Guidelines for Partitioning a Process into Multiple Application Domains
|
| If you're building an application that relies on application domains for isolation, especially one in which you'll be running code that comes from other vendors, determining how to partition your process into multiple domains is one of the most critical architectural decisions you'll make. Choosing your domain boundaries incorrectly can lead to poor performance or overly complex implementations at best, and security vulnerabilities or incorrect results at worst. Oftentimes, determining your domain boundaries involves mapping what you know about application domain isolation into some existing concept in your application model. For example, if you have an existing application that currently relies on a process boundary for isolation, you might consider replacing that boundary with an application domain boundary for managed code. Earlier in the chapter, I described how the presence of the CLR enabled the ASP team to move from a process boundary in their first few versions to an application domain model in ASP.NET. However, replacing a process boundary with a domain boundary clearly isn't the only scenario in which application domains apply. Application domains often fit well into applications that have an existing extensibility model, but haven't used process isolation in the past because of the cost or other practical reasons. A typical example is an application that supports an add-in model. Consider a desktop application that enables users to write add-ins that extend the functionality of the application. In the unmanaged world, these extensions are commonly written as COM DLLs that are loaded inprocess with the main application. If the user loads multiple add-ins, you'll end up with several of these DLLs running in the same address space. In many unmanaged applications, often it isn't practical for the application author to isolate these DLLs in separate processes. Performance is always a concern, but it also might be the case that process isolation just doesn't fit with the application model. For example, the add-ins might need to manipulate an object model published by the application. Application domains work very well in scenarios such as these because they are lightweight enough to be used for isolation where a process boundary is too costly. Earlier in the chapter, I talked about the various aspects of domain isolation, including access to types, scoping of configuration data, and security policy. Whether you're incorporating managed code into an existing extensible application or writing a new application from scratch, these criteria are a primary factor in determining where your domain boundaries lay. However, you must keep in mind other considerations as well. Performance, reliability, and the ability to unload code from a running process are all directly related to application domains and must be carefully considered. In particular, your design should be geared toward reducing the number of calls made between domains and should consider your requirements for unloading code from a running process. Code UnloadingYou might need to unload code from a running process in various scenarios, such as when you want to reduce the working set or phase out the use of an older version of an assembly when a new version is available. To remove managed code from a process, you must unload the entire domain containing the code you want to remove. Individual assemblies or types cannot be unloaded. No underlying technical constraint forces this particular design, and in fact, the ability to unload an individual assembly is one of the most highly requested CLR features. It's quite possible that some day the CLR will support unloading at a finer granularity, but for now, the application domain remains the unit at which code can be removed from a process. The nature of an application domain as the unit for unloading almost always plays a very significant role in how you decide to partition your process into multiple application domains. In fact, I've seen several cases in which a process is partitioned into multiple application domains for this reason alone. If you have a specific need to unload individual pieces of code, you must load that code into a separate application domain so it can be removed without affecting the rest of the process. For more details on unloading, including how to unload application domains programmatically, see the section "Unloading Application Domains" later in this chapter. Cross-Domain CommunicationCalls between objects in different application domains go through the remoting infrastructure just as calls between processes or machines do. As a result, a performance cost is associated with making a call from an object in one application domain to an object in another domain. The cost of the call isn't nearly as expensive as a cross-process call, but nevertheless, the cost can be significant depending on the number of calls you make and the amount of data you pass on each call. This cost must be carefully considered when designing your application domain model. Performance isn't the only reason for minimizing the amount of cross-domain calls, however. As described, the CLR maintains proxies that arbitrate calls between objects in different application domains. One of these proxies exists in the application domain of the code making the call (the caller), and one exists in the domain that contains the code being called (the callee). To provide type safety and to support rich calling semantics, the proxies on either side of the call must have the type definition for the object being called. So, the assembly containing the object you are calling must be loaded into both application domains. Making an assembly visible to multiple application domains complicates your approach to deployment. Every domain has a property that describes the root directory under which it will search for private assemblies (i.e., assemblies visible only to that domain). In many cases, placing assemblies in this directory or one of its subdirectories is all you need. You've probably used this technique either with executables launched from the command line or ASP.NET applications. Deploying assemblies in this way is convenient and extremely easy. Unfortunately, the story isn't quite as straightforward for assemblies that must be visible to multiple domains. These assemblies are referred to as shared assemblies. Shared assemblies have different naming and deployment requirements than private assemblies do. First, shared assemblies must have a strong name. A strong name is a cryptographically