending on whether it needs to do an ascending or descending scan, respectively. When it is at the first or last page in the table, it then follows the page chain to read the rest of the pages in the table. Needless to say, a table scan is not an efficient way to retrieve data unless you really need to retrieve all rows. The optimizer in SQL Server always calculates the cost of performing a table scan and uses that as a base line when evaluating other access methods. The various access methods and query plan cost analysis are discussed in more detail in Chapter 35. Suppose that the table is stored on 10,000 pages; even if only one row is to be returned or modified, all the pages must be searched, resulting in a scan of approximately 80MB of data. A mechanism is needed to identify and locate specific rows within a table quickly and easily. This functionality is provided through two types of indexes: clustered and nonclustered. Indexes are structures stored separately from the actual data pages that contain pointers to data pages or rows. Indexes are used to speed up access to the data; they are also the mechanism used to enforce the uniqueness of key values. Indexes in SQL Server are balanced trees (B-trees; see Figure 33.12). There is a single root page at the top of the tree, which branches out into N pages at each intermediate level until it reaches the bottom (leaf level) of the index. The leaf level has one row stored for each row in the table. The index tree is traversed by following pointers from the upper-level pages down through the lower-level pages. Each level of the index is linked as a doubly linked list. Figure 33.12. The basic structure of a B-tree index. An index can have many intermediate levels depending on the number of rows in the table, the index type, and the index key width. The maximum number of columns in an index is 16; the maximum row width is 900 bytes. Clustered IndexesWhen you create a clustered index, all rows in the table are sorted and stored in the clustered index key order. Because the rows are physically sorted by the index key, you can have only one clustered index per table. You can compare the structure of a clustered index to a filing cabinet: The data pages are like folders in a file drawer in alphabetical order, and the data rows are like the records in the file folder, also in sorted order. You can think of the intermediate levels of the index tree as the file drawers, also in alphabetical order, that assist you in finding the appropriate file folder. Figure 33.13 shows an example of a clustered index. Figure 33.13. The structure of a clustered index. In Figure 33.13, note that the data page chain is in clustered index order. However, unlike SQL Server versions prior to version 7.0, the rows on each page might not be physically sorted in clustered index order, depending on when rows were inserted or deleted in the page. SQL Server still keeps the proper sort order of the rows via the row IDs and the rowIDs are mapped to the appropriate row slot via the row offset table (refer to Figure 33.4). A clustered index is useful for range-retrieval queries or searches against columns with duplicate values because the rows within the range are physically located in the same page or on adjacent pages. The data pages of the table are also the leaf level of clustered index. To find all clustered index key values, SQL Server must eventually scan all the data pages. SQL Server performs the following steps when searching for a value using a clustered index:
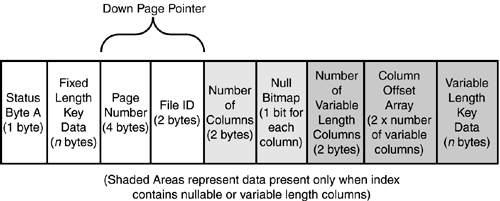
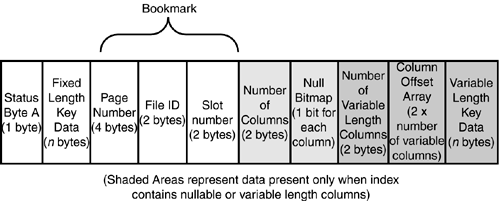
Clustered Index Row StructureThe structure of a clustered index row is similar to the structure of a data row and is detailed in Figure 33.14. Figure 33.14. Clustered index row structure. Notice that unlike a data row, index rows do not contain the status byte B or the 2 bytes to hold the length of fixed-length data fields. Instead of storing the length of the fixed-length data, which also indicates where the fixed-length portion of a row ends and the variable-length portion begins, the page header pminlen value is used to help describe an index row. The pminlen value is the minimum length of the index row, which is essentially the sum of the size of all fixed-width fields and overhead. Therefore, if no variable-length or nullable fields are in the index key, then pminlen also indicates the width of each index row. The null bitmap field and the field for the number of columns in the index row are present only when an index key contains nullable columns. The number of columns value is only needed to determine how many bits are needed in the null bitmap, and therefore how many bytes are required to store the null bitmap (1 byte per eight columns). The data contents of a clustered index row include the key values along with a 6-byte down-page pointer (the first 2 bytes are the file ID, and the last 4 bytes are the page number). The down-page pointer is the last value in the fixed-data portion of the row. To examine the contents of an index page, first create a table with a clustered index: create table index_test (id int identity, a char(5) not null, b char(10) null, c varchar(10) null) go insert index_test values ('11111', 'b1111', 'cxxxxxx') insert index_test values ('22222', 'b2222', 'cxxxxxx') insert index_test values ('33333', 'b3333', 'cxxxxxx') insert index_test values ('44444', 'b4444', 'cxxxxxx') insert index_test values ('55555', 'b5555', 'cxxxxxx') insert index_test values ('66666', 'b6666', 'cxxxxxx') insert index_test values ('77777', 'b7777', 'cxxxxxx') go create clustered index CI_index_test on index_test (a) go exec sp_SSU_showindexpages index_test go tablename id indid indexname root first firstiam ------------ ----------- ------ ------------ ---------- ---------- ---------- index_test 949578421 1 CI_index_tes 1:162 1:160 1:161 Now you can use DBCC PAGE to examine the root page of the clustered index. If you specify option 1 to DBCC PAGE , it displays the row contents in hex form: DBCC TRACEON(3604) DBCC PAGE (pubs, 1, 162, 1) go PAGE: (1:162) ------------- BUFFER: ------- BUF @0x191E3240 --------------- bpage = 0x324D2000 bhash = 0x00000000 bpageno = (1:162) bdbid = 5 breferences = 8 bstat = 0x9 bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x324D2000 ---------------- m_pageId = (1:162) m_headerVersion = 1 m_type = 2 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x20 m_objId = 949578421 m_indexId = 1 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 12 m_slotCnt = 1 m_freeCnt = 8082 m_freeData = 108 m_reservedCnt = 0 m_lsn = (5:60:13) m_xactReserved = 0 m_xdesId = (0:631) m_ghostRecCnt = 0 m_tornBits = 1 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = INDEX_RECORD Record Attributes = 324D2060: 31313106 00a03131 00010000 .11111...... The first byte, 06 , is the status A byte (remember the reverse byte order scheme used). Right after that is the actual data in the index key column data, 31 31 31 31 31 . After that is the down-page pointer, with the page number as the first 4 bytes ( 00 00 00 a0 ) followed by the file number as the last 2 bytes ( 0001 ). The page number equates to decimal page number 160 , which if you look at the output from sp_SSU_showindexpages is the address of the first data page (because there are so few rows and pages in the table, the index tree consists of only a single page). If this index has any nullable fields in it, there would be 3 additional bytes after the down-page pointer to hold the number of columns and the null bitmap. If there were any variable-length columns, the overhead columns and data would come after the fixed data or null bitmap in the index row just like they do in a data row. If you specify option 3 to DBCC PAGE , it displays the index page row contents as index pointers: dbcc traceon(3604) dbcc page (pubs, 1, 162, 3) go PAGE: (1:162) ------------- BUFFER: ------- BUF @0x191E3240 --------------- bpage = 0x324D2000 bhash = 0x00000000 bpageno = (1:162) bdbid = 5 breferences = 1 bstat = 0x9 bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x324D2000 ---------------- m_pageId = (1:162) m_headerVersion = 1 m_type = 2 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x20 m_objId = 949578421 m_indexId = 1 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 12 m_slotCnt = 1 m_freeCnt = 8082 m_freeData = 108 m_reservedCnt = 0 m_lsn = (5:60:13) m_xactReserved = 0 m_xdesId = (0:631) m_ghostRecCnt = 0 m_tornBits = 1 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED FileId PageId Row Level ChildFileId ChildPageId a ? ------ ----------- ------ ------ ----------- ----------- ----- ----------- 1 162 0 0 1 160 NULL NULL Another undocumented DBCC command to view the contents of an index is DBCC IND . This command displays information about all pages that belong to an index. The syntax for DBCC IND is as follows: DBCC IND ({'dbname' dbid }, {'objname' objid }, {indid 0 -1 -2 }) The values for the third parameter are described as follows:
Listing 33.5 shows an example of the output of DBCC IND . Listing 33.5 Sample Output from DBCC IND [View full width] DBCC TRACEON(3604) DBCC IND (pubs, index_test, 0) go PageFID PagePID IAMFID IAMPID ObjectID IndexID PageType IndexLevel Table 33.7 describes the columns contained in the DBCC IND output. Table 33.7. Description of Columns in DBCC IND
Nonunique Clustered IndexesWhen a clustered index is defined on a table, the clustered index keys are used as bookmarks to identify the data rows being referenced by nonclustered indexes (more on this in the upcoming section on nonclustered indexes). Because the clustered keys are used as unique row pointers, there needs to be a way to uniquely refer to each row in the table. If the clustered index is defined as a unique index, the key itself uniquely identifies every row. If the clustered index was not created as a unique index, SQL Server adds a 4-byte integer field, called a uniqueifier, to the data row to make each key unique when necessary. When is the uniqueifier necessary? SQL Server adds the uniqueifier to a row when the row is added to a table and that new row contains a key that is a duplicate of the key for an already existing row. The uniqueifier is added to the variable-length data area of the data row, which also results in the addition of the variable-length overhead bytes. Therefore, each duplicate row in a clustered index will have a minimum of 4 bytes of overhead added for the additional uniqueifier. If the row had no variable-length keys previously, then an additional 8 bytes of overhead will be added to the row to store the uniqueifier (4 bytes) plus the overhead bytes required for the variable data (storing the number of variable columns requires 2 bytes, and the column offset array requires 2 bytes). You can see the behavior of the uniqueifier in the following example: create table dupe_test (a char(5) not null) go insert dupe_test values ('11111') insert dupe_test values ('22222') go create clustered index CI_dupe_test on dupe_test (a) go Before adding a duplicate row, determine the address of the data page (it will be the first page as stored in sysindexes ): exec sp_SSU_showindexpages dupe_test go tablename id indid indexname root first firstiam ------------ ----------- ------ ------------ ---------- ---------- ---------- dupe_test 1525580473 1 CI_dupe_test 1:185 1:180 1:181 Now, take a look at the page with DBCC PAGE : DBCC TRACEON(3604) DBCC PAGE (pubs, 1, 180, 1) go PAGE: (1:180) ------------- BUFFER: ------- BUF @0x18FC0000 --------------- bpage = 0x21340000 bhash = 0x00000000 bpageno = (1:180) bdbid = 5 breferences = 1 bstat = 0x9 bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x21340000 ---------------- m_pageId = (1:180) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x24 m_objId = 1525580473 m_indexId = 0 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 9 m_slotCnt = 2 m_freeCnt = 8068 m_freeData = 120 m_reservedCnt = 0 m_lsn = (6:99:11) m_xactReserved = 0 m_xdesId = (0:885) m_ghostRecCnt = 0 m_tornBits = 1 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 21340060: 00090010 31313131 00000131 ....11111... Slot 1, Offset 0x6c ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 2134006C: 00090010 32323232 00000132 ....22222... OFFSET TABLE: ------------- Row - Offset 1 (0x1) - 108 (0x6c) 0 (0x0) - 96 (0x60) DBCC execution completed. If DBCC printed error messages, contact your system administrator. Now, add a duplicate row and examine the page again: insert dupe_test values ('22222') dbcc page (pubs, 1, 180, 1) go PAGE: (1:180) ------------- BUFFER: ------- BUF @0x18FC0000 --------------- bpage = 0x21340000 bhash = 0x00000000 bpageno = (1:180) bdbid = 5 breferences = 2 bstat = 0xb bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x21340000 ---------------- m_pageId = (1:180) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000 m_objId = 1525580473 m_indexId = 0 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 9 m_slotCnt = 3 m_freeCnt = 8046 m_freeData = 140 m_reservedCnt = 0 m_lsn = (6:109:2) m_xactReserved = 0 m_xdesId = (0:885) m_ghostRecCnt = 0 m_tornBits = 1 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 21340060: 00090010 31313131 00000131 ....11111... Slot 1, Offset 0x6c ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 2134006C: 00090010 32323232 00000132 ....22222... Slot 2, Offset 0x78 ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 21340078: 00090030 32323232 00000132 00140001 0...22222....... 21340088: 00000001 .... OFFSET TABLE: ------------- Row - Offset 2 (0x2) - 120 (0x78) 1 (0x1) - 108 (0x6c) 0 (0x0) - 96 (0x60) DBCC execution completed. If DBCC printed error messages, contact your system administrator. As you'll see in this example, the third row was added, but with some additional information. The binary string of 00140001 represents the number of variable-length columns ( 0001 ) and the column offset for the uniqueifier ( 0014 ), which indicates that the uniqueifier is at byte 20. The string at byte 20 is 00000001 , indicating that this is the first duplicate row. If we added another duplicate, its uniqueifier would be 2. When calculating the estimated size of a nonunique clustered index, you must remember to include the overhead for the uniquefier for the estimated number of duplicate values. Estimating Clustered Index SizeBecause clustered index rows contain only page pointers, the size and number of levels in a clustered index depends on the width of the index key and the number of pages in the table. The following pseudocode can be used to estimate the size of a clustered index key row: Sum (width of fixed-length key fields) + 1 byte (for Status Byte A) + 6 bytes (to store the down page pointer) + sum(avg(width of fixed-length key fields) + IF (variable length keys in index) THEN 2 -- for number of variable length columns + 2 * number of variable columns END IF + if (any index key column allows nulls) THEN 2 -- for number of columns + ceiling (numcols / 8) + 1 + if (nonunique index) + 4 -- for each duplicate value Assume that you have a unique clustered index on a char(10) column that doesn't allow null values. Your index row size would be the following:
Because the clustered index contains a pointer to each data page in the table, the number of rows at the bottom level of the index is equal to the number of pages in the table. If a table's data row size is 42 bytes, the total space required for each row is 44 bytes (42 bytes plus 2 bytes for each row's offset table entry). At 44 bytes per row, SQL Server can store a maximum of 184 data rows per data page (8096 bytes divided by 44 bytes per row). If the table has 100,000 rows, that works out to a minimum of 544 pages in the table (100,000 rows divided by 184 rows per page). Therefore, at least 544 rows would be in the lowest nonleaf level of the clustered index. Each index page, like a data page, has 8096 bytes available for storing index row entries. To determine the number of clustered index rows per page, divide the index row size into 8096 bytes and multiply by the fill factor percentage (fill factor is discussed later in this chapter). For this example, assume that the default fill factor is being applied, which leaves one slot available in the index pages, and the data pages are completely filled:
At 475 rows per page, SQL Server would need 544 rows/475 rows per page = 1.15, rounded up to two pages, to store all the rows at the lowest nonleaf level of the index. The top level of the index must be a single root page. You need to build levels on top of one another in the index until you reach a single root page. To determine the total number of levels in the index, use the following algorithm: N = 0 divide number of data pages by (number of index rows per page 1) while number of index pages at level N is > 1 begin divide number of pages at level N by (number of rows per page 1) N = N+1 end When the number of pages at level N equals 1 , you are at the root page, and N+1 equals the number of levels in the index. The total number of pages in the clustered index is the sum of all pages at each level. Applying this algorithm to the example gives the following results:
Thus, the index contains two levels, for a total size of three pages, or 24KB (3 pages times 8KB per page). The I/O cost of retrieving a single row by using the index is the number of levels in the index plus a single data page read. Contrast this with the cost of a table scan for the example:
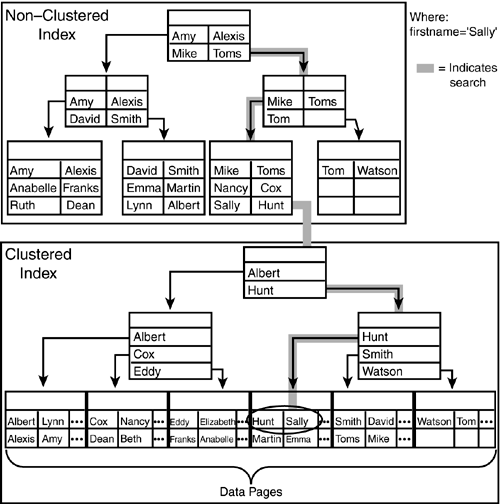
You can easily see the performance advantage that having an index on the table can provide during a SELECT . An index is also helpful during data modifications to quickly identify the rows to be updated or deleted. Nonclustered IndexesA nonclustered index is a separate index structure, independent of the physical sort order of the data rows in the table. You can have up to 249 nonclustered indexes per table. You can think of a nonclustered index as the index in the back of a book. To find the pages on which a specific subject is discussed, you look up the subject in the index and then go to the pages referenced in the index. This is an efficient method as long as the subject is discussed on only a few pages. If the subject is discussed on many pages, or if you want to read about many subjects, it can be more efficient to read the entire book. A nonclustered index works similarly to the book index. From the index's perspective, the data rows are randomly spread throughout the table. The nonclustered index tree contains the index key values in sorted order. There is a row at the leaf level for each data row in the table. Each leaf level row contains a "bookmark" to locate the actual data row in the table. If no clustered index is created for the table, the bookmark for the leaf level of the index is an actual pointer to the data page and the row number within the page where the row is located (see Figure 33.15). Figure 33.15. A nonclustered index on a heap table. Versions of SQL Server prior to 7.0 stored only the row locators (the RowId ) in nonclustered indexes to identify the data row that the index key referenced. If the table had a clustered index defined on it and a page split occurred (as a result of an INSERT or UPDATE ), many rows were moved to another page (page splits will be covered in more detail later in this chapter). All corresponding rows in the nonclustered indexes had to be modified to reflect the new row IDs. This made page splits costly. Page splits do not occur with heap tables as all new rows are simply added at the end of the table. In SQL Server 7.0 and 2000, nonclustered indexes on clustered tables no longer include the data row ID as part of the index. Instead, the bookmark for the nonclustered index is the associated clustered index key value for the record. When SQL Server reaches the leaf level of a nonclustered index, it uses the clustered index key to start searching through the clustered index to find the actual data row (see Figure 33.16). This adds a few I/Os to the search itself, but the benefit is that if a page split occurs in a clustered table, or if a row is moved (for example, as a result of an update), the nonclustered indexes stay the same. As long as the clustered index key is not modified, no row pointers in the index have to be updated. Figure 33.16. A nonclustered index on a clustered table. SQL Server performs the following steps when searching for a value using a nonclustered index:
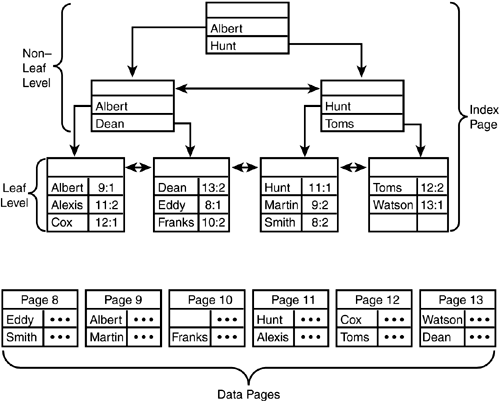
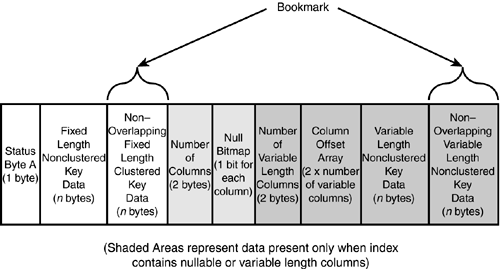
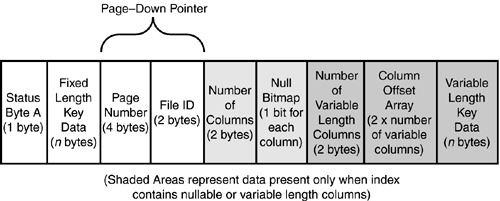
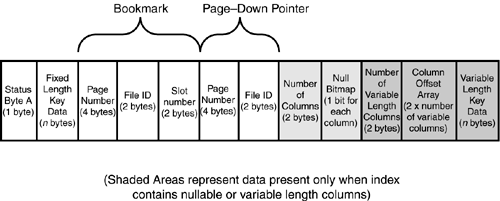
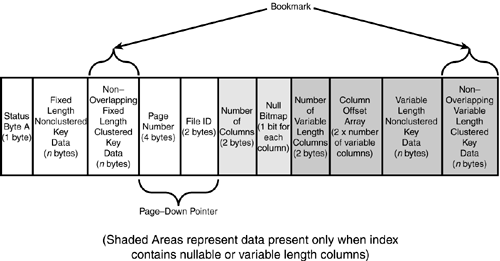
Nonclustered Index Leaf Row StructuresIn nonclustered indexes, if the bookmark is a row ID, it is stored at the end of the fixed-length data portion of the row. The rest of the structure of a nonclustered index leaf row is similar to a clustered index row. Figure 33.17 shows the structure of a nonclustered leaf row for a heap table. Figure 33.17. The structure of a nonclustered index leaf row for a heap table. If the bookmark is a clustered index key value, the bookmark resides in either the fixed or variable portion of the row, depending on whether the clustered key columns were defined as fixed or variable length. Figure 33.18 shows the structure of a nonclustered leaf row for a clustered table. Figure 33.18. The structure of a nonclustered index leaf row for a clustered table. When the bookmark is a clustered key value and the clustered and nonclustered indexes share columns, the data value for the key is stored only once in the nonclustered index row. For example, if your clustered index key is on lastname and you have a nonclustered index defined on both firstname and lastname , the index rows will not store the value of lastname twice but only once for both keys. You can examine the differences in the index row structures using DBCC PAGE . First, create the following table and indexes: create table nc_ci_test (a char(4) not null, b varchar(8) null, c char(4) null, d char(4) not null) go insert nc_ci_test values ('aaaa', 'bbbb', 'cccc', 'dddd') go create index idx_2col on nc_ci_test (a, b) create index idx_null on nc_ci_test (c) go Now, find out the page numbers (because the table is so small, the root page is also the leaf page of the nonclustered index): exec sp_ssu_showindexpages nc_ci_test go tablename id indid indexname root first firstiam ------------ ----------- ------ ------------ ---------- ---------- ---------- nc_ci_test 1685581043 0 nc_ci_test 1:196 1:196 1:197 nc_ci_test 1685581043 2 idx_2col 1:198 1:198 1:199 nc_ci_test 1685581043 3 idx_null 1:224 1:224 1:226 You can use DBCC PAGE to examine the leaf row structure of the idx_null index (to save space, only the row information from DBCC PAGE is displayed): DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP 1A8B2060: 63636316 0000c463 00000100 00000300 .cccc........... As you can see, the fixed-length data ( 63 63 63 63 ) is at the front of the index record, right after status byte A ( 16 ). After the index key value in the fixed-length portion is the row pointer, consisting of the page ID ( 000000c4 , decimal 196), the file ID ( 0001 ), and the row ID on the page ( 0000 , because the first row on a page has a row ID of 0). After that is the information for the null bitmap because column c allows nulls. The number of columns ( 0003 ) represents the three pieces of information stored in the index rowthe key data for c , the down-page pointer, and the row ID. Next, you can use DBCC PAGE to look at the row information for the idx_2col index, which has both fixed- and variable-length columns in it: DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = INDEX_RECORD Record Attributes = VARIABLE_COLUMNS 1A854060: 61616126 0000c461 00000100 15000100 &aaaa........... 1A854070: 62626200 62 .bbbb You can see the structure is similar for the fixed-length data portion up to byte 13. Because neither column is nullable, there is no null bitmap. The value for column b is stored at the end of the row, after the number of variable-length columns ( 0001 ) and the column offset ( 0015 ). Both of these indexes are on a heap table, so the bookmark is the page and row pointer. Now, create a clustered index on the table: create clustered index idx_clust on nc_ci_test(b) With a clustered index on the table, the nonclustered indexes will all be rebuilt and the bookmark changed to the clustered index key. Using DBCC PAGE to examine the index row for the idx_null index shows the following: DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1A8B0060: 63636336 00000363 00100001 62626262 6cccc.......bbbb Here you can see that the page and row pointer are no longer in the fixed-length section of the row, and the clustered key value for the row ( bbbb ) is stored in the variable-length portion of the row because column b is a variable-length key. Using DBCC PAGE to examine the index row for the idx_2col index, which already contains column b in the nonclustered index, shows the following: DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1A8BE060: 61616136 00000361 00100001 62626262 6aaaa.......bbbb Notice from this output how column b is in the index row only once, even though it is part of both the clustered and nonclustered index. Nonclustered Index Nonleaf Row StructuresThe nonclustered index nonleaf rows are similar in structure to clustered index nonleaf rows in that they contain a page-down pointer to a page at the next level down in the index tree. The nonleaf rows don't need to point to data rows; they only need to provide the path to traverse the index tree to a leaf row. If the nonclustered index is defined as unique, the nonleaf index key row contains only the index key value and the page-down pointer. Figure 33.19 shows the structure of a nonleaf index row for a unique nonclustered index. Figure 33.19. The structure of a nonclustered nonleaf index row for a unique index. If the nonclustered index is not defined as a unique index, the nonleaf rows will also contain the bookmark information for the corresponding data row. Storing the bookmark in the nonleaf index row allows any corresponding nonleaf index rows to be located and deleted more easily when the data row is deleted. For a heap table, the bookmark is the corresponding data row's page and row pointer, as shown in Figure 33.20. Figure 33.20. The structure of a nonclustered nonleaf index row for a nonunique index on a heap table. If the table is clustered, the clustered key value(s) are stored in the nonleaf index row just as they are in the leaf rows, as shown in Figure 33.21. Figure 33.21. The structure of a nonclustered nonleaf index row for a nonunique index on a clustered table. As you can see, it's possible for the index pointers and row overhead to exceed the size of the index key itself. This is why, for I/O and storage reasons, it is always recommended that you keep your index keys as small as possible. Estimating Nonclustered Index SizeBecause nonclustered indexes contain a record for each row in the table, the size and number of levels in a nonclustered index depends on the width of the index key and the number of rows in the table. Because so many factors influence the structure of the index row (unique or nonunique, clustered table or heap), the formula for determining the width of a nonclustered leaf index row is a bit more complicated. The one constant component is the fixed-length portion. Everything else is dependent on the index definition and whether the table has a clustered index. The following pseudocode provides the formula for estimating the size of a nonclustered index leaf row: 1 -- for status byte A + sum(width of fixed-length index keys) + sum (width of variable length keys in nonclustered index) + CASE WHEN index on heap THEN 8 -- size of bookmark, a page and row pointer WHEN index on clustered table THEN sum(width of non-overlapping fixed-length clustered keys) + sum(avg(width ofnon-overlapping variable length clustered keys)) + IF (nonunique clustered index and duplicate row) then 4 -- bytes for uniqueifier END IF END CASE + CASE when variable columns in nonclusterd key or clustered key bookmark then 2 bytes -- for number of variable columns + 2 * number of variable columns -- for column offset array ELSE 0 END CASE + CASE WHEN nullable column in nonclusterd key or clustered key bookmark THEN 2 bytes -- for number of columns in index + ceiling (number of columns / 8) -- for NULL bitmap ELSE 0 END CASE + Refer back to the idx_null index on the nc_ci_test table defined earlier. The size of the index before the table had a clustered index on it would be estimated as follows:
The size of the idx_2col index before the table had a clustered index created on it would be estimated as follows:
The size of the idx_2col index after the table had a clustered index created on it would be estimated as follows:
Because the leaf level of a nonclustered index contains a pointer to each data row in the table, the number of rows at the leaf level of the index is equal to the number of rows in the table. If there are 100,000 rows in the table, there will be 100,000 rows in the leaf level of the nonclustered index. Each nonclustered index page, like a data page, has 8096 bytes available for storing index row entries. To determine the maximum number of nonclustered leaf index rows per page, divide the leaf index row size into 8096 bytes. For this example, assume that a fill factor of 75 percent is used when the index is created so that the leaf pages are 75 percent filled, and the nonleaf pages have one free slot available. The number of rows per page for the leaf level of the idx_2col nonclustered index with a 16-byte index row would be calculated as follows:
At 379 rows per page, SQL Server would need 100,000/379 = 265.85, rounded up to 266 pages, to store all the rows at the leaf level of the index. The size of the nonleaf index rows can be calculated according to the following pseudocode: 1 -- for status byte A + sum(width of fixed-length index keys) + sum (width of variable length keys in nonclustered index) + 6 -- size of page-down pointer + IF non-unique index then CASE when heap table then 8 size of bookmark for heap else sum(width of non-overlapping fixed-length clustered keys) + sum(avg(width ofnon-overlapping variable length clustered keys)) + IF (nonunique clustered index and duplicate row) then 4 -- bytes for uniqueifier END IF END IF + CASE when variable columns in nonclusterd key or clustered key bookmark then 2 bytes -- for number of variable columns + 2 * number of variable columns -- for column offset array else 0 END CASE + CASE when nullable column in nonclusterd key or clustered key bookmark then 2 bytes -- for number of columns in index + ceiling (number of columns / 8) else 0 END CASE For the idx_2col index, the size of the nonleaf rows after the clustered index is created would be calculated as
To determine the number of nonleaf index rows per page for a nonclustered index, divide the nonleaf index row size into 8096 bytes and apply the fill factor. Unless you specify the PAD_INDEX along with the FILL_FACTOR option when creating an index, SQL Server always leaves one free slot available in the nonleaf pages. Therefore, the number of nonleaf rows for the index in our example would be
Like the clustered index, the top level of the index must be a single root page. You need to build levels on top of one another in the index until you reach a single root page. To determine the total number of levels in the nonclustered index, use the following algorithm: N = 0 divide number of data rows by number of leaf index rows per page to determine the number of leaf level pages while the number of index pages at level N is > 1 begin divide the number of pages at level N by (the number of nonleaf rows per page 1) N = N+1 end When the number of pages at level N equals 1 , you are at the root page, and N+1 equals the number of levels in the index. The total size of the nonclustered index in number of pages is the sum of the number of pages at each level. If you apply this algorithm to the example, you get the following results:
Thus, the nonclustered index contains two levels, for a total size of 265 8KB pages, or 2,120KB. Notice that this is larger than the clustered index, which required only three pages (24KB). The maximum I/O cost of retrieving a single row by using a nonclustered index on a heap table is the number of levels in the index plus a single data page read. If the table has a clustered index on it (resulting in the clustered key being used as the bookmark in the nonclustered index), the maximum I/O cost is the number of levels in the nonclustered index, plus the number of levels in the clustered index, plus the data page read. Although nonclustered indexes provide a performance advantage during a select and are helpful during data modifications to quickly identify rows to be updated or deleted, they can also add overhead during data modifications, as you'll see in the remainder of this chapter. Estimated Index Size Versus Actual SizeIf you want to confirm the amount of space actually being used by your tables and indexes, you can query the information stored in the sysindexes table, or use the supplied sp_spaceused system procedure: use bigpubs2000 go exec sp_spaceused sales_big go name rows reserved data index_size unused ------------ --------- -------------- -------------- -------------- --------- sales_big 1687250 476904 KB 273088 KB 50432 KB 153384 KB After a table takes up more than eight pages of space, SQL Server begins allocating uniform extents to the table. As you'll recall from earlier in this chapter, uniform extents can only contain data from a single table. When a uniform extent is allocated to a table, not all of its pages are necessarily going to have data on them right away. However, because no other table can use the rest of the extent, the remaining pages in the extent are "reserved" for use by that table or index. SQL Server always attempts to use free pages in extents already allocated to a table or index before allocating an additional extent. The reserved column therefore represents all the space currently allocated to the table and its indexes, data is the amount of the reserved space that contains data rows, and index_size is the total size of the allocated pages containing index rows. The unused column represents the pages allocated to the table and its indexes that are not yet being used either for data or for index rows. If you want to determine at a finer level how much space each individual index is using, you can run the following query: select convert(varchar(20), object_name(id)) as 'table', convert(varchar(20), name) as 'index', indid, reserved * 8 as 'reserved', dpages * 8 as 'data', (reserved - used) * 8 as 'unused' from sysindexes where id = object_id('sales_big') and isnull(indexproperty(id, name, 'isautostatistics'), 0) = 0 go table index indid reserved data unused ---------------- ---------------- ------ ----------- ----------- ----------- sales_big ci_sales_big 1 476904 273088 153384 sales_big idx1 2 73400 31568 36736 When the indid is 0 or 1, the reserved , data , and unused values apply for the entire table and its indexes and are essentially what is displayed by sp_spaceused . However, at the individual index level, the values are for that index only, so you can see just how many pages are allocated and being used by the indexes themselves . Unfortunately, the information in sysindexes is not always kept up-to-date as data in the table is modified. To update the usage information, execute sp_spaceused and specify true as the value for the second parameter, @updateusage : exec sp_spaceused sales_big, @updateusage = 'true' go name rows reserved data index_size unused ----------- ---------- ------------ ------------- ------------- --------- sales_big 1687250 306000 KB 273088 KB 32608 KB 304 KB When the @updateusage option is specified, SQL Server first updates the usage information for the table and its indexes and then reports it. You can also run the DBCC UPDATEUSAGE command directly: DBCC UPDATEUSAGE ( database [, table [. index ]]] [ WITH [ COUNT_ROWS ] [ , NO_INFOMSGS ] When you run this command, it updates the usage information and reports the changes it makes: DBCC UPDATEUSAGE (bigpubs2000, sales_big) go DBCC UPDATEUSAGE: sysindexes row updated for table 'sales_big' (index ID 2): USED pages: Changed from (4583) to (3960) pages. RSVD pages: Changed from (9175) to (3969) pages. DBCC UPDATEUSAGE: sysindexes row updated for table 'sales_big' (index ID 1): USED pages: Changed from (40440) to (38212) pages. RSVD pages: Changed from (59613) to (38250) pages. DBCC execution completed. If DBCC printed error messages, contact your system administrator. SQL Server Index MaintenanceSQL Server indexes are self-maintaining, which means that any time a data modification (such as an update, delete, or insert) takes place on a table, the index B-tree is automatically updated to reflect the correct data values and current rows. Generally , you do not have to do any maintenance of the indexes, but indexes and tables can become fragmented over time. There are two types of fragmentation: external fragmentation and internal fragmentation. External fragmentation is when the logical order of pages does not match the physical order or when the extents in use by the table are not contiguous. These situations occur typically with clustered tables as a result of page splits and pages being allocated and linked into the page chain from other extents. External fragmentation is usually not much of an issue for most queries that are performing small resultset retrievals via an index. It's more of a performance issue for ordered scans of all or part of a table or index. If the table is heavily fragmented and the pages are not contiguous, scanning the page chain will be more expensive. Internal fragmentation occurs when an index is not using up all space within the pages in the table or index. Fragmentation within an index page can happen for the following reasons:
Usually in a system, all these factors contribute to the fragmentation of data within the data pages and the index pages. In an environment with a lot of data modification, you might see a lot of fragmentation on the data and index pages over a period of time. These sparse and fragmented pages remain allocated to the table or index even if they have only a single row or two, and the extent containing the page remains allocated to the table or index. Data fragmentation adversely impacts performance because the data is spread across more pages than necessary. More I/Os will be required to retrieve the data. SQL Server provides a DBCC command to monitor the level of fragmentation in the database. The syntax for this command is DBCC SHOWCONTIG({ table view }[, index ]) [ WITH {ALL_INDEXES FAST [ , ALL_INDEXES ] TABLERESULTS [ , {ALL_INDEXES }] [ , {FAST ALL_LEVELS }] } ] You can use the TABLERESULTS option to receive the output from DBCC SHOWCONTIG as a table resultset, which could be inserted into a table for historical or analysis purposes. The following is an example of a table that has a fair amount of internal fragmentation: DBCC SHOWCONTIG(io_test) go DBCC SHOWCONTIG scanning 'io_test' table... Table: 'io_test' (1845581613); index ID: 1, database ID: 5 TABLE level scan performed. - Pages Scanned................................: 335 - Extents Scanned..............................: 45 - Extent Switches..............................: 45 - Avg. Pages per Extent........................: 7.4 - Scan Density [Best Count:Actual Count].......: 91.30% [42:46] - Logical Scan Fragmentation ..................: 8.66% - Extent Scan Fragmentation ...................: 46.67% - Avg. Bytes Free per Page.....................: 3906.7 - Avg. Page Density (full).....................: 51.73% Notice that the Avg. Page Density (full) is 51.73 percent and the Avg. Bytes Free per Page is 3906.7 bytes. This indicates that the majority of pages in the table are only half full. This is wasting space and costing extra I/O when retrieving data. The Scan Density is relatively high, so the table is not too externally fragmented yet at this point. After you determine that data is fragmented, SQL Server provides a couple of different methods for you to reorganize the data on index and data pages so that each page is filled to an optimal level. One method available is the DBCC INDEXDEFRAG command: DBCC INDEXDEFRAG ( 'database ', {' table ' ' view' }, index_name ) [WITH NO_INFOMSGS] DBCC INDEXDEFRAG eliminates the internal defragmentation in an index, compacting the index or data rows and removing any completely emptied pages from the index. DBCC INDEXDEFRAG can defragment clustered and nonclustered indexes on tables and views. DBCC INDEXDEFRAG also defragments the leaf level of an index so that the physical order of the pages matches the logical order of the index leaf nodes, thereby improving index-scanning performance. DBCC INDEXDEFRAG does not hold locks long term while it runs and doesn't lock the entire table, so it can be run online and will not block concurrently running queries or updates. If you were to run DBCC INDEXDEFRAG on the io_test table in the previous example, it should compact the rows in the clustered index, increasing the number of rows per page, thereby reducing the number of I/Os: DBCC INDEXDEFRAG (pubs, io_test, 1) go Pages Scanned Pages Moved Pages Removed ------------- ----------- ------------- 331 164 165 You can check the results by running DBCC SHOWCONTIG again: DBCC SHOWCONTIG(io_test) go DBCC SHOWCONTIG scanning 'io_test' table... Table: 'io_test' (1845581613); index ID: 1, database ID: 5 TABLE level scan performed. - Pages Scanned................................: 170 - Extents Scanned..............................: 25 - Extent Switches..............................: 25 - Avg. Pages per Extent........................: 6.8 - Scan Density [Best Count:Actual Count].......: 84.62% [22:26] - Logical Scan Fragmentation ..................: 0.59% - Extent Scan Fragmentation ...................: 48.00% - Avg. Bytes Free per Page.....................: 187.7 - Avg. Page Density (full).....................: 97.68% As you can see, the Avg. Page Density (full) is now 97.68 percent, and the Avg. Bytes Free per Page is only 187.7 bytes. Another method that can be used to defragment your data and indexes is to rebuild the indexes. You can do this manually by running a series of DROP INDEX and CREATE INDEX commands, usually in a T-SQL script file. This can be a tedious process that runs the risk of an index not getting rebuilt if it's missing from the SQL script. Also, if you run out of space while rebuilding an index, the CREATE INDEX command fails leaving you without that index on the table. A better way of rebuilding all indexes is to use the DBCC DBREINDEX command: DBCC DBREINDEX ([ 'database.owner.table_name ' [, index_name [, fillfactor ]]]) [WITH NO_INFOMSGS]
Using DBCC DBREINDEX alleviates you from having to specify all the indexes you want to drop and re-create on a table (if you specify just the table name, it automatically rebuilds all indexes). In addition, if DBCC DBREINDEX fails while processing for some reason (out of space, out of locks, and so on), the rebuild is rolled back and the original indexes are left in place. The following example runs DBCC DBREINDEX on io_test and reruns DBCC SHOWCONTIG to see whether any external fragmentation is eliminated: DBCC DBREINDEX (io_test) DBCC SHOWCONTIG(io_test) go DBCC execution completed. If DBCC printed error messages, contact your system administrator. DBCC SHOWCONTIG scanning 'io_test' table... Table: 'io_test' (1845581613); index ID: 1, database ID: 5 TABLE level scan performed. - Pages Scanned................................: 168 - Extents Scanned..............................: 22 - Extent Switches..............................: 21 - Avg. Pages per Extent........................: 7.6 - Scan Density [Best Count:Actual Count].......: 95.45% [21:22] - Logical Scan Fragmentation ..................: 10.71% - Extent Scan Fragmentation ...................: 72.73% - Avg. Bytes Free per Page.....................: 119.8 - Avg. Page Density (full).....................: 98.52% Because the table wasn't overly fragmented, you don't see a dramatic improvement, but the table is more compact than it was originally, using fewer pages and extents. One of the options to the CREATE INDEX and DBCC DBREINDEX commands is the Fill Factor option. Fill factor allows you to specify the fullness of the pages at the data and leaf index page levels as a percentage. Setting the Fill FactorFill factor is a setting provided when creating an index that specifies, as a percentage, how full you want your data pages or leaf level index pages to be when the index is created. A lower fill factor has the effect of spreading the data and leaf index rows across more pages by leaving more free space in the pages. This reduces page splitting and dynamic reorganization of index and data pages, which can improve performance in environments where there are a lot of inserts and updates to the data. A higher fill factor has the effect of packing more data and index rows per page by leaving less free space in the pages. This is useful in environments where the data is relatively static because it reduces the number of pages required for storing the data and its indexes, and helps improve performance for queries by reducing the number of pages that need to be accessed. By default, when you create an index on a table, if you don't specify a value for FILLFACTOR , the default value is zero. With a FILLFACTOR setting of , or 100 , the data pages for a clustered index and the leaf pages for a nonclustered index are created completely full. However, space is left within the nonleaf nodes of the index for one or two more rows. The default fill factor to be used when creating indexes is a server level configuration option. If you want to change the serverwide default for the fill factor, use the sp_configure command: sp_configure 'fill factor', N It is generally recommended that you leave the serverwide default for fill factor as because, typically, you will specify the fill factor to be used for an index within the index creation statement. You can override the default fill factor value by specifying the FILLFACTOR option for the CREATE INDEX statement: CREATE [UNIQUE] [CLUSTERED NONCLUSTERED] INDEX index_name ON table ( column [, ... n ]) [WITH [[,] FILLFACTOR = fillfactor ] [PAD_INDEX] The FILLFACTOR option for the CREATE INDEX command allows you to specify, as a percentage, how full the data or leaf level index pages should be when you create an index on a table. The specified percentage can be from 1 to 100 . Specifying a value of 80 would mean that each data or leaf page would be filled approximately 80 percent full at the time you create the index. It is important to note that as more data gets modified or added to a table, the fill factor is not maintained at the level specified during the CREATE INDEX command. Over a period of time, you will find that each page has a different percentage of fullness as rows are added and deleted.
If you specify only the FILLFACTOR option, only the data or leaf level index pages are affected by the fill factor. To specify the level of fullness for nonleaf pages, use the PAD_INDEX option together with FILLFACTOR . This option allows you to specify how much space to leave open on each node of the index, which can help to reduce page splits within the nonleaf levels of the index. You don't specify a value for PAD_INDEX ; it uses the same percentage value that is specified with the FILLFACTOR option. For example, to apply a 50 percent fill factor to the leaf and nonleaf pages in a nonclustered index on title_id in the titles table, execute the following: CREATE INDEX title_id_index on titles (title_id) with FILLFACTOR = 50, PAD_INDEX
Reapplying the Fill FactorWhen might you need to re-establish the fill factor for your indexes or data? As data gets modified in a table, the value of FILLFACTOR is not maintained at the level specified during the CREATE INDEX statement. As a result, each page can reach a different level of fullness. Over a period of time, this can lead to heavy fragmentation in the database if insert/delete activity is not evenly spread throughout the table and could impact performance. In addition, if a table becomes very large and then very small, rows could become isolated within data pages. This space will likely not be recovered until the last row on the page is deleted and the page is marked as unused. To either spread rows out or to reclaim space by repacking more rows per page, you need to reapply the fill factor to your clustered and nonclustered indexes. In environments where insert activity is heavy, reapplying a low fill factor might help performance by spreading out the data and leaving free space on the pages, which helps to minimize page splits and possible page-locking contention during heavy OLTP activity. You can use Performance Monitor to monitor your system and determine whether excessive page splits are occurring (see Chapter 37 for more information on using Performance Monitor). The DBA must manually reapply the fill factor to improve performance of the system. This can be done using the DBCC DBREINDEX command discussed earlier, or by dropping and re-creating the index. DBCC DBREINDEX is preferred because, by default, it will apply the original fill factor specified when the index was created, or you can provide a new fill factor to override the default. The original fill factor for an index is stored in sysindexes in the OrigFillFactor column. Additionally, if you use the DBCC INDEXDEFRAG command to defragment your table or index, it attempts to apply the index's original fill factor when it compacts the pages.
|
EAN: 2147483647
Pages: 503