3.1 Serializing RDF to XML
| Serialization converts an object into a persistent form. The RDF/XML syntax provides a means of documenting an RDF model in a text-based format, literally serializing the model using XML. This means that the content must both meet all requirements for well- formed XML and the additional constraints of RDF. However, before showing you some of these constraints, let's walk through an example of using RDF/XML.
In Chapter 2, I discussed an article I wrote on the giant squid. Now, consider attaching context to it. Among the information that could be exposed about the article is that it explores the idea of the giant squid as a legendary creature from myths and lore; it discusses the current search efforts for the giant squid; and it provides physical characteristics of the creature. Putting this information into a paragraph results in the following: The article on giant squids, titled "Architeuthis Dux," at http://burningbird.net/articles/monsters3.htm, written by Shelley Powers, explores the giant's squid's mythological representation as the legendary Kraken as well as describing current efforts to capture images of a live specimen. In addition, the article also provides descriptions of a giant squid's physical characteristics. It is part of a four-part series, described at http://burningbird.net/articles/monsters.htm and entitled "A Tale of Two Monsters." Reinterpreting this information into a set of statements, each with a specific predicate (property or fact) and its associated value, I come up with the following list:
Starting small, we'll take a look at mapping the article and the author and title, only, into RDF. Example 3-1 shows this RDF mapping, wrapped completely within an XML document. Example 3-1. Preliminary RDF of giant squid article<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author>Shelley Powers</pstcn:author> <pstcn:title>Architeuthis Dux</pstcn:title> </rdf:Description> </rdf:RDF> Tracing the XML from the top, the first line is the traditional XML declaration line. Following it is the RDF element, rdf:RDF , used to enclose the RDF-based content.
Contained as attributes within the RDF element is a listing of the namespaces that identify the vocabulary for each RDF element. The first, with an rdf prefix, is the namespace for the RDF syntax; the second, with a prefix of pstcn , identifies elements I've created for the example RDF in this book. The namespace references an existing schema definition (see more on RDF Schemas in Chapter 5), but the schema itself doesn't have to exist on the Web, because it's not used for validation. However, as you will see in Chapter 5, there is good reason to physically create the RDF Schema document in the location given in the namespace URI. In the example, after the enclosing rdf:RDF element is the RDF Description . An RDF Description begins with the opening RDF Description tag, rdf:Description , which in this case includes an attribute ( rdf:about ) used to identify the resource (the subject). The resource used within the specific element could be an identifier to a resource defined elsewhere in the document or the URI for the subject itself. In the example, the resource identifier is the URI for the giant squid article page. The RDF Description wraps one or more resource predicate/object pairs. The predicate objects (the values) can be either literals or references to another resource. Regardless of object type, each RDF statement is a complete triple consisting of subject-predicate-object. Figure 3-1 shows the relationship between the RDF syntax and the RDF trio from the example. Figure 3-1. An example of two RDF statements, each with the same subject (resource), as well as a mapping between statement elements and values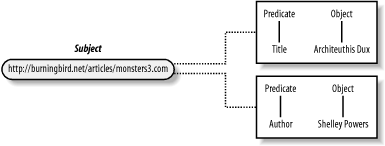 As you can see, a complete RDF statement consists of the resource, a predicate, and its value. In addition, as the figure shows, resources can be described by more than one property (in RDF parlance, the subject can participate in more than one RDF statement within the document). Running Example 3-1 through the RDF Validator results in a listing of N-Triples in the form of subject, predicate, and object: <http://dynamicearth.com/articles/monsters3.htm> <http://burningbird.net/postcon/elements/1.0/author> "Shelley Powers" . <http://dynamicearth.com/articles/monsters3.htm> <http://burningbird.net/postcon/elements/1.0/title> "Architeuthis Dux" . The N-Triples representation of each RDF statement shows the formal identification of each predicate, as it would be identified within the namespace schema. The validator also provides a graphic representation of the statement as shown in Figure 3-2. As you can see, the representation matches that shown in Figure 3-1 ”offering validation that the model syntax used does provide a correct representation of the statements being modeled . Figure 3-2. RDF Validator-generated directed graph of Example 3-1 In Example 3-1, the objects are literal values. However, there is another resource described in the original paragraph in addition to the article itself: the series the article is a part of, represented with the URI http://burningbird.net/articles/monsters.htm . The series then becomes a new resource in the model but is still referenced as a property within the original article description. To demonstrate this, in Example 3-2 the RDF has been expanded to include the information about the series, as well as to include the additional article predicate/object pairs. The modifications to the original RDF/XML are boldfaced. Example 3-2. Expanded version of the giant squid RDF<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author>Shelley Powers</pstcn:author> <pstcn:title>Architeuthis Dux</pstcn:title> <pstcn:series rdf:resource="http://burningbird.net/articles/monsters.htm" /> <pstcn:contains>Physical description of giant squids</pstcn:contains> <pstcn:alsoContains>Tale of the Legendary Kraken</pstcn:alsoContains> </rdf:Description> <rdf:Description rdf:about="http://burningbird.net/articles/monsters.htm"> <pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle> </rdf:Description> </rdf:RDF> The rdf:resource attribute within the pstcn:series predicate references a resource object, in this case one that's defined later in the document and which has a predicate of its own, pstcn:seriesTitle . Though the statements for the linked resource are separate from the enclosed statements in the original resource within the RDF/XML, the RDF graph that's generated in Figure 3-3 shows the linkage between the two. Figure 3-3. Using rdf:resource to set an object to another resource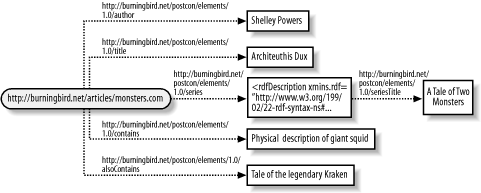 The linked resource could be nested directly within the original resource by enclosing it within the original resource's rdf :Description element, in effect nesting it within the original resource description. Example 3-3 shows the syntax for the example after this modification has been applied. As you can see with this XML, the second resource being referenced within the original is more apparent using this approach, though the two result in equivalent RDF models. Example 3-3. Expanded RDF modified to use nested resources<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author>Shelley Powers</pstcn:author> <pstcn:title>Architeuthis Dux</pstcn:title> <pstcn:series> <rdf:Description rdf:about= "http://burningbird.net/articles/monsters.htm"> <pstcn:SeriesTitle>A Tale of Two Monsters</pstcn:SeriesTitle> </rdf:Description> </pstcn:series> <pstcn:contains>Physical description of giant squids</pstcn:contains> <pstcn:alsoContains>Tale of the Legendary Kraken</pstcn:alsoContains> </rdf:Description> </rdf:RDF> Though nesting one resource description in another shows the connection between the two more clearly, I prefer keeping them apart ”it allows for cleaner RDF documents in my opinion. If nesting becomes fairly extreme ”a resource is an object of another resource, which is an object of another resource, and so on ”trying to represent all of the resources in a nested manner soon becomes unreadable (though automated processes have no problems with it). Example 3-3 demonstrates a fundamental behavior with RDF/XML: subjects and predicates occur in layers , with subjects separated from other subjects by predicates and predicates separated from other predicates by subjects. Subjects are never nested directly within subjects, and predicates are never nested directly within predicates. This RDF/XML striping is discussed next . 3.1.1 Striped SyntaxIn a document titled "RDF: Understanding the Striped RDF/XML Syntax" (found at http://www.w3.org/2001/10/ stripes /), the author, Dan Brickley, talks about a specific pattern of node-edge-node that forms a striping pattern within RDF/XML. This concept has been included in the newer Syntax document as a method of making RDF/XML a little easier to read and understand. If you look at Figure 3-3, you can see this in the thread that extends from the subject ( http://burningbird.net/articles/monsters3.htm ) to the predicate ( pstcn:series ) to the object, which is also a resource ( http://burningbird.net/articles/monsters.htm ) to another predicate ( pstcn:seriesTitle ) to another object, a literal in this case ( A Tale of Two Monsters ). In this thread, no two predicates are nested directly within each other. Additionally, all nodes (subject or object) are separated by an arc ”a predicate ”providing a node-arc-node-arc-node... pattern. Within RDF/XML this becomes particularly apparent when you highlight the predicates and their associated objects within the XML. Example 3-3 is replicated in Example 3-4, except this time the predicate/objects are boldfaced to make them stand out. Example 3-4. Expanded RDF modified to use nested resources, predicates bolded to make them stand out<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author>Shelley Powers</pstcn:author> <pstcn:title>Architeuthis Dux</pstcn:title> <pstcn:series> <rdf:Description rdf:about= "http://dynamicearth.com/articles/monsters.htm"> <pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle> </rdf:Description> </pstcn:series> <pstcn:contains>Physical description of giant squids</pstcn:contains> <pstcn:alsoContains>Tale of the Legendary Kraken</pstcn:alsoContains> </rdf:Description> </rdf:RDF> Viewed in this manner, you can see the striping effect, whereby each predicate is separated by a resource, each resource by a predicate. This maps to the node-arc-node pattern established in the abstract RDF model based on directed graphs. This visualization clue can help you read RDF/XML more easily and allow you to differentiate between predicates and resources.
3.1.2 PredicatesAs you've seen in the examples, a predicate value (object) can be either a resource or a literal. If the object is a resource, an oval is drawn around it; otherwise , a rectangle is drawn. RDF parsers (and the RDF Validator) know which is which by the context of the object itself. However, there is a way that you can specifically mark the type of property ”using the rdf:parseType attribute. By default, all literals are plain literals and can be strings, integers, and so on. Their format would be the string value plus an optional xml:language . However, you can also embed XML within an RDF document by using the rdf:parseType attribute set to a value of "Literal" . For instance, Example 3-5 shows the RDF/XML from Example 3-4, but in this case the pstcn:alsoContains predicate has an XML-formatted value. Example 3-5. RDF/XML demonstrating use of rdf:parseType <?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author>Shelley Powers</pstcn:author> <pstcn:title>Architeuthis Dux</pstcn:title> <pstcn:series> <rdf:Description rdf:about= "http://dynamicearth.com/articles/monsters.htm"> <pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle> </rdf:Description> </pstcn:series> <pstcn:contains>Physical description of giant squids</pstcn:contains> <pstcn:alsoContains rdf:parseType="Literal" > <h1>Tale of the Legendary Kraken </h1></pstcn:alsoContains> </rdf:Description> </rdf:RDF> Without the rdf:parseType="Literal" attribute, the RDF/XML wouldn't be valid. Running the text through the RDF Validator results in the following error: Error: {E202} Expected whitespace found: 'Tale of the Legendary Kraken'.[Line = 17, Column = 69 Specifically, rdf:parseType="Literal" is a way of embedding XML directly into an RDF/XML document. When used, RDF processors won't try to parse the element for additional RDF/XML when it sees the XML tags. If you used rdf:parseType="Literal" with series , itself, the RDF parser would place the literal value of the rdf:Description block within a rectangle, rather than parse it out. You'd get a model similar to that shown in Figure 3-4 Figure 3-4. Using rdf:parseType of "Literal" for a property surrounding an RDF:Description block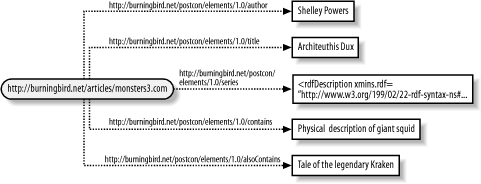 Another rdf:parseType option, "Resource" , identifies the element as a resource without having to use rdf:about or rdf:ID. In other words, the surrounding rdf:Description tags would not be necessary: <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:series rdf:parseType=" Resource "> <pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle> </pstcn:series> ... </rdf:Description> The RDF/XML validates , and the RDF Validator creates an oval for the property. However, it would add a generated identifier in the oval, because the resource is a blank node. There is no place to add a URI for the object in the bubble, because there is no resource identifier for the series property. You can list the seriesTitle directly within the series property, and the property would be attached to it in the RDF graph. But there would be no way to attach a URI to the resource ”it would remain as a blank node. The rdf:parseType property can be used to mark a property as "Resource" , even if there is no property value given yet. For instance, in Example 3-6, the property is marked as "Resource" , but no value is given. Example 3-6. RDF/XML demonstrating use of rdf:parseType<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author rdf:parseType="Resource" /> </rdf:Description> </rdf:RDF> This approach can be used to signify that the object value isn't known but is nonetheless a valid property. Within the RDF directed graph resulting from this RDF/XML, an oval with a generated identifier is drawn to represent the object , as shown in Figure 3-5. Figure 3-5. RDF directed graph of model containing "Resource" object with no value provided3.1.3 Namespaces and QNamesAn important goal of RDF is to record knowledge in machine-understandable format and then provide mechanisms to facilitate the combination of the data. By allowing combinations of multiple models, additions can be incorporated without necessarily impacting an existing RDF Schema. To ensure that RDF/XML data from different documents and different specifications can be successfully merged, namespace support has been added to the specification to prevent element collision. (Element collision occurs when an element with the same name is identified in two different schemas used within the same document.)
To add namespace support to an RDF/XML document, a namespace attribute can be added anywhere in the document; it is usually added to the RDF tag itself, if one is used. An example of this would be: <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"> In this XML, two namespaces are declared ”the RDF/XML syntax namespace (a requirement) and the namespace for the PostCon vocabulary. The format of namespace declarations in RDF/XML usually uses the following format: xmlns:name=" URI of schema " The name doesn't have to be provided if the namespace is assumed to be the default (no prefix is used) within the document: xmlns=" URI of schema " The namespace declaration for RDF vocabularies usually points to the URI of the RDF Schema document for the vocabulary. Though there is no formalized checking of this document involved in RDF/XML ”it's not a DTD ”the document should exist as documentation for the schema. In particular, as we'll see in later chapters, this schema is accessed directly by tools and utilities used to explore and view RDF/XML documents. An element that has been known to generate a great deal of conversation within the RDF/XML and XML community is the QName ”a namespace prefix followed by a colon ( : ) followed by an XML local name. In the examples shown so far, all element and attribute names have been identified using the QName, a requirement within RDF/XML. An example use of a QName is: <rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"> <pstcn:author rdf:parseType="Literal" /> </rdf:Description> In this example, the QName for the RDF Description class and the about and rdf:parseType attributes is rdf , a prefix for the RDF syntax URI, given earlier. The QName for the author element is pstcn , the PostCon URI prefix. The actual prefix used, such as rdf and pstcn , can vary between documents, primarily because automated processes replace the prefix with the full namespace URI when processing the RDF data. However, by convention, the creators of a vocabulary usually set the particular prefix used, and users of the vocabulary are encouraged to use the same prefix for consistency. This makes the RDF/XML documents easier for humans to read. In particular, the prefix for the RDF Syntax Schema is usually given as rdf , the RDF Schema is given as rdfs , and the Dublin Core schema (described in Chapter 6) is usually abbreviated as dc . And of course, PostCon is given as pstcn . Earlier I mentioned that the QName is controversial . The reason is twofold: First, the RDF specification requires that all element and attribute types in RDF/XML must be QNames. Though the reason for this is straightforward ”allowing multiple schemas in the same document ”the rule was not established with the very first releases of RDF/XML, and there is RDF/XML in use today, such as in Mozilla, (described in Chapter 14), in which attributes such as about are not decorated with the namespace prefix. In order to ensure that these pre-existing applications don't break, the RDF Working Group has allowed some attributes to be non-namespace annotated. These attributes are:
When encountered , RDF/XML processors are required to expand these attributes by concatenating the RDF namespace to the attribute. Though these nonannotated attributes are allowed for backward compatibility, the WG (and yours truly) strongly recommend that you use QNames with your attributes. In fact, RDF/XML parsers may give a warning (but not an error) when these are used in a document. The only reason I include these nonannotated attributes in the book is so that you'll understand why these still validate when you come upon them in older uses of RDF/XML. Another controversy surrounding QNames is their use as attribute values: specifically, using them as values for rdf:about or rdf:type . Example 3-7 shows an earlier version of the RDF/XML vocabulary used for demonstrations throughout the book and uses a QName for a attribute value. QName formatting is boldfaced in the example. Example 3-7. Demonstrations of QName attribute values<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:bbd="http://www.burningbird.net/schema#"> <rdf:Description rdf:about="http://www.burningbird.net/identifier/tutorials/xul.htm"> <bbd:bio rdf:resource=" bbd:bio "/> <bbd:relevancy rdf:resource=" bbd:relevancy " /> </rdf:Description> <rdf:Description rdf:about=" bbd:bio "> <bbd:Title>YASD Does Mozilla/Navigator 6.0</bbd:Title> <bbd:Description>Demonstrations of using XUL for interface development </bbd:Description> <bbd:CreationDate>May 2000</bbd:CreationDate> <bbd:ContentAuthor>Shelley Powers</bbd:ContentAuthor> <bbd:ContentOwner>Shelley Powers</bbd:ContentOwner> <bbd:CurrentLocation>N/A</bbd:CurrentLocation> </rdf:Description> <rdf:Description rdf:about=" bbd:relevancy "> <bbd:CurrentStatus>Inactive</bbd:CurrentStatus> <bbd:RelevancyExpiration>N/A</bbd:RelevancyExpiration> <bbd:Dependencies>None</bbd:Dependencies> </rdf:Description> </rdf:RDF> Running this example through the RDF Validator results in a perfectly good RDF graph and no errors or warnings. Many tools also have no problems with the odd use of QName. Apply this practice in your RDF/XML vocabulary, though, and you'll receive howls from the RDF community ”this is a bad use of QNames, though not necessarily a specifically stated invalid use of them. The relationship between QNames and URIs is still not completely certain. |