strong, unique name that the CLR uses to uniquely identify the code and to make security checks. Second, unless you customize how assemblies are loaded (see Chapter 8), assemblies with strong names must be placed in either the global assembly cache (GAC) or in a common location identified through a configuration file. When placed in one of these locations, the ability to delete or replicate your application just by moving one directory tree is lost. Furthermore, shared assemblies deployed in this manner are visible to every application on the machine. In general, this might be OK, but it does open the possibility that your assembly could be used for purposes other than you originally intended, which should make you uneasy regarding security attacks. In short, making an assembly visible to more than one application domain requires some extra steps and is harder to manage. A process is partitioned into application domains most efficiently when the amount of crossdomain communication is limited, for the reasons I've just described: the performance is better and the deployment story is more straightforward. However, communication between application domains cannot be completely eliminated. If it were, there would be no way to load and run a type in a domain other than the one in which you were running! Typical extensible applications, whether written entirely in managed code or written using the CLR hosting interfaces, contain at least one assembly that is loaded into every domain in the process. This assembly is part of the implementation of the extensible application and provides basic functionality, including creating and configuring new application domains and running the application's extensions in those domains. Throughout the remainder of this chapter, I refer to these assemblies as HostRuntime assemblies. In the most efficient designs almost all communication between application domains goes through these HostRuntime assemblies. The key is to partition your process in such a way that the add-ins you load into individual application domains have little or no need to communicate with each otherthe less cross-domain communication you have, the better your performance will be. Figure 5-5 shows a scenario in which the communication between domains is limited to the HostRuntime assemblies. Figure 5-5. Communication between domains through HostRuntime assemblies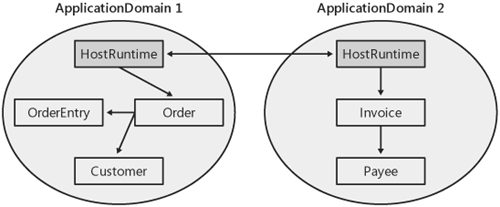 Sample Application Domain BoundariesOften, the best way to understand how to partition your process into multiple application domains is to look at some examples of how other products have done it. In this section, I discuss the designs adopted by existing CLR hosts, including ASP.NET, SQL Server, and Internet Explorer. ASP.NETThe Microsoft IIS Web server enables multiple Web sites to be hosted on the same physical machine through virtual roots. Each virtual root appears as its own site when accessing the Web server. Each virtual root has a base directory under which all content and code for that Web application are stored. In ASP.NET each virtual root is mapped to an application domain. That is, all code running in a particular application domain either originates in the virtual root's base directory (or a subdirectory thereof) or is referenced from a page or code contained in that directory. By aligning virtual roots and application domains, ASP.NET uses domains to make sure that multiple Web applications running in the same process are isolated from each other. Note, too, that all instances of particular Web applications are not necessarily run in the same application domain. That is, ASP.NET load balances instances of the application across multiple domains in multiple processes. So, although it's always true that a particular domain contains code from only one application, it is not necessarily true that all instances of the application run in the same domain. ASP.NET's implementation of application domains is a perfect example of mapping a domain model to an existing construct that defines an application model (i.e., a virtual directory). SQL ServerSQL Server 2005 maps the database concept of a schema to an application domain. A schema is a collection of database objects that are owned by a single user and form a namespace. These database objects include types, stored procedures, and functions that are written with managed code. A given application domain contains objects that are all from the same schema. In SQL Server it is possible for an object in one schema to reference an object in another schema. Because objects from different schemas are loaded in separate application domains, a remote call is required for calls between schemas. The less a given application calls objects in different schemas, the better its performance generally is. Internet ExplorerInternet Explorer is the only CLR host I'm aware of that lets the developer programmatically control where the application domain boundaries lie. By default, an application domain is created per site (as in the ASP.NET model). In the vast majority of cases, this default works well in that it gathers all controls from a particular Web site into a single domain. This means that controls that run in the same Internet Explorer process, but that originate from different sites, cannot discover and access each other. However, there are hosting scenarios in which it makes sense to define an application to be at smaller granularity than the entire site. Examples of this scenario include sites that allocate particular subdirectories of pages for individual users or corporations. In these scenarios, code running in a particular subsite must be isolated from code running in the rest of the site. To enable these scenarios, the Internet Explorer host lets the developer specify a directory to serve as the application's root. This directory must be a subdirectory of the site's directory and is specified by using a <link rel=...> tag to identify a configuration file for the Web application. You'll see in Chapter 6 how the creator of an application domain can set a property defining the base directory corresponding to that domain. When processing pages from the site, the Internet Explorer host loads all controls from pages that point to the same configuration file in the same application domain. In this way, the Internet Explorer host enables a developer to specify an isolation boundary at a level of granularity finer than a site. A full description of how to use the <link rel= ...> tag can be found in the .NET Framework SDK. |
|
EAN: N/A
Pages: 119
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability